Обработка данных — это преобразование данных из одной формы в другую, более удобную и желаемую, то есть придание им более осмысленного и информативного характера. С помощью алгоритмов машинного обучения, математического моделирования и статистических знаний весь этот процесс можно автоматизировать. Результатом этого процесса могут быть любые желаемые формы, такие как графики, видео, диаграммы, таблицы, изображения и многое другое, в зависимости от выполняемой задачи и требований машины. Это может показаться простым, но когда речь идёт о таких крупных организациях, как Twitter, Facebook, административных органах, таких как парламент, ЮНЕСКО, и организациях здравоохранения, весь этот процесс должен быть очень структурированным. Итак, выполните следующие действия:
Обработка данных — важнейший этап в процессе машинного обучения (ML), поскольку она подготавливает данные для использования при создании и обучении моделей ML. Цель обработки данных — очистить, преобразовать и подготовить данные в формате, подходящем для моделирования.
Основные этапы, связанные с обработкой данных, обычно включают:
1. Сбор данных — это процесс получения данных из различных источников, таких как датчики, базы данных или другие системы. Данные могут быть структурированными или неструктурированными и могут поступать в различных форматах, таких как текст, изображения или аудио.
2. Предварительная обработка данных. На этом этапе данные очищаются, фильтруются и преобразуются, чтобы их можно было использовать для дальнейшего анализа. Это может включать удаление пропущенных значений, масштабирование или нормализацию данных, а также их преобразование в другой формат.
3. Анализ данных. На этом этапе данные анализируются с помощью различных методов, таких как статистический анализ, алгоритмы машинного обучения или визуализация данных. Цель этого этапа — извлечь из данных полезную информацию или знания.
4. Интерпретация данных. На этом этапе необходимо интерпретировать результаты анализа данных и делать выводы на основе полученной информации. Также может потребоваться представить результаты в понятной и лаконичной форме, например в виде отчётов, информационных панелей или других визуализаций.
5. Хранение данных и управление ими. После обработки и анализа данных их необходимо хранить и управлять ими таким образом, чтобы обеспечить их безопасность и удобный доступ. Это может включать хранение данных в базе данных, облачном хранилище или других системах, а также реализацию стратегий резервного копирования и восстановления для защиты от потери данных.
6. Визуализация данных и составление отчётов. Наконец, результаты анализа данных представляются заинтересованным сторонам в понятном и удобном для использования формате. Это может включать создание визуализаций, отчётов или информационных панелей, которые подчёркивают ключевые выводы и тенденции в данных.
Существует множество инструментов и библиотек для обработки данных в машинном обучении, в том числе pandas для Python и инструмент преобразования и очистки данных в RapidMiner. Выбор инструментов будет зависеть от конкретных требований проекта, в том числе от размера и сложности данных, а также от желаемого результата.
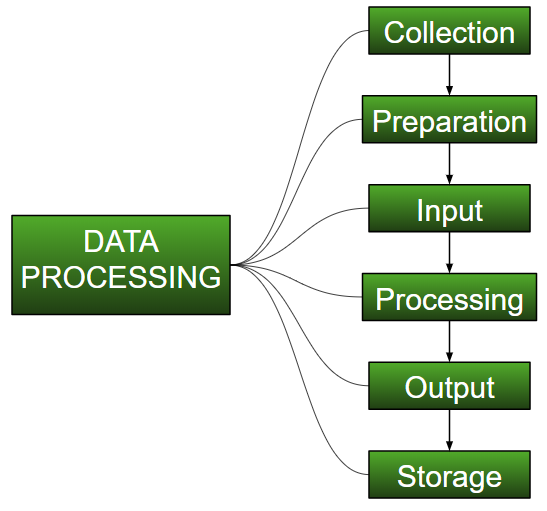
- Коллекция :
Самый важный шаг при начале работы с машинным обучением — это наличие данных хорошего качества и точности. Данные можно собирать из любого проверенного источника, например, с сайта data.gov.in, Kaggle или из репозитория наборов данных UCI. Например, при подготовке к конкурсному экзамену студенты изучают лучшие учебные материалы, к которым у них есть доступ, чтобы получить наилучшие результаты. Точно так же высококачественные и точные данные упростят и улучшат процесс изучения модели, а во время тестирования модель будет выдавать самые современные результаты.
На сбор данных затрачивается огромное количество капитала, времени и ресурсов. Организации или исследователи должны решить, какие данные им нужны для выполнения своих задач или исследований.
Пример: Для работы с распознавателем выражений лица требуется множество изображений, содержащих различные выражения человеческого лица. Качественные данные гарантируют, что результаты модели достоверны и им можно доверять.
- Подготовка :
Собранные данные могут быть в необработанном виде, которые нельзя напрямую отправить на компьютер. Итак, это процесс сбора наборов данных из разных источников, анализа этих наборов данных и последующего создания нового набора данных для дальнейшей обработки и изучения. Эта подготовка может быть выполнена как вручную, так и с помощью автоматического подхода. Данные также могут быть подготовлены в числовой форме, что ускорит обучение модели.
Пример: изображение можно преобразовать в матрицу размером N X N, где значение каждой ячейки будет указывать на пиксель изображения. - Ввод :
Теперь подготовленные данные могут быть представлены в форме, которая не является машиночитаемой, поэтому для преобразования этих данных в машиночитаемую форму необходимы некоторые алгоритмы преобразования. Для выполнения этой задачи требуются высокие вычислительные мощности и точность. Пример: данные могут быть собраны из таких источников, как данные MNIST (изображения), комментарии в Twitter, аудиофайлы, видеоклипы. - Обработка :
На этом этапе требуются алгоритмы и методы машинного обучения, чтобы выполнять инструкции, предоставленные для большого объёма данных, с точностью и оптимальными вычислениями. - Вывод :
На этом этапе машина получает значимые результаты, которые пользователь может легко интерпретировать. Выводы могут быть представлены в виде отчётов, графиков, видео и т. д. - Хранение :
Это заключительный этап, на котором полученные результаты, данные модели и вся полезная информация сохраняются для дальнейшего использования.
Преимущества обработки данных в машинном обучении:
- Повышение производительности модели: обработка данных помогает повысить производительность модели машинного обучения за счёт очистки и преобразования данных в формат, подходящий для моделирования.
- Более точное представление данных: обработка данных позволяет преобразовать их в формат, который лучше отражает взаимосвязи и закономерности в данных, что упрощает обучение модели машинного обучения на этих данных.
- Повышенная точность: обработка данных помогает обеспечить их точность, согласованность и отсутствие ошибок, что может повысить точность модели машинного обучения.
Недостатки обработки данных в машинном обучении:
- Занимает много времени: обработка данных может занимать много времени, особенно для больших и сложных наборов данных.
- Склонность к ошибкам: обработка данных может быть подвержена ошибкам, поскольку она включает в себя преобразование и очистку данных, что может привести к потере важной информации или появлению новых ошибок.
- Ограниченное понимание данных: обработка данных может привести к ограниченному пониманию данных, поскольку преобразованные данные могут не отражать основные взаимосвязи и закономерности в данных.
Справочники:
- «Наука о данных с нуля: основы Python» Джоэла Груса.
- “Подготовка данных для интеллектуального анализа данных” Дориана Пайла.
- «Работа с данными на Python» Жаклин Казил и Кэтрин Джармул.