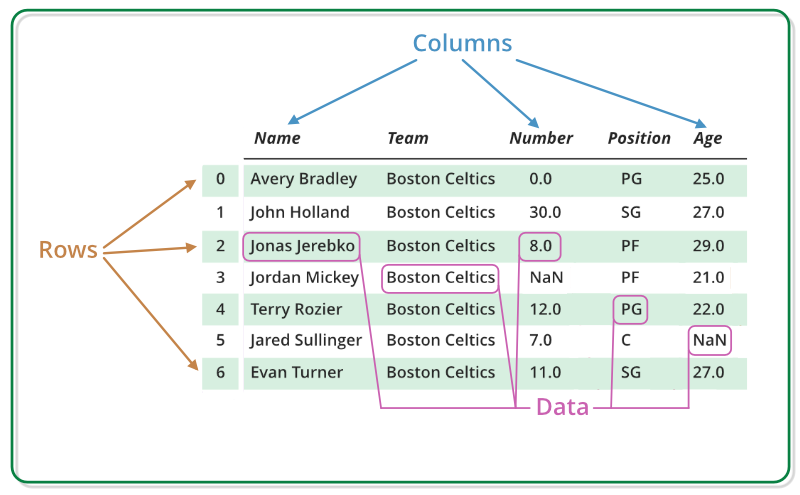
Pandas DataFrame — это двумерная изменяемая по размеру, потенциально неоднородная табличная структура данных с помеченными осями (строками и столбцами). Фрейм данных — это двумерная структура данных, то есть данные расположены в виде таблицы по строкам и столбцам. Pandas DataFrame состоит из трёх основных компонентов: данных, строк и столбцов.
Мы вкратце рассмотрим все эти базовые операции, которые можно выполнять с помощью Pandas DataFrame:
- Создание фрейма данных
- Работа со строками и столбцами
- Индексирование и выбор данных
- Работа с отсутствующими данными
- Перебор строк и столбцов
Создание фрейма данных Pandas
В реальном мире Pandas DataFrame создаётся путём загрузки наборов данных из существующего хранилища. Это может быть база данных SQL, файл CSV или Excel. Pandas DataFrame можно создать из списков, словарей, списков словарей и т. д.Фрейм данных можно создать разными способами. Вот несколько способов создания фрейма данных:
Создание фрейма данных с помощью списка: Фрейм данных можно создать с помощью одного списка или списка списков.
import pandas as pd
lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks']
df = pd.DataFrame(lst)
df
Вывод:

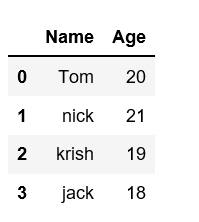
Создание DataFrame из словаря ndarray/списков: Чтобы создать DataFrame из словаря ndarray/списка, все массивы должны быть одинаковой длины. Если передан индекс, то длина индекса должна быть равна длине массивов. Если индекс не передан, то по умолчанию индекс будет равен range(n), где n — длина массива.
import pandas as pd
data = {'Name':['Tom', 'nick', 'krish', 'jack'], 'Age':[20, 21, 19, 18]}
df = pd.DataFrame(data)
df
Вывод:
Для получения более подробной информации обратитесь к Создание фрейма данных Pandas
Работа со строками и столбцами
Фрейм данных — это двумерная структура данных, то есть данные представлены в виде таблицы со строками и столбцами. Мы можем выполнять базовые операции со строками и столбцами, такие как выборка, удаление, добавление и переименование.
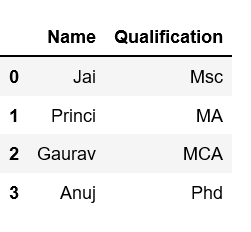
Выбор столбца: Чтобы выбрать столбец в Pandas DataFrame, мы можем получить к нему доступ, назвав его имя.
import pandas as pd
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
df = pd.DataFrame(data)
df[['Name', 'Qualification']]
Вывод:
Выбор строк: Pandas предоставляет уникальный метод для извлечения строк из фрейма данных. DataFrame.loc[] Метод используется для извлечения строк из фрейма данных Pandas. Строки также можно выбрать, передав целочисленное местоположение в функцию iloc[].
Примечание: в приведенных ниже примерах мы будем использовать nba.csv файл.
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
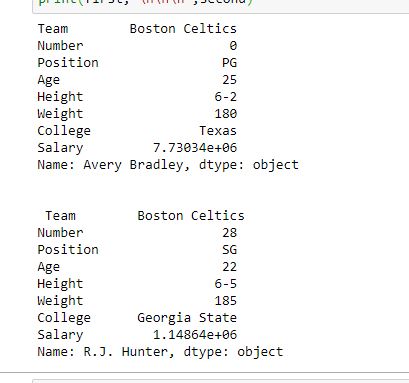
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)
Вывод:
Как показано на выходном изображении, были возвращены две серии, поскольку в обоих случаях был только один параметр.
Индексирование и выбор данных
Индексирование в pandas означает простой выбор определённых строк и столбцов данных из DataFrame. Индексирование может означать выбор всех строк и некоторых столбцов, некоторых строк и всех столбцов или некоторых строк и столбцов. Индексирование также может называться выбором подмножества.
Индексирование фрейма данных с помощью оператора индексации [] :
Оператор индексирования используется для обращения к квадратным скобкам, следующим за объектом. Индексы .loc и .iloc также используют оператор индексирования для выбора. В этом операторе индексирования для обращения к df[].
Выбор отдельных столбцов
Чтобы выбрать один столбец, мы просто вставляем название столбца в скобки
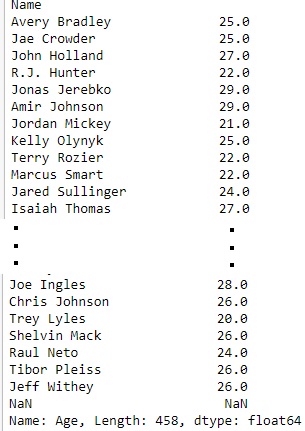
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
first = data["Age"]
print(first)
Вывод:
Индексирование фрейма данных с помощью .loc[ ] :
Эта функция выбирает данные по меткам строк и столбцов. Индексатор df.loc выбирает данные иначе, чем оператор индексации. Он может выбирать подмножества строк или столбцов. Он также может одновременно выбирать подмножества строк и столбцов.
Выбор одной строки
Чтобы выбрать одну строку с помощью .loc[], мы помещаем метку одной строки в .loc функцию.
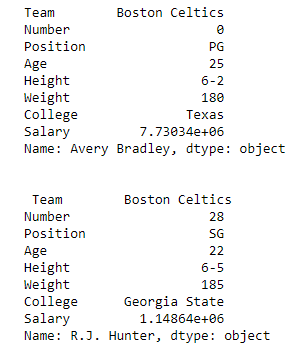
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)
Вывод:
Как показано на выходном изображении, были возвращены две серии, поскольку в обоих случаях был только один параметр.
Индексирование фрейма данных с помощью .iloc[ ] :
Эта функция позволяет нам извлекать строки и столбцы по позициям. Для этого нам нужно указать позиции нужных нам строк и позиции нужных нам столбцов. df.iloc Индексатор очень похож на df.loc , но для выбора использует только целочисленные позиции.
Выбор одной строки
Чтобы выбрать одну строку с помощью .iloc[], мы можем передать одно целое число в .iloc[] функцию.
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
row2 = data.iloc[3]
print(row2)
Вывод:

Работа с отсутствующими данными
Пропущенные данные могут возникать, когда отсутствует информация по одному или нескольким элементам или по всему объекту. Пропущенные данные — очень серьёзная проблема в реальных условиях. Пропущенные данные также могут обозначаться как NA (недоступно) в pandas.
Проверка пропущенных значений с помощью isnull() и notnull() :
Чтобы проверить наличие пропущенных значений в Pandas DataFrame, мы используем функции isnull() и notnull(). Обе функции помогают проверить, является ли значение NaN или нет. Эти функции также можно использовать в Pandas Series для поиска нулевых значений в серии.
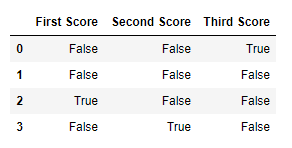
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.isnull()
Вывод:
Заполнение недостающих значений с помощью fillna(), replace() и interpolate() :
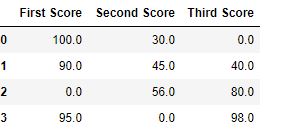
Чтобы заполнить нулевые значения в наборах данных, мы используем fillna(), replace() и interpolate() функции. Эти функции заменяют значения NaN на какое-то собственное значение. Все эти функции помогают заполнить нулевые значения в наборах данных фрейма данных. Функция Interpolate() в основном используется для заполнения NA значений в фрейме данных, но она использует различные методы интерполяции для заполнения пропущенных значений, а не жёстко задаёт значение.
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(0)
Вывод:
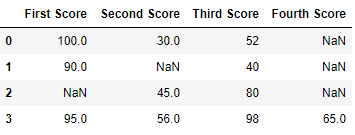
Удаление недостающих значений с помощью dropna() :
Чтобы удалить нулевые значения из фрейма данных, мы использовали dropna() функцию, которая удаляет строки/столбцы наборов данных с нулевыми значениями различными способами.
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df
Вывод:
Теперь мы удаляем строки, содержащие хотя бы одно значение Nan (нулевое значение).
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna()
Вывод:

Перебор строк и столбцов
Итерация — это общий термин, обозначающий последовательное выполнение действий с каждым элементом чего-либо. Фрейм данных Pandas состоит из строк и столбцов, поэтому для итерации по фрейму данных мы должны перебирать его как словарь.
Перебор строк :
Чтобы перебирать строки, мы можем использовать три функции: iteritems(), iterrows(), itertuples() . Эти три функции помогут перебирать строки.
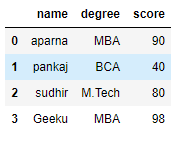
import pandas as pd
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict)
df
Вывод:
Теперь мы применяем iterrows() функцию, чтобы получить каждый элемент строк.
import pandas as pd
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict)
for i, j in df.iterrows():
print(i, j)
print()
Вывод:

Перебор столбцов :
Чтобы перебрать столбцы, нам нужно создать список столбцов фрейма данных, а затем перебрать этот список, чтобы извлечь столбцы фрейма данных.
import pandas as pd
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict)
df
Вывод:
Теперь мы перебираем столбцы. Чтобы перебрать столбцы, сначала создадим список столбцов фрейма данных, а затем переберём этот список.
columns = list(df)
for i in columns:
print (df[i][2])
Вывод:
