Очистка данных — одна из важных составляющих машинного обучения. Она играет значительную роль в построении модели. В этой статье мы рассмотрим очистку данных, её значение и реализацию на Python.
Что такое очистка данных?
Очистка данных является важным этапом в конвейере машинного обучения (ML), поскольку она включает в себя выявление и удаление любых отсутствующих, дублирующихся или нерелевантных данных. Целью очистки данных является обеспечение точности, согласованности и отсутствия ошибок, поскольку неправильные или противоречивые данные могут негативно повлиять на производительность модели машинного обучения. Профессиональные специалисты по обработке данных обычно тратят очень много времени на этот этап, поскольку считают, что «более качественные данные превосходят более сложные алгоритмы».
Очистка данных, также известная как очистка и подготовка данных или предварительная обработка данных, является важным этапом в процессе обработки данных, который включает в себя выявление и исправление или удаление ошибок, несоответствий и неточностей в данных для повышения их качества и удобства использования. Очистка данных необходима, поскольку необработанные данные часто бывают зашумлёнными, неполными и противоречивыми, что может негативно сказаться на точности и надёжности выводов, полученных на их основе.
Почему важна очистка данных?
Очистка данных — важнейший этап в процессе подготовки данных, играющий важную роль в обеспечении точности, надёжности и общего качества набора данных.
При принятии решений достоверность сделанных выводов в значительной степени зависит от чистоты исходных данных. Без надлежащей очистки данных неточности, выбросы, пропущенные значения и несоответствия могут поставить под угрозу достоверность результатов анализа. Более того, очистка данных способствует более эффективному моделированию и распознаванию образов, поскольку алгоритмы работают оптимально при вводе высококачественных данных без ошибок.
Кроме того, чистые наборы данных повышают интерпретируемость результатов, помогая формулировать практические выводы.
Очистка данных в науке о данных
Очистка данных — неотъемлемая часть науки о данных, играющая фундаментальную роль в обеспечении точности и надёжности наборов данных. В области науки о данных, где выводы и прогнозы делаются на основе обширных и сложных наборов данных, качество входных данных существенно влияет на достоверность аналитических результатов. Очистка данных включает в себя систематическое выявление и исправление ошибок, несоответствий и неточностей в наборе данных и включает в себя такие задачи, как обработка пропущенных значений, удаление дубликатов и выявление выбросов. Этот тщательный процесс необходим для повышения достоверности анализа, содействия более точному моделированию и, в конечном счёте, для принятия обоснованных решений на основе достоверных и высококачественных данных.
Шаги по очистке данных
Очистка данных — это систематический процесс выявления и исправления ошибок, несоответствий и неточностей в наборе данных. Ниже приведены основные этапы очистки данных.
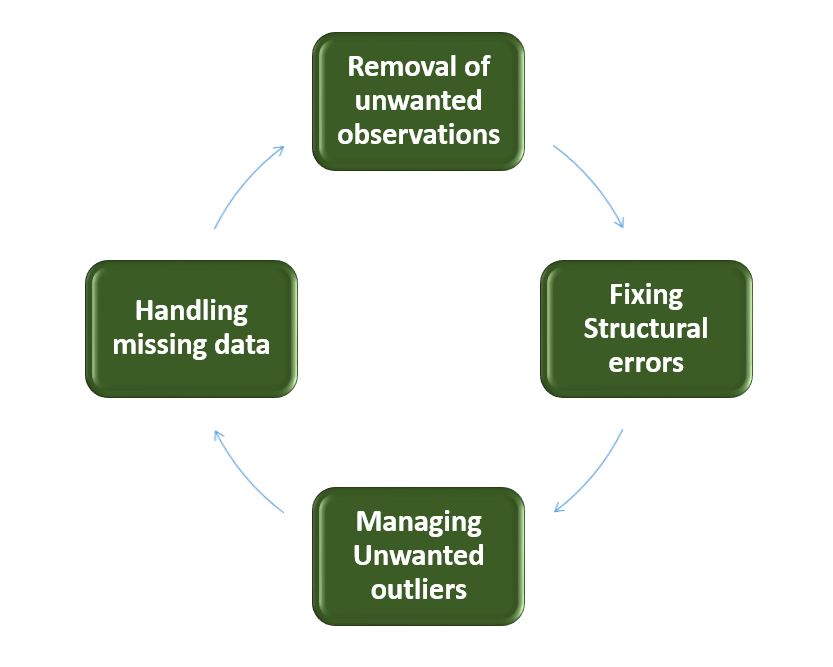
Очистка данных
- Удаление нежелательных наблюдений: выявление и удаление нерелевантных или избыточных наблюдений из набора данных. Этот этап включает в себя проверку записей данных на наличие дубликатов, нерелевантной информации или точек данных, которые не вносят значимого вклада в анализ. Удаление нежелательных наблюдений упрощает набор данных, уменьшая количество шума и повышая общее качество.
- Исправление структурных ошибок: устранение структурных проблем в наборе данных, таких как несоответствия в форматах данных, соглашениях об именовании или типах переменных. Стандартизируйте форматы, устраняйте несоответствия в именовании и обеспечивайте единообразие в представлении данных. Исправление структурных ошибок повышает согласованность данных и облегчает их точный анализ и интерпретацию.
- Управление нежелательными выбросами: выявляйте выбросы и управляйте ими, то есть точками данных, значительно отличающимися от нормы. В зависимости от контекста решите, удалять ли выбросы или преобразовывать их, чтобы минимизировать их влияние на анализ. Управление выбросами имеет решающее значение для получения более точных и надёжных результатов анализа данных.
- Обработка отсутствующих данных: Разработайте стратегии для эффективной обработки отсутствующих данных. Это может включать в себя вменение отсутствующих значений на основе статистических методов, удаление записей с отсутствующими значениями или использование передовых методов вменения. Обработка отсутствующих данных обеспечивает более полный набор данных, предотвращая искажения и сохраняя целостность анализа.
Как выполнить очистку данных
Выполнение очистки данных предполагает системный подход к повышению качества и надежности набора данных. Процесс начинается с тщательного понимания данных, проверки их структуры и выявления проблем, таких как пропущенные значения, дубликаты и выбросы. Устранение недостающих данных требует стратегических решений по условному исчислению или удалению, в то время как дубликаты систематически устраняются для уменьшения избыточности. Управление выбросами гарантирует, что экстремальные значения не окажут чрезмерного влияния на анализ. Структурные ошибки исправлены для стандартизации форматов и типов переменных, что способствует согласованности.
На протяжении всего процесса документирование изменений имеет решающее значение для прозрачности и воспроизводимости. Итеративная проверка и тестирование подтверждают эффективность этапов очистки данных, что в конечном итоге приводит к получению уточненного набора данных, готового к содержательному анализу и выводам.
Реализация Python для очистки базы данных
Давайте рассмотрим каждый этап очистки базы данных на примере набора данных Titanic. Ниже приведены необходимые шаги:
- Импортируйте необходимые библиотеки
- Загрузить набор данных
- Проверьте информацию о данных с помощью df.info ()
import pandas as pd
import numpy as np
df = pd.read_csv('titanic.csv')
df.head()
Результат:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
Проверка и исследование данных
Давайте сначала проанализируем данные, изучив их структуру и выявив пропущенные значения, выбросы и несоответствия, а также проверим повторяющиеся строки с помощью приведенного ниже кода на Python:
df.duplicated()Результат:
0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Length: 891, dtype: bool
Проверьте информацию о данных с помощью df.info()
df.info()Результат:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
Из приведённых выше данных мы видим, что возраст и номер каюты имеют разное количество значений. Некоторые столбцы являются категориальными и содержат объекты, а некоторые — целочисленные и числовые значения.
Проверьте столбцы категорий и цифр.
cat_col = [col for col in df.columns if df[col].dtype == 'object']
print('Categorical columns :',cat_col)
num_col = [col for col in df.columns if df[col].dtype != 'object']
print('Numerical columns :',num_col)
Результат:
Categorical columns : ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']
Numerical columns : ['PassengerId', 'Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare']
Проверьте общее количество уникальных значений в столбцах категорий
df[cat_col].nunique()Результат:
Name 891
Sex 2
Ticket 681
Cabin 147
Embarked 3
dtype: int64
Шаги по выполнению очистки данных
Удаление всех вышеперечисленных нежелательных наблюдений
Это включает в себя удаление дублирующихся/избыточных или нерелевантных значений из вашего набора данных. Дублирующиеся наблюдения чаще всего возникают во время сбора данных, а нерелевантные наблюдения — это те, которые на самом деле не соответствуют конкретной проблеме, которую вы пытаетесь решить.
- Избыточные наблюдения в значительной степени снижают эффективность, поскольку данные повторяются и могут быть как в пользу правильной, так и в пользу неправильной стороны, тем самым выдавая недостоверные результаты.
- Ненужные наблюдения — это любые данные, которые не представляют для нас никакой пользы и могут быть удалены напрямую.
Теперь нам нужно принять решение в соответствии с предметом анализа, который является важным фактором для нашего обсуждения.
Как мы знаем, наши машины не понимают текстовые данные. Поэтому нам нужно либо удалить, либо преобразовать значения категориальных столбцов в числовые типы. Здесь мы удаляем столбцы с именами, потому что имя всегда будет уникальным и не оказывает большого влияния на целевые переменные. Для билета давайте сначала выведем 50 уникальных билетов.
df['Ticket'].unique()[:50]
Результат:
array(['A/5 21171', 'PC 17599', 'STON/O2. 3101282', '113803', '373450',
'330877', '17463', '349909', '347742', '237736', 'PP 9549',
'113783', 'A/5. 2151', '347082', '350406', '248706', '382652',
'244373', '345763', '2649', '239865', '248698', '330923', '113788',
'347077', '2631', '19950', '330959', '349216', 'PC 17601',
'PC 17569', '335677', 'C.A. 24579', 'PC 17604', '113789', '2677',
'A./5. 2152', '345764', '2651', '7546', '11668', '349253',
'SC/Paris 2123', '330958', 'S.C./A.4. 23567', '370371', '14311',
'2662', '349237', '3101295'], dtype=object)
Из приведенных выше примеров мы видим, что они состоят из двух похожих значений: «A/5 21171» состоит из «A/5» и «21171», что может повлиять на наши целевые переменные. Это будет случай разработки функций. где мы получаем новые функции из столбца или группы столбцов. В данном случае мы удаляем столбцы «Имя» и «Номер».
Укажите имя пользователя и столбцы для тикетов
df1 = df.drop(columns=['Name','Ticket'])
df1.shape
Результат:
(891, 10)
Обработка недостающих данных
Отсутствующие данные — распространённая проблема в реальных наборах данных, которая может возникать по разным причинам, таким как ошибки человека, системные сбои или проблемы со сбором данных. Для обработки отсутствующих данных можно использовать различные методы, такие как вменение, удаление или замена.
Давайте проверим % пропущенных значений по столбцам для каждой строки с помощью df.isnull(). Эта функция проверяет, являются ли значения нулевыми, и возвращает логические значения.и .sum() суммируют общее количество строк с нулевыми значениями, и мы делим его на общее количество строк в наборе данных, а затем умножаем, чтобы получить значения в %, то есть сколько значений из 100 являются нулевыми.
round((df1.isnull().sum()/df1.shape[0])*100,2)
Результат:
PassengerId 0.00
Survived 0.00
Pclass 0.00
Sex 0.00
Age 19.87
SibSp 0.00
Parch 0.00
Fare 0.00
Cabin 77.10
Embarked 0.22
dtype: float64
Мы не можем просто проигнорировать или удалить отсутствующие наблюдения. С ними нужно обращаться осторожно, так как они могут указывать на что-то важное.
Два наиболее распространенных способа обработки отсутствующих данных::
- Удаление наблюдений с пропущенными значениями.
- Тот факт, что значение отсутствовало, может быть информативным сам по себе.
- Кроме того, в реальном мире вам часто приходится делать прогнозы на основе новых данных, даже если некоторые характеристики отсутствуют!
Как видно из приведённого выше результата, в столбце «Каюта» 77% нулевых значений, в столбце «Возраст» 19,87%, а в столбце «Отплытие» 0,22% нулевых значений.
Таким образом, не стоит заполнять 77% нулевых значений. Поэтому мы удалим столбец «Каюта». В столбце «Прибытие» только 0,22% нулевых значений, поэтому мы удалим строки с нулевыми значениями в столбце «Прибытие».
df2 = df1.drop(columns='Cabin')
df2.dropna(subset=['Embarked'], axis=0, inplace=True)
df2.shape
Результат:
(889, 9)
- Вычисляем недостающие значения из прошлых наблюдений.
- Опять же, «отсутствие» почти всегда само по себе информативно, и вы должны сообщить своему алгоритму, если значение отсутствует.
- Даже если вы создадите модель для прогнозирования значений, вы не добавите никакой реальной информации. Вы просто усилите закономерности, уже выявленные другими функциями.
Мы можем использовать среднее значение или медианное значение для этого случая.
Примечание:
- Метод среднего значения подходит, когда данные распределены нормально и не содержат экстремальных значений.
- Метод медианного вменения предпочтительнее, когда данные содержат выбросы или искажены.
df3 = df2.fillna(df2.Age.mean())
df3.isnull().sum()
Результат:
PassengerId 0
Survived 0
Pclass 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
Обработка выбросов
Выбросы — это экстремальные значения, которые значительно отличаются от большинства данных. Они могут негативно влиять на анализ и производительность модели. Для обработки выбросов можно использовать такие методы, как кластеризация, интерполяция или преобразование.
Чтобы проверить наличие выбросов, мы обычно используем диаграмму размаха. Диаграмма размаха, также называемая диаграммой «ящик с усами», представляет собой графическое изображение распределения набора данных. Она показывает медиану, квартили и потенциальные выбросы. Линия внутри прямоугольника обозначает медиану, а сам прямоугольник обозначает межквартильный размах (IQR). Усы доходят до самых крайних значений, не являющихся выбросами, в пределах 1,5 IQR. Отдельные точки, выходящие за пределы «усов», считаются потенциальными выбросами. BOXplot диаграмма даёт простое для понимания представление о диапазоне данных и позволяет выявить выбросы или асимметрию в распределении.
Давайте построим прямоугольную диаграмму для данных столбца возраста.
import matplotlib.pyplot as plt
plt.boxplot(df3['Age'], vert=False)
plt.ylabel('Variable')
plt.xlabel('Age')
plt.title('Box Plot')
plt.show()
Результат:
.png)
Блок-схема
Как видно из приведённого выше графика «ящик с усами», в нашем наборе данных о возрасте есть выбросы. Значения меньше 5 и больше 55 являются выбросами.
mean = df3['Age'].mean()
std = df3['Age'].std()
lower_bound = mean - std*2
upper_bound = mean + std*2
print('Lower Bound :',lower_bound)
print('Upper Bound :',upper_bound)
df4 = df3[(df3['Age'] >= lower_bound)
& (df3['Age'] <= upper_bound)]
Результат:
Lower Bound : 3.705400107925648
Upper Bound : 55.578785285332785
Аналогичным образом мы можем удалить выбросы из оставшихся столбцов.
Преобразование данных
Преобразование данных — это перевод данных из одной формы в другую, чтобы сделать их более подходящими для анализа. Для преобразования данных можно использовать такие методы, как нормализация, масштабирование или кодирование.
Проверка достоверности данных
Проверка и подтверждение данных подразумевают обеспечение их точности и согласованности путём сравнения с внешними источниками или экспертными знаниями.
Для прогнозирования с помощью машинного обучения сначала мы разделяем независимые и целевые признаки. Здесь мы будем рассматривать только «пол», «возраст», «наличие братьев и сестер», «наличие родителей», «стоимость проезда», «место посадки»только в качестве независимых признаков и выживших в качестве целевых переменных. Потому что PassengerId не повлияет на уровень выживаемости.
X = df3[['Pclass','Sex','Age', 'SibSp','Parch','Fare','Embarked']]
Y = df3['Survived']
Форматирование данных
Форматирование данных подразумевает преобразование данных в стандартный формат или структуру, которые могут быть легко обработаны алгоритмами или моделями, используемыми для анализа. Здесь мы рассмотрим часто используемые методы форматирования данных, такие как масштабирование и нормализация.
Масштабирование
- Масштабирование предполагает преобразование значений признаков в определённый диапазон. При этом сохраняется форма исходного распределения, но меняется масштаб.
- Особенно полезно, когда признаки имеют разные масштабы, а некоторые алгоритмы чувствительны к величине признаков.
- К распространённым методам масштабирования относятся масштабирование по минимуму и максимуму и стандартизация (масштабирование по Z-оценке).
Масштабирование по минимальному и максимальному значениям: Масштабирование по минимальному и максимальному значениям преобразует значения в заданный диапазон, обычно от 0 до 1. Оно сохраняет исходное распределение и гарантирует, что минимальное значение преобразуется в 0, а максимальное — в 1.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
num_col_ = [col for col in X.columns if X[col].dtype != 'object']
x1 = X
x1[num_col_] = scaler.fit_transform(x1[num_col_])
x1.head()
Результат:
Pclass Sex Age SibSp Parch Fare Embarked
0 1.0 male 0.271174 0.125 0.0 0.014151 S
1 0.0 female 0.472229 0.125 0.0 0.139136 C
2 1.0 female 0.321438 0.000 0.0 0.015469 S
3 0.0 female 0.434531 0.125 0.0 0.103644 S
4 1.0 male 0.434531 0.000 0.0 0.015713 S
Стандартизация (масштабирование по Z-критерию): Стандартизация преобразует значения таким образом, чтобы среднее значение равнялось 0, а стандартное отклонение — 1. Она центрирует данные вокруг среднего значения и масштабирует их на основе стандартного отклонения. Стандартизация делает данные более подходящими для алгоритмов, которые предполагают нормальное распределение или требуют, чтобы признаки имели нулевое среднее значение и единичную дисперсию.
Z = (X - μ) / σ
Где,
- X = Данные
- μ = Среднее значение X
- σ = Стандартное отклонение X
Инструменты для очистки данных
Некоторые инструменты для очистки данных:
- OpenRefine
- Trifacta Wrangler
- TIBCO Clarity
- Cloudingo
- Этап качества IBM Infosphere
Преимущества очистки данных в машинном обучении:
- Повышение производительности модели: устранение ошибок, несоответствий и нерелевантных данных помогает модели лучше обучаться на этих данных.
- Повышенная точность: помогает обеспечить точность, согласованность и отсутствие ошибок в данных.
- Более наглядное представление данных: очистка данных позволяет преобразовать их в формат, который лучше отражает взаимосвязи и закономерности в данных.
- Улучшенное качество данных: повысьте качество данных, сделав их более надёжными и точными.
- Улучшенная защита данных: помогает выявлять и удалять конфиденциальную информацию, которая может поставить под угрозу безопасность данных.
Недостатки очистки данных в машинном обучении
- Занимает много времени: трудоёмкая задача, особенно для больших и сложных наборов данных.
- Склонность к ошибкам: очистка данных может приводить к ошибкам, поскольку она включает в себя преобразование и очистку данных, что может привести к потере важной информации или появлению новых ошибок.
- Затратный и ресурсоёмкий: ресурсоёмкий процесс, требующий значительных затрат времени, усилий и опыта. Он также может потребовать использования специализированных программных инструментов, что может увеличить стоимость и сложность очистки данных.
- Переобучение: очистка данных может непреднамеренно привести к переобучению, если удалить слишком много данных.
Заключение
Итак, мы рассмотрели четыре различных этапа очистки данных, чтобы сделать их более надёжными и получить хорошие результаты. После правильной очистки данных у нас будет надёжный набор данных, в котором не будет многих наиболее распространённых ошибок. Подводя итог, можно сказать, что очистка данных — это важный этап в процессе обработки данных, который включает в себя выявление и исправление ошибок, несоответствий и неточностей в данных для повышения их качества и удобства использования.