Отсутствие данных может возникать, когда не предоставляется информация по одному или нескольким элементам или по целому подразделению. Отсутствие данных является очень большой проблемой в реальных сценариях. Отсутствующие данные также могут относиться к значениям NA (Недоступно) в pandas. В DataFrame иногда многие наборы данных просто поступают с отсутствующими данными, либо потому, что они существуют и не были собраны, либо они никогда не существовали. Например, предположим, что разные опрашиваемые пользователи могут предпочесть не делиться своими доходами, некоторые пользователи могут предпочесть не делиться адресом, таким образом, пропало много наборов данных.

В Pandas отсутствующие данные представлены двумя значениями:
- None: None — это одноэлементный объект Python, который часто используется для обозначения отсутствующих данных в коде Python.
- NaN (сокращение от Not a Number — «не число») — это специальное значение с плавающей запятой, распознаваемое всеми системами, использующими стандартное представление чисел с плавающей запятой IEEE
В Pandas значения None и NaN по сути взаимозаменяемы для обозначения отсутствующих или нулевых значений. Чтобы упростить это соглашение, существует несколько полезных функций для обнаружения, удаления и замены нулевых значений в Pandas DataFrame:
- isnull()
- notnull()
- dropna()
- fillna()
- replace()
- interpolate()
В этой статье мы используем CSV-файл.
Проверка на отсутствие значений с помощью isnull() и notnull()
Чтобы проверить наличие пропущенных значений в Pandas DataFrame, мы используем функции isnull() и notnull(). Обе функции помогают проверить, является ли значение NaN. Эти функции также можно использовать в Pandas Series, чтобы найти пропущенные значения в серии.
Проверка на отсутствие значений с помощью isnull()
Чтобы проверить нулевые значения в Pandas DataFrame, мы используем функцию isnull(). Эта функция возвращает фрейм данных с логическими значениями, которые равны True для значений NaN.
Код # 1:
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.isnull()
Вывод: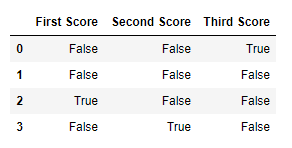
Код # 2:
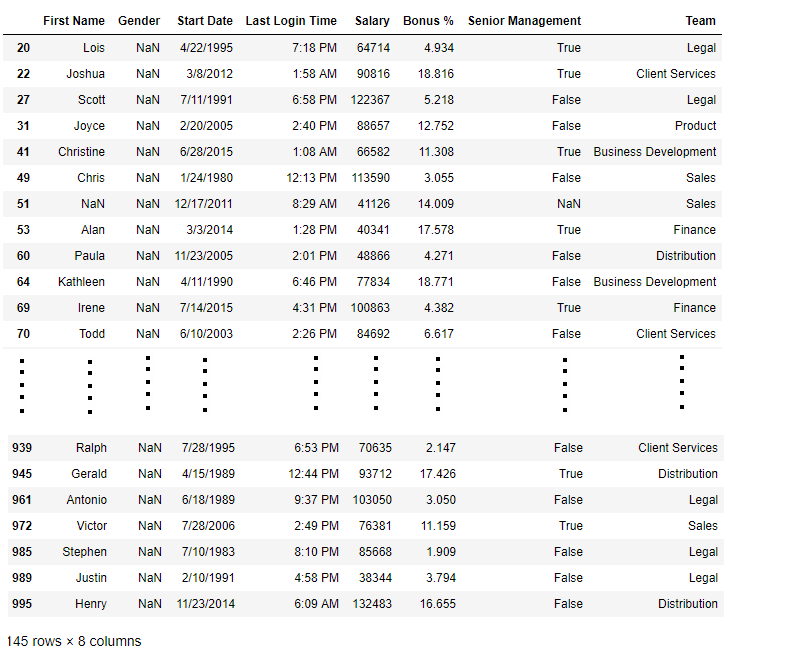
import pandas as pd
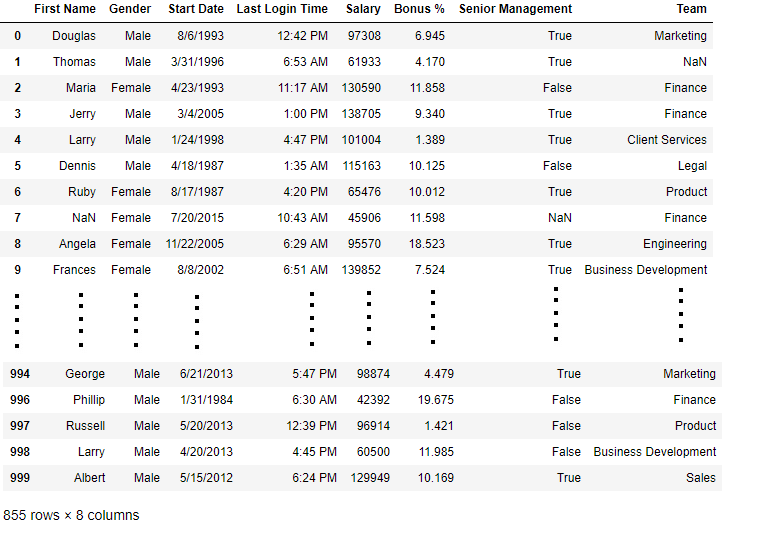
data = pd.read_csv("employees.csv")
bool_series = pd.isnull(data["Gender"])
data[bool_series]
Вывод: Как показано на изображении, отображаются только строки, в которых поле «Пол» равно NULL.
Проверка на отсутствие значений с помощью notnull()
Чтобы проверить нулевые значения в фрейме данных Pandas, мы используем функцию notnull(). Эта функция возвращает фрейм данных с логическими значениями, которые равны False для значений NaN.
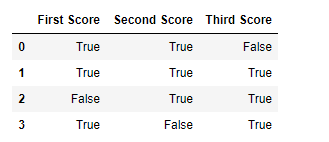
Код # 3:
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.notnull()
Вывод:
Код # 4:
import pandas as pd
data = pd.read_csv("employees.csv")
bool_series = pd.notnull(data["Gender"])
data[bool_series]
Вывод: Как показано на изображении вывода, отображаются только строки, в которых поле «Пол» не равно NULL.
Заполнение отсутствующих значений с помощью fillna(), replace() и interpolate()
Чтобы заполнить нулевые значения в наборах данных, мы используем функции fillna(), replace() и interpolate(). Эти функции заменяют значения NaN на какое-то другое значение. Все эти функции помогают заполнить нулевые значения в наборах данных фрейма данных. Функция interpolate() в основном используется для заполнения значений NA в фрейме данных, но она использует различные методы интерполяции для заполнения пропущенных значений, а не жёстко задаёт значение.
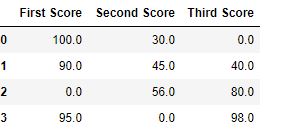
Код №1: Заполнение нулевых значений одним значением
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(0)
Вывод:
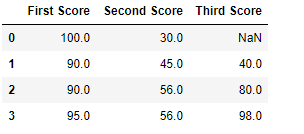
Код №2: Заполнение нулевых значений предыдущими
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(method ='pad')
Вывод:
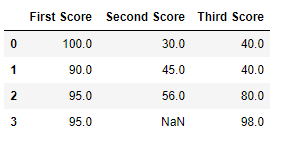
Код # 3:
Заполнение нулевого значения следующими данными
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(method ='bfill')
Вывод:
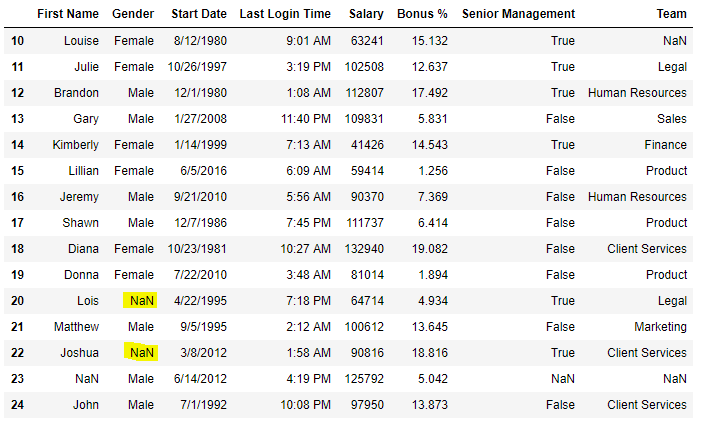
Код №4: Заполнение нулевых значений в CSV-файле
import pandas as pd
data = pd.read_csv('employees.csv')
data[10:25]
Вывод
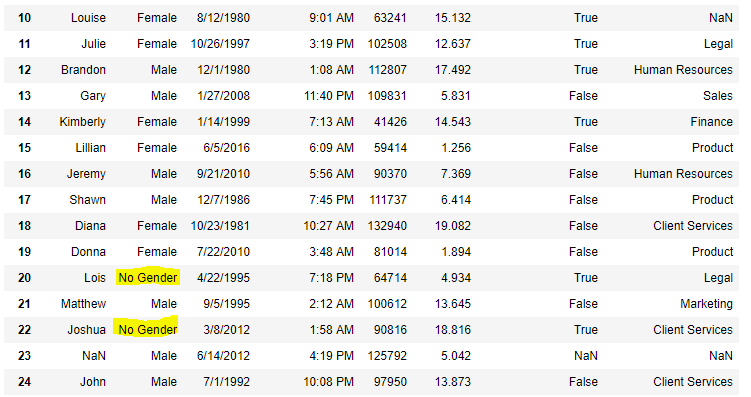
Теперь мы заполним все пустые значения в столбце «Пол» текстом «Без пола»
import pandas as pd
data = pd.read_csv("employees.csv")
data["Gender"].fillna('No Gender', inplace = True)
data
Вывод:
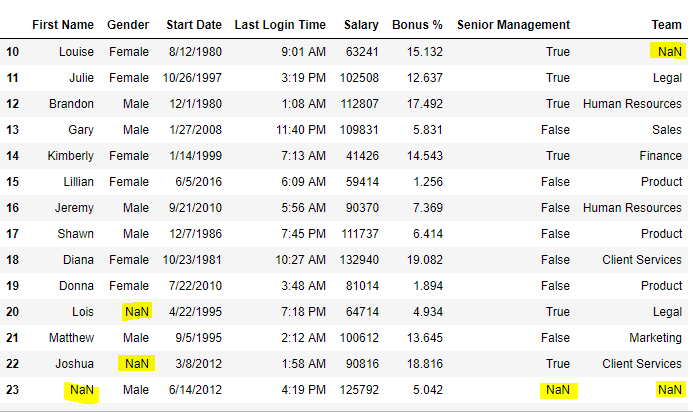
Код № 5: Заполнение нулевых значений с помощью метода replace()
import pandas as pd
data = pd.read_csv('employees')
data[10:25]
Вывод:
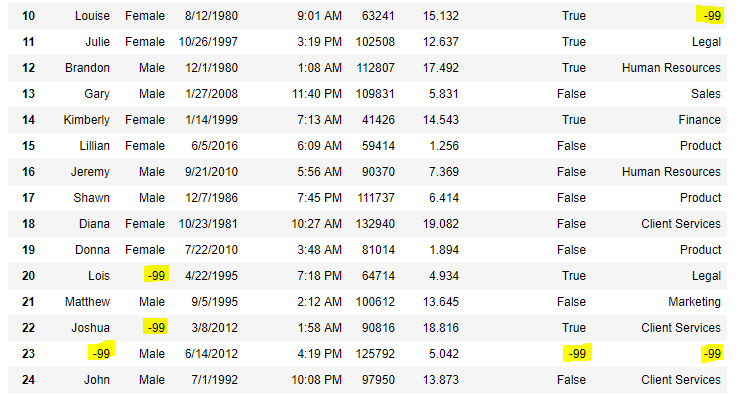
Теперь мы заменим все значения Nan в фрейме данных на значение -99.
import pandas as pd
data = pd.read_csv("employees.csv")
data.replace(to_replace = np.nan, value = -99)
Вывод:
Код № 6: Использование функции interpolate() для заполнения пропущенных значений с помощью линейного метода.
import pandas as pd
df = pd.DataFrame({'A':[12, 4, 5, None, 1],
'B':[None, 2, 54, 3, None],
'C':[20, 16, None, 3, 8],
'D':[14, 3, None, None, 6]})
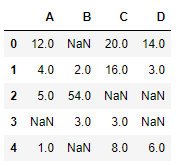
df
Вывод:
Давайте интерполируем недостающие значения с помощью линейного метода. Обратите внимание, что линейный метод игнорирует индекс и рассматривает значения как равномерно распределённые.
df.interpolate(method ='linear', limit_direction ='forward')
Вывод:
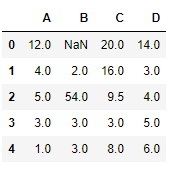
Как видно из результата, значения в первой строке не могли быть заполнены, так как направление заполнения значений идёт вперёд, а предыдущего значения, которое можно было бы использовать для интерполяции, нет.
Удаление отсутствующих значений с помощью dropna()
Чтобы удалить нулевые значения из фрейма данных, мы использовали функцию dropna(). Эта функция удаляет строки/столбцы наборов данных с нулевыми значениями различными способами.
Код № 1: Удаление строк, содержащих хотя бы одно нулевое значение.
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
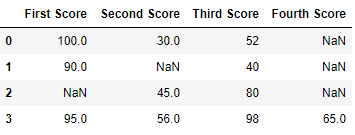
df = pd.DataFrame(dict)
df
Вывод
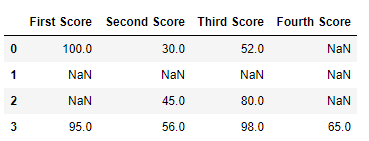
Теперь мы удаляем строки, содержащие хотя бы одно значение Nan (нулевое значение)
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna()
Вывод:
Код № 2: Удаление строк, если все значения в этой строке отсутствуют.
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df
Вывод
Теперь мы удалим строки, в которых все данные отсутствуют или содержат нулевые значения (NaN)
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna(how = 'all')
Вывод:
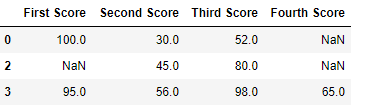
Код # 3:
Удаление столбцов, содержащих как минимум 1 нулевое значение.
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
df = pd.DataFrame(dict)
df
Вывод
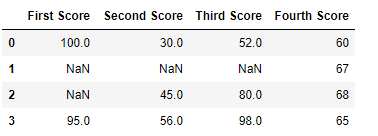
Теперь мы удаляем столбцы, в которых отсутствует как минимум 1 значение
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
df = pd.DataFrame(dict)
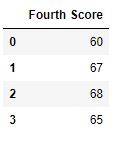
df.dropna(axis = 1)
Вывод :
Код № 4: Удаление строк с хотя бы одним нулевым значением в CSV-файле
import pandas as pd
data = pd.read_csv("employees.csv")
new_data = data.dropna(axis = 0, how ='any')
new_data
Вывод:
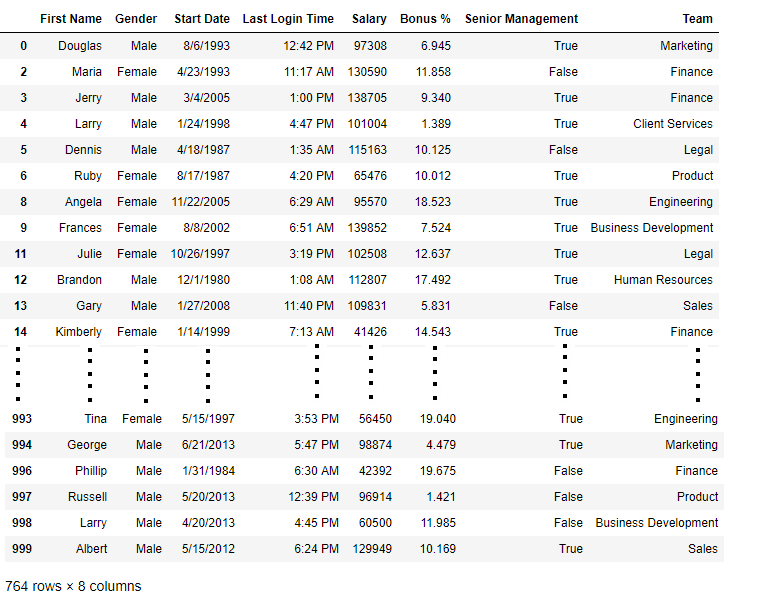
Теперь мы сравниваем размеры фреймов данных, чтобы узнать, в скольких строках есть хотя бы одно нулевое значение
print('Old data frame length:', len(data))
print('New data frame length:', len(new_data))
print('Number of rows with at least 1 NA value: ', (len(data)-len(new_data)))
Вывод :
Old data frame length: 1000
New data frame length: 764
Number of rows with at least 1 NA value: 236
Поскольку разница составляет 236, в 236 строках было хотя бы одно нулевое значение в каком-либо столбце.