В этой статье мы обсудим, как выполнить исследовательский анализ данных на примере набора данных Iris. Прежде чем продолжить чтение этой статьи, мы использовали две терминологии: EDA и набор данных Iris. Давайте вкратце рассмотрим эти наборы данных.
Что такое предварительный анализ данных?
Исследовательский анализ данных (EDA)— это метод анализа данных с использованием некоторых визуальных техник. С помощью этого метода мы можем получить подробную информацию о статистической сводке данных. Мы также сможем работать с дублирующимися значениями, выбросами, а также выявлять тенденции или закономерности, присутствующие в наборе данных.
Теперь давайте кратко рассмотрим набор данных Iris.
Набор данных Iris
Если вы разбираетесь в науке о данных, то, должно быть, знакомы с набором данных Iris. Если нет, то не волнуйтесь, мы обсудим это здесь.
Набор данных Iris считается «Hello World» для науки о данных. Он содержит пять столбцов: длина лепестка, ширина лепестка, длина чашелистика, ширина чашелистика и тип вида. Ирис — это цветущее растение. Исследователи измерили различные характеристики разных цветков ириса и записали их в цифровом виде.
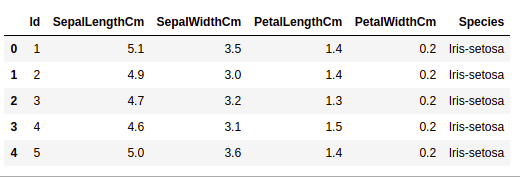
Вы можете скачать файл Iris.csv по ссылке. Теперь мы будем использовать библиотеку Pandas для загрузки этого CSV-файла и преобразуем его в фрейм данных. Метод read_csv() используется для чтения CSV-файлов.
import pandas as pd
# Reading the CSV file
df = pd.read_csv("Iris.csv")
# Printing top 5 rows
df.head()
Вывод:
Получение информации о наборе данных
Мы будем использовать параметр shape, чтобы получить форму набора данных.
Пример:
df.shape
Вывод:
(150, 6)
Мы видим, что фрейм данных содержит 6 столбцов и 150 строк.
Теперь давайте рассмотрим столбцы и их типы данных. Для этого мы воспользуемся методом info().
Пример:
df.info()
Вывод:
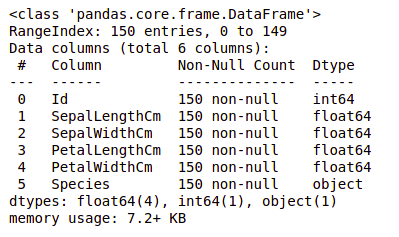
Мы видим, что только в одном столбце есть категориальные данные, а все остальные столбцы имеют числовой тип с ненулевыми значениями.
Давайте получим краткую статистическую сводку по набору данных с помощью метода describe(). Функция describe() применяет к набору данных базовые статистические вычисления, такие как вычисление крайних значений, количества точек данных, стандартного отклонения и т. д. Любое пропущенное значение или значение NaN автоматически пропускается. Функция describe() даёт хорошее представление о распределении данных.
Пример:
df.describe()
Вывод:
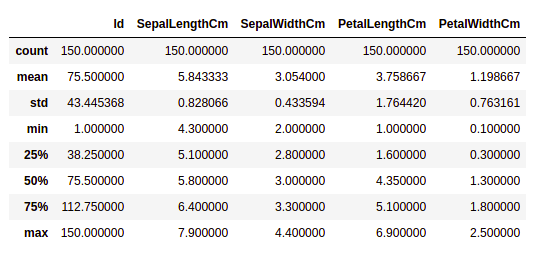
Мы можем увидеть количество значений в каждом столбце, а также их среднее значение, стандартное отклонение, минимальное и максимальное значения.
Проверка пропущенных значений
Мы проверим, есть ли в наших данных пропущенные значения. Пропущенные значения могут возникать, когда для одного или нескольких элементов или для целого блока не указана информация. Мы будем использовать метод isnull().
Пример:
df.isnull().sum()
Вывод:
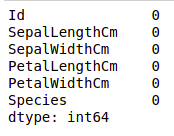
Мы видим, что ни в одном столбце нет пропущенного значения.
Проверка дубликатов
Давайте посмотрим, есть ли в нашем наборе данных дубликаты. Метод Pandas drop_duplicates() помогает удалить дубликаты из фрейма данных.
Пример:
data = df.drop_duplicates(subset ="Species",)
data
Вывод:
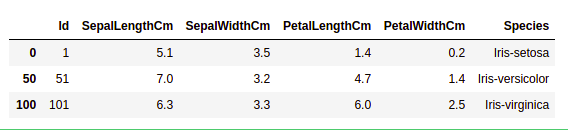
Мы видим, что существует только три уникальных вида. Давайте посмотрим, сбалансирован ли набор данных, то есть все ли виды содержат одинаковое количество строк. Мы будем использовать функцию Series.value_counts(). Эта функция возвращает серию, содержащую количество уникальных значений.
Пример:
df.value_counts("Species")
Вывод:
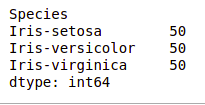
Мы видим, что все виды содержат одинаковое количество строк, поэтому нам не нужно удалять какие-либо записи.
Визуализация данных
Визуализация целевого столбца
Нашим целевым столбцом будет столбец «Вид», потому что в итоге нам понадобится результат только по видам. Давайте посмотрим на диаграмму распределения по видам.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='Species', data=df, )
plt.show()
Вывод:
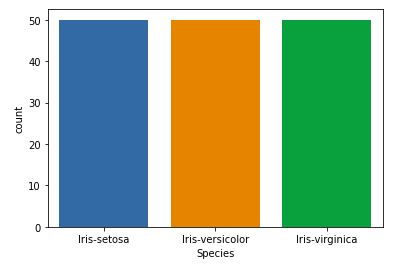
Связь между переменными
Мы рассмотрим соотношение между длиной и шириной чашелистика, а также между длиной и шириной лепестка.
Пример 1: Сравнение длины и ширины чашелистика
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(x='SepalLengthCm', y='SepalWidthCm',
hue='Species', data=df, )
# Placing Legend outside the Figure
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
Вывод:
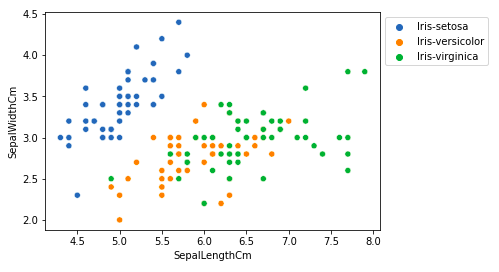
Из приведенного выше графика мы можем сделать вывод, что –
- У вида Setosa длина чашелистиков меньше, но ширина чашелистиков больше.
- Versicolor Species занимает промежуточное положение между двумя другими видами по длине и ширине чашелистика
- У вида Virginica длина чашелистиков больше, но ширина чашелистиков меньше.
Пример 2: Сравнение длины и ширины лепестков
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(x='PetalLengthCm', y='PetalWidthCm',
hue='Species', data=df, )
# Placing Legend outside the Figure
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
Выход:
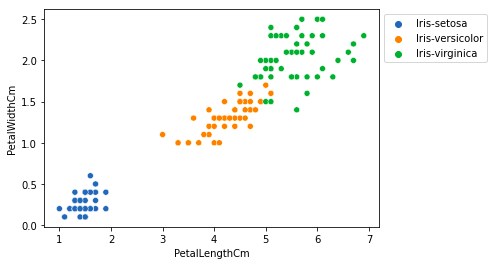
Из приведенного выше графика мы можем сделать вывод, что –
- Вид Setosa имеет меньшую длину и ширину лепестков.
- Вид Versicolor занимает промежуточное положение между двумя другими видами по длине и ширине лепестков.
- Вид Virginica имеет самые большие длину и ширину лепестков.
Давайте построим график всех взаимосвязей столбцов с помощью парного графика. Его можно использовать для многомерного анализа.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df.drop(['Id'], axis = 1),
hue='Species', height=2)
Вывод:
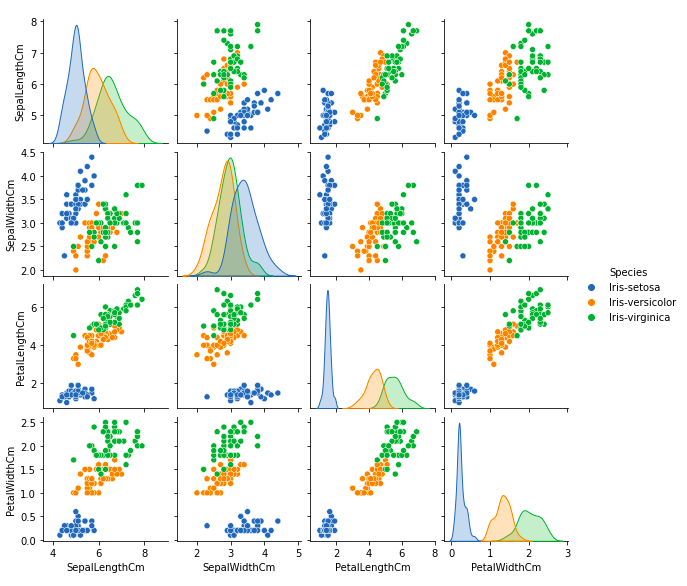
На этом графике мы можем увидеть множество взаимосвязей, например, что у вида Setosa наименьшая ширина и длина лепестков.У него также самая маленькая длина чашечки, но более широкая чашечка.Такую информацию можно собрать в любом другом виде.
Гистограммы
Гистограммы позволяют просматривать данные при различных состояниях.Их можно использовать как для одномерного, так и для двумерного анализа.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(10,10))
axes[0,0].set_title("Sepal Length")
axes[0,0].hist(df['SepalLengthCm'], bins=7)
axes[0,1].set_title("Sepal Width")
axes[0,1].hist(df['SepalWidthCm'], bins=5);
axes[1,0].set_title("Petal Length")
axes[1,0].hist(df['PetalLengthCm'], bins=6);
axes[1,1].set_title("Petal Width")
axes[1,1].hist(df['PetalWidthCm'], bins=6);
Вывод:
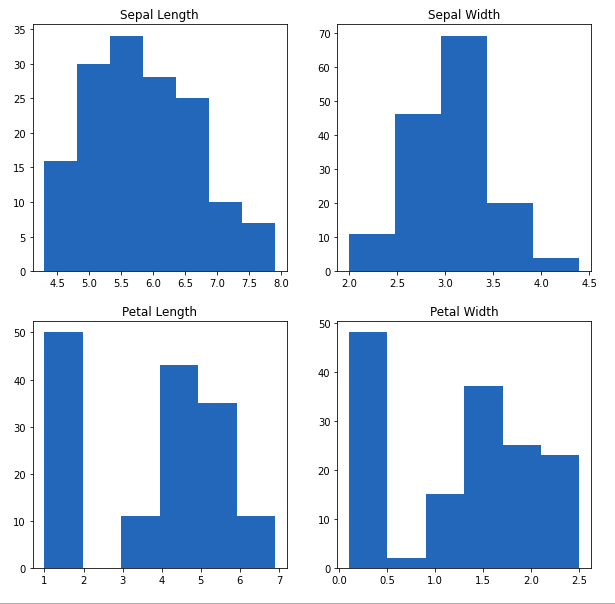
Из приведенного выше графика мы можем видеть, что –
- Максимальная длина чашелистиков составляет от 30 до 35 мм, то есть от 5,5 до 6.
- Максимальная ширина чашелистиков составляет около 70 мм, то есть от 3,0 до 3,5.
- Максимальная длина лепестков составляет около 50, то есть от 1 до 2.
- Максимальная ширина лепестков составляет от 40 до 50, то есть от 0,0 до 0,5.
Гистограммы с диаграммой Distplot
Гистограмма обычно используется для одномерного набора наблюдений и визуализирует его с помощью гистограммы, то есть есть только одно наблюдение, поэтому мы выбираем один конкретный столбец набора данных.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "SepalLengthCm").add_legend()
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "SepalWidthCm").add_legend()
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "PetalLengthCm").add_legend()
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "PetalWidthCm").add_legend()
plt.show()
Вывод:
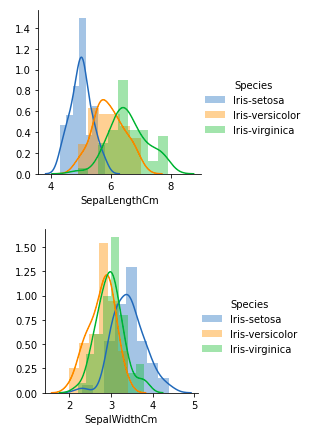
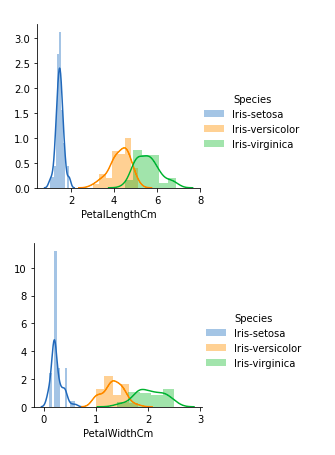
Из приведенных выше графиков мы можем видеть, что –
- В случае с третьей чашелистикой наблюдается сильное перекрытие.
- В случае с отклонением чашелистики также наблюдается сильное перекрытие.
- В случае четвертого лепестков открытие очень незначительное.
- В случае с отклонением лепестков также наблюдается очень незначительное перекрытие.
Таким образом, мы можем использовать длину и сдвиг лепестков в качестве критериев классификации.
Обработка аналогий
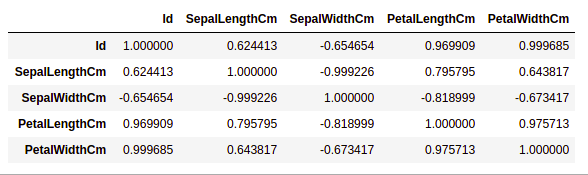
Панды dataframe.корр() используется для поиска попарной корреляции всех столбцов в рамках данных.Любые значения NA автоматически проверяются.Для столбцов нечислового типа в рамке данных это игнорируется.
Пример:
data.select_dtypes(include=['number']).corr(method='pearson')
# This code is modified by Susobhan Akhuli
Вывод:
Тёплые карты
Тепловая карта — это метод визуализации данных, который используется для анализа набора данных в виде цветов в двух измерениях.По сути, она показывает корреляцию между всеми числовыми переменными в наборе данных.Проще говоря, мы можем построить график определённой более высокой зависимости с помощью тепловых карт.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(df.select_dtypes(include=['number']).corr(method='pearson').drop(
['Id'], axis=1).drop(['Id'], axis=0),
annot = True);
plt.show()
# This code is modified by Susobhan Akhuli
Выход:
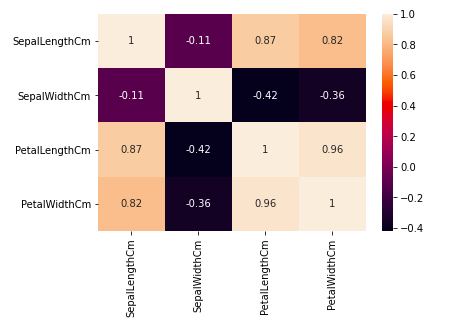
Из приведенного выше графика мы видим, что –
- Ширина и длина лепестка имеют высокую корреляцию.
- Длина лепестка и ширина чашелистика имеют хорошую корреляцию.
- Ширина лепестка и длина чашелистика имеют хорошую корреляцию.
Диаграммы ящиков
Мы можем использовать диаграммы размаха, чтобы увидеть, как категориальное значение соотносится с другими числовыми значениями.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
def graph(y):
sns.boxplot(x="Species", y=y, data=df)
plt.figure(figsize=(10,10))
# Adding the subplot at the specified
# grid position
plt.subplot(221)
graph('SepalLengthCm')
plt.subplot(222)
graph('SepalWidthCm')
plt.subplot(223)
graph('PetalLengthCm')
plt.subplot(224)
graph('PetalWidthCm')
plt.show()
Вывод:
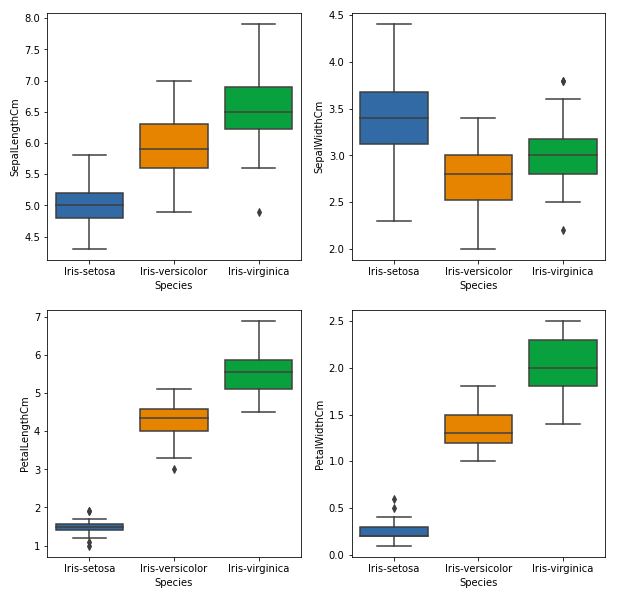
Из приведенного выше графика мы можем видеть, что –
- Вид Сетоза имеет наименьшие признаки и менее распространен, с некоторыми выбросами.
- Вид Versicolor имеет средние характеристики.
- Вид Virginica обладает самыми высокими характеристиками
Обработка выбросов
Выброс — это элемент данных/объект, который значительно отличается от остальных (так называемых нормальных) объектов. Они могут быть вызваны ошибками измерения или выполнения. Анализ для выявления выбросов называется поиском выбросов. Существует множество способов выявления выбросов, а процесс их удаления аналогичен удалению элемента данных из фрейма данных pandas.
Давайте рассмотрим набор данных «Ирис» и построим диаграмму размаха для столбца SepalWidthCm.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
df = pd.read_csv('Iris.csv')
sns.boxplot(x='SepalWidthCm', data=df)
Вывод:
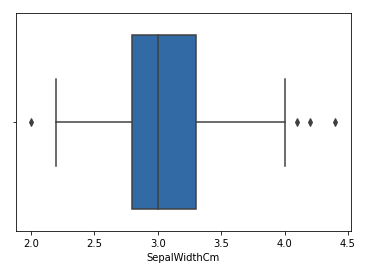
На приведённом выше графике значения выше 4 и ниже 2 являются выбросами.
Удаление выбросов
Чтобы удалить выбросы, нужно выполнить те же действия, что и при удалении записи из набора данных, используя её точное положение в наборе данных, поскольку во всех вышеперечисленных методах обнаружения выбросов конечным результатом является список всех элементов данных, которые соответствуют определению выбросов в соответствии с используемым методом.
Пример: мы обнаружим выбросы с помощью IQR, а затем удалим их. Мы также построим диаграмму размаха, чтобы проверить, удалены ли выбросы.
# Importing
import numpy as np
# Load the dataset
df = pd.read_csv('Iris.csv')
# IQR
Q1 = np.percentile(df['SepalWidthCm'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df['SepalWidthCm'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
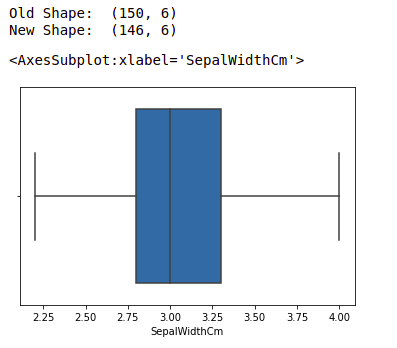
print("Old Shape: ", df.shape)
# Upper bound
upper = np.where(df['SepalWidthCm'] >= (Q3+1.5*IQR))
# Lower bound
lower = np.where(df['SepalWidthCm'] <= (Q1-1.5*IQR))
# Removing the Outliers
df.drop(upper[0], inplace = True)
df.drop(lower[0], inplace = True)
print("New Shape: ", df.shape)
sns.boxplot(x='SepalWidthCm', data=df)
# This code is modified by Susobhan Akhuli
Вывод: