Что такое EDA?
Исследовательский анализ данных (EDA) — это метод, используемый для анализа и обобщения наборов данных. Большинство методов EDA предполагают использование графиков.
Набор данных Titanic –
Это один из самых популярных наборов данных, используемых для понимания основ машинного обучения. Он содержит информацию обо всех пассажирах на борту корабля RMS Titanic, который, к сожалению, потерпел кораблекрушение. Этот набор данных можно использовать для прогнозирования того, выжил данный пассажир или нет.
CSV-файл можно загрузить с Kaggle.
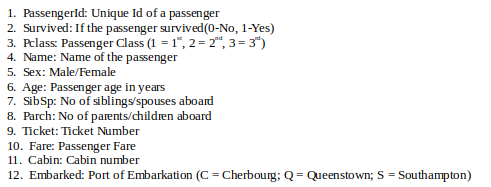
Код: загрузка данных с помощью Pandas
#importing pandas library
import pandas as pd
#loading data
titanic = pd.read_csv('...\input\train.csv')
Seaborn:
Это библиотека Python, используемая для статистической визуализации данных. Seaborn, созданная на основе Matplotlib, обеспечивает более удобный интерфейс и простоту использования. Её можно установить с помощью следующей команды:
pip3 install seaborn
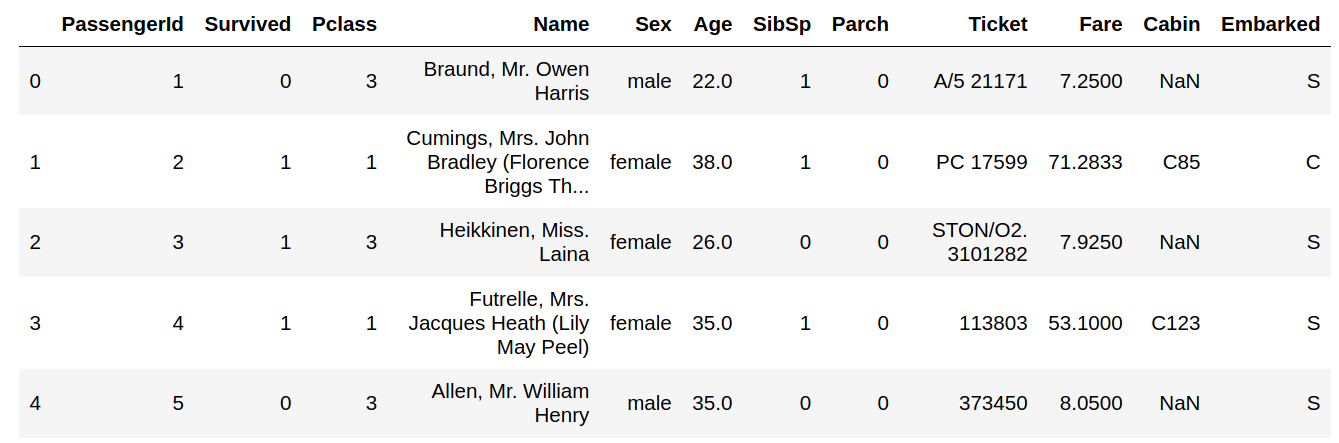
Код: Печатающая головка данных
# View first five rows of the dataset
titanic.head()
Вывод :
Код: проверка нулевых значений
titanic.isnull().sum()
Вывод :
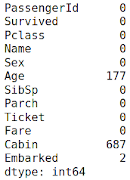
Столбцы с нулевыми значениями: «Возраст», «Каюта», «Отплытие». Их нужно будет заполнить соответствующими значениями позже.
Характеристики: В наборе данных Titanic примерно следующие типы характеристик:
- Категориальные/номинальные: переменные, которые можно разделить на несколько категорий, но без указания порядка или приоритета.
Например, место отправления (C = Шербур; Q = Квинстаун; S = Саутгемптон) - Бинарный тип: подтип категориальных признаков, где переменная имеет только две категории.
Например: пол (мужской/женский) - Порядковые: они похожи на категориальные признаки, но имеют порядок (то есть их можно отсортировать).
Например, Pclass (1, 2, 3) - Непрерывные: они могут принимать любое значение между минимальным и максимальным значениями в столбце.
Например, возраст, стоимость проезда - Количество: они представляют собой количество значений переменной.
Например, SibSp, Parch - Бесполезные: они не влияют на конечный результат модели машинного обучения. В данном случае идентификатор пассажира, имя, номер каюты и билет могут относиться к этой категории.
Код: графический анализ
import seaborn as sns
import matplotlib.pyplot as plt
# Countplot
sns.catplot(x ="Sex", hue ="Survived",
kind ="count", data = titanic)
Вывод :
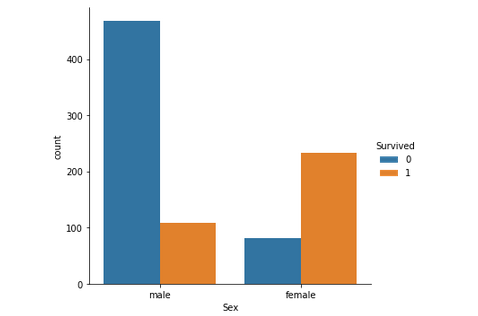
Просто взглянув на график, можно предположить, что выживаемость мужчин составляет около 20%, а женщин — около 75%. Таким образом, пол пассажира играет важную роль в определении того, выживет ли он.
Код: Pclass (порядковый номер) против Survived
# Group the dataset by Pclass and Survived and then unstack them
group = titanic.groupby(['Pclass', 'Survived'])
pclass_survived = group.size().unstack()
# Heatmap - Color encoded 2D representation of data.
sns.heatmap(pclass_survived, annot = True, fmt ="d")
Вывод:
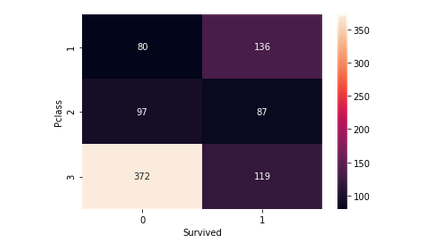
Это помогает определить, была ли выживаемость пассажиров более высокого класса выше, чем у пассажиров более низкого класса, или наоборот. У пассажиров 1-го класса шансы на выживание выше по сравнению с пассажирами 2-го и 3-го классов. Это означает, что Pclass вносит большой вклад в выживаемость пассажиров.
Код: возраст (непрерывная функция) против выжившего
# Violinplot Displays distribution of data
# across all levels of a category.
sns.violinplot(x ="Sex", y ="Age", hue ="Survived",
data = titanic, split = True)
Вывод :
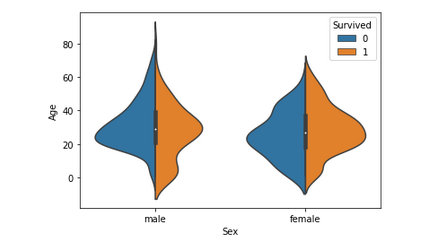
На этом графике представлен возрастной диапазон спасённых мужчин, женщин и детей. Уровень выживаемости составляет –
- Полезно для детей.
- Высоко для женщин в возрасте 20-50 лет.
- С возрастом меньше для мужчин.
Поскольку столбец «Возраст» важен, недостающие значения необходимо заполнить либо с помощью столбца «Имя» (определив возраст по обращению — «мистер», «миссис» и т. д.), либо с помощью регрессора.
После этого шага можно создать ещё один столбец — «Диапазон возраста» (на основе столбца «Возраст») и снова проанализировать данные.
Код: факторный график для Family_Size (функция Count) и размера семьи.
# Adding a column Family_Size
titanic['Family_Size'] = 0
titanic['Family_Size'] = titanic['Parch']+titanic['SibSp']
# Adding a column Alone
titanic['Alone'] = 0
titanic.loc[titanic.Family_Size == 0, 'Alone'] = 1
# Factorplot for Family_Size
sns.factorplot(x ='Family_Size', y ='Survived', data = titanic)
# Factorplot for Alone
sns.factorplot(x ='Alone', y ='Survived', data = titanic)
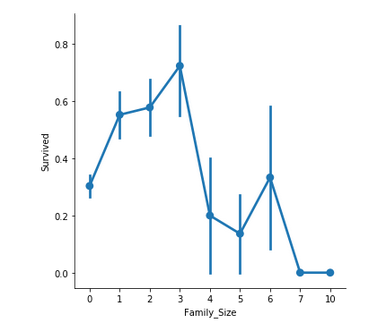
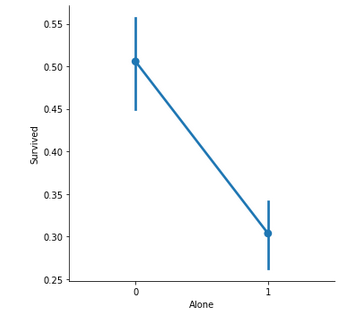
Family_Size обозначает количество человек в семье пассажира. Он рассчитывается путем суммирования столбцов SibSp и Parch соответствующего пассажира. Кроме того, другой столбец только добавляется, чтобы проверить свои шансы на выживание одинокого пассажира на один с семьей.
Важные замечания –
- Если пассажир один, вероятность выживания ниже.
- Если в семье больше 5 человек, шансы на выживание значительно снижаются.
Код : Гистограмма для тарифа (непрерывная функция)
# Divide Fare into 4 bins
titanic['Fare_Range'] = pd.qcut(titanic['Fare'], 4)
# Barplot - Shows approximate values based
# on the height of bars.
sns.barplot(x ='Fare_Range', y ='Survived',
data = titanic)
Вывод :
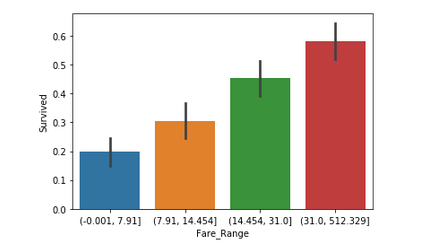
Стоимость проезда обозначает сумму, которую пассажир заплатил за проезд. Поскольку значения в этом столбце непрерывны, их необходимо разделить на отдельные категории (как в случае с функцией Возраст), чтобы получить чёткое представление. Можно сделать вывод, что если пассажир заплатил более высокую стоимость проезда, то вероятность выживания выше.
Код: графики категориального подсчета для запущенной функции
# Countplot
sns.catplot(x ='Embarked', hue ='Survived',
kind ='count', col ='Pclass', data = titanic)
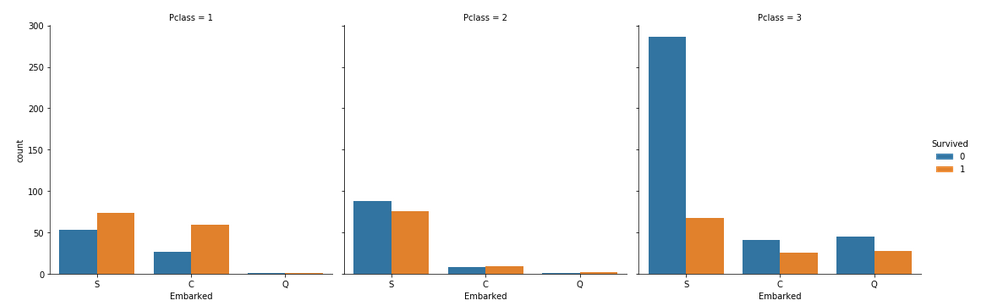
Вот некоторые примечательные наблюдения:
- Большинство пассажиров сели на борт в S. Таким образом, недостающие значения можно заполнить с помощью S.
- Большинство пассажиров 3-го класса поднялись на борт из Q.
- S выглядит удачным вариантом для пассажиров первого и второго классов по сравнению с третьим классом.
Заключение :
- Столбцы, которые можно удалить, следующие:
- PassengerId, Name, Ticket, Cabin: это строки, которые нельзя классифицировать и которые не сильно влияют на результат.
- Age, Fare: вместо этого сохраняются соответствующие столбцы диапазона.
- Титанические объёмы данных можно проанализировать с помощью множества графических методов, а также корреляций между столбцами, как описано в этой статье.
- После завершения EDA полученный набор данных можно использовать для прогнозирования.