В современном цифровом мире данные являются ключом к раскрытию ценной информации, и большая часть этих данных доступна в Интернете. Но как эффективно собирать большие объемы данных с веб-сайтов? Вот тут-то и пригодится Веб-очистка Python. Веб-очистка, процесс извлечения данных с веб-сайтов, превратился в мощный метод сбора информации на огромных просторах Интернета.
В этом руководстве мы рассмотрим различные библиотеки и модули Python, которые обычно используются для web - парсинг, и выясним, почему Python 3 является предпочтительным выбором для этой задачи. Кроме того, вы узнаете, как использовать такие мощные инструменты, как BeautifulSoup, Scrapy и Selenium для сбора данных с любого веб-сайта.
Необходимые пакеты и инструменты для очистки веб-страниц Python
Последняя версия Python предлагает широкий набор инструментов и библиотек, специально разработанных для веб-скрапинга, что делает получение данных из Интернета более простым и эффективным, чем когда-либо.
Содержание
- Requests Module
- BeautifulSoup Library
- Selenium
- Lxml
- Urllib Module
- PyautoGUI
- Schedule
- Зачем нужен Python3 для веб-очистки?
Модуль запросов
Библиотека запросов используется для отправки HTTP-запросов по определённому URL-адресу и возвращает ответ. Библиотека запросов Python предоставляет встроенные функции для управления как запросом, так и ответом.
pip install requests
Пример: Создание запроса
Модуль Python requests имеет несколько встроенных методов для отправки HTTP-запросов по указанному URI с помощью запросов GET, POST, PUT, PATCH или HEAD. HTTP-запрос предназначен для получения данных по указанному URI или отправки данных на сервер. Он работает как протокол «запрос-ответ» между клиентом и сервером. Здесь мы будем использовать запрос GET. Метод GET используется для получения информации с указанного сервера по указанному URI. Метод GET отправляет закодированную информацию о пользователе, добавленную к запросу страницы.
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# print content of request
print(r.content)
Вывод

Библиотека BeautifulSoup
Beautiful Soup предоставляет несколько простых методов для навигации, поиска и изменения дерева синтаксического разбора: набор инструментов для изучения документа и удаления того, что вам нужно. Для документирования приложения не требуется много кода.
Beautiful Soup автоматически преобразует входящие записи в Unicode, а исходящие формы - в UTF-8. Вам не нужно думать о кодировках, если только документ не определяет кодировку, а Beautiful Soup не может ее перехватить. Затем вам просто нужно выбрать исходную кодировку. Beautiful Soup находится поверх известных анализаторов Python, таких как LXML и HTML, позволяя вам попробовать различные стратегии синтаксического анализа или обменять скорость на гибкость.
pip install beautifulsoup4
Пример
- Импорт библиотек: Код импортирует библиотеку requests для выполнения HTTP-запросов и класс BeautifulSoup из библиотеки bs4 для анализа HTML.
- Отправка запроса GET: Он отправляет запрос GET на адрес ‘https://www.geeksforgeeks.org/python-programming-language/’ и сохраняет ответ в переменной r.
- Проверка кода состояния: выводит код состояния ответа, обычно 200 для успешного выполнения.
- Разбор HTML-кода: HTML-содержимое ответа анализируется с помощью BeautifulSoup и сохраняется в переменной soup.
- Печать форматированного HTML: Выводит форматированную версию проанализированного HTML-контента для удобства чтения и анализа.
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
Вывод

Поиск элементов по классам
Теперь мы хотели бы извлечь некоторые полезные данные из HTML-контента. Объект soup содержит все данные во вложенной структуре, которые можно извлечь программно. Веб-сайт, который мы хотим очистить, содержит много текста, поэтому давайте очистим весь этот контент. Сначала давайте рассмотрим веб-страницу, которую хотим очистить.

На изображении выше мы видим, что всё содержимое страницы находится под элементом div с классом entry-content. Мы будем использовать класс find. Этот класс найдёт заданный тег с заданным атрибутом. В нашем случае он найдёт все элементы div с классом entry-content.
Мы видим, что содержимое страницы находится под тегом <p>. Теперь нам нужно найти все теги p, присутствующие в этом классе. Мы можем использовать find_all класс BeautifulSoup.
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
content = s.find_all('p')
print(content)
Вывод:

Selenium
Selenium — это популярный модуль Python, используемый для автоматизации веб-браузеров. Он позволяет разработчикам управлять веб-браузерами программно, выполняя такие задачи, как web - парсинг, автоматизированное тестирование и взаимодействие с веб-приложениями. Selenium поддерживает различные веб-браузеры, включая Chrome, Firefox, Safari и Edge, что делает его универсальным инструментом для автоматизации браузеров.
Пример 1: Для Firefox
В этом конкретном примере мы перенаправляем браузер на страницу поиска Google с параметром запроса “geeksforgeeks”. Браузер загрузит эту страницу, и затем мы можем приступить к программному взаимодействию с ней с помощью Selenium. Это взаимодействие может включать такие задачи, как извлечение результатов поиска, нажатие на ссылки или удаление определенного содержимого со страницы.
# import webdriver
from selenium import webdriver
# create webdriver object
driver = webdriver.Firefox()
# get google.co.in
driver.get("https://google.co.in / search?q = geeksforgeeks")
Вывод

Пример 2: Для Chrome
- Мы импортируем модуль webdriver из библиотеки Selenium.
- Мы указываем путь к исполняемому файлу веб-драйвера. Вам нужно скачать соответствующий драйвер для вашего браузера и указать путь к нему. В этом примере мы используем драйвер Chrome.
- Мы создаём новый экземпляр веб-браузера с помощью webdriver.Chrome() и передаём путь к исполняемому файлу драйвера Chrome в качестве аргумента.
- Мы переходим на веб-страницу, вызывая метод get() объекта браузера и передавая URL-адрес веб-страницы.
- Мы извлекаем информацию с веб-страницы с помощью различных методов, предоставляемых Selenium. В этом примере мы получаем заголовок страницы с помощью атрибута title объекта браузера.
- Наконец, мы закрываем браузер, используя метод quit().
# importing necessary packages
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# for holding the resultant list
element_list = []
for page in range(1, 3, 1):
page_url = "https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=" + str(page)
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(page_url)
title = driver.find_elements(By.CLASS_NAME, "title")
price = driver.find_elements(By.CLASS_NAME, "price")
description = driver.find_elements(By.CLASS_NAME, "description")
rating = driver.find_elements(By.CLASS_NAME, "ratings")
for i in range(len(title)):
element_list.append([title[i].text, price[i].text, description[i].text, rating[i].text])
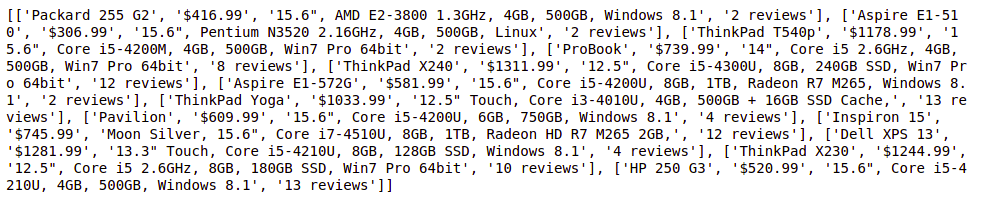
print(element_list)
#closing the driver
driver.close()
Вывод
Lxml
Модуль lxml в Python — это мощная библиотека для обработки XML и HTML документов. Она обеспечивает высокопроизводительный синтаксический анализ XML и HTML, а также простой и понятный API. lxml широко используется в web - парсинге на Python благодаря своей скорости, гибкости и простоте использования.
pip install lxml
Пример
Вот простой пример, демонстрирующий, как использовать модуль lxml для веб-парсинга на Python:
- Мы импортируем модуль html из lxml вместе с модулем запросов для отправки HTTP-запросов.
- Мы определяем URL веб-сайта, который хотим очистить.
- Мы отправляем HTTP-запрос GET на веб-сайт с помощью функции requests.get() и получаем HTML-содержимое страницы.
- Мы анализируем содержимое HTML с помощью функции html.fromstring() из lxml, которая возвращает дерево элементов HTML.
- Мы используем выражения XPath для извлечения определённых элементов из дерева HTML. В данном случае мы извлекаем текстовое содержимое всех элементов <a> (якорных ссылок) на странице.
- Мы перебираем извлеченные заголовки ссылок и распечатываем их.
from lxml import html
import requests
# Define the URL of the website to scrape
url = 'https://example.com'
# Send an HTTP request to the website and retrieve the HTML content
response = requests.get(url)
# Parse the HTML content using lxml
tree = html.fromstring(response.content)
# Extract specific elements from the HTML tree using XPath
# For example, let's extract the titles of all the links on the page
link_titles = tree.xpath('//a/text()')
# Print the extracted link titles
for title in link_titles:
print(title)
Вывод
More information...
Модуль Urllib
Модуль urllib в Python — это встроенная библиотека, предоставляющая функции для работы с URL-адресами. Он позволяет взаимодействовать с веб-страницами, получая URL-адреса (унифицированные указатели ресурсов), открывая и читая данные с них, а также выполняя другие задачи, связанные с URL-адресами, такие как кодирование и синтаксический анализ. Urllib — это пакет, объединяющий несколько модулей для работы с URL-адресами, таких как:
- urllib.request на открытие и чтение.
- urllib.parse для синтаксического анализа URL-адресов
- urllib.error из-за возникших исключений
- urllib.robotparser для синтаксического анализа robot.txt файлов
Если в вашей среде нет модуля urllib, выполните приведенный ниже код для его установки.
pip install urllib3
Пример
Вот простой пример, демонстрирующий, как использовать модуль urllib для получения содержимого веб-страницы:
- Мы определяем URL веб-страницы, которую хотим получить.
- Мы используем функцию urllib.request.urlopen() для открытия URL-адреса и получения объекта ответа.
- Мы считываем содержимое объекта response с помощью метода read().
- Поскольку содержимое возвращается в виде байтов, мы декодируем его в строку с помощью метода decode() с кодировкой «utf-8».
- Наконец, мы печатаем HTML-содержимое веб-страницы.
import urllib.request
# URL of the web page to fetch
url = 'https://www.example.com'
try:
# Open the URL and read its content
response = urllib.request.urlopen(url)
# Read the content of the response
data = response.read()
# Decode the data (if it's in bytes) to a string
html_content = data.decode('utf-8')
# Print the HTML content of the web page
print(html_content)
except Exception as e:
print("Error fetching URL:", e)
Вывод

PyautoGUI
Модуль pyautogui в Python — это кроссплатформенная библиотека для автоматизации графического интерфейса, которая позволяет разработчикам управлять мышью и клавиатурой для автоматизации задач. Хотя она не предназначена специально для веб-парсинга, её можно использовать в сочетании с другими библиотеками для веб-парсинга, такими как Selenium, для взаимодействия с веб-страницами, которые требуют ввода данных пользователем или имитируют действия человека.
pip3 install pyautogui
Пример
В этом примере pyautogui используется для прокрутки и создания скриншота страницы результатов поиска, полученной путём ввода запроса в поле поиска и нажатия кнопки поиска с помощью Selenium.
import pyautogui
# moves to (519,1060) in 1 sec
pyautogui.moveTo(519, 1060, duration = 1)
# simulates a click at the present
# mouse position
pyautogui.click()
# moves to (1717,352) in 1 sec
pyautogui.moveTo(1717, 352, duration = 1)
# simulates a click at the present
# mouse position
pyautogui.click()
Вывод

Расписание
Модуль schedule в Python — это простая библиотека, которая позволяет планировать выполнение функций Python через заданные промежутки времени. Она особенно полезна при парсинге веб-страниц на Python, когда вам нужно регулярно собирать данные с веб-сайта через заданные промежутки времени, например, ежечасно, ежедневно или еженедельно.
Пример
- Мы импортируем необходимые модули: schedule, time, requests и BeautifulSoup из пакета bs4.
- Мы определяем функцию scrape_data(), которая выполняет задачу веб-парсинга. Внутри этой функции мы отправляем GET-запрос на веб-сайт (замените «https://example.com» на URL-адрес веб-сайта, который вы хотите очистить), анализируем содержимое HTML с помощью BeautifulSoup, извлекаем нужные данные и выводим их на печать.
- Мы запланировали выполнение функции scrape_data() каждый час с помощью schedule.every().hour.do(scrape_data).
- Мы входим в основной цикл, который непрерывно проверяет наличие отложенных запланированных задач с помощью schedule.run_pending() и делает паузу на 1 секунду между итерациями, чтобы цикл не потреблял слишком много ресурсов процессора.
import schedule
import time
def func():
print("Geeksforgeeks")
schedule.every(1).minutes.do(func)
while True:
schedule.run_pending()
time.sleep(1)
Вывод

Зачем нужен Python3 для веб-очистки?
Популярность Python для веб-очистки обусловлена несколькими факторами:
Простота использования : понятный и читаемый синтаксис Python упрощает понимание и написание кода даже для новичков. Такая простота ускоряет процесс разработки и сокращает время обучения для задач web - парсинга.
Богатая экосистема: Python может похвастаться обширной экосистемой библиотек и фреймворков, предназначенных для веб-парсинга. Такие библиотеки, как BeautifulSoup, Scrapy и Requests, упрощают процесс разбора HTML, делая извлечение данных простым.
Универсальность: Python — это универсальный язык, который можно использовать для широкого спектра задач, помимо веб-парсинга. Его гибкость позволяет разработчикам легко интегрировать веб-парсинг в более крупные проекты, такие как анализ данных, машинное обучение или веб-разработка.
Поддержка сообщества: у Python есть большое и активное сообщество разработчиков, которые вносят свой вклад в его библиотеки и оказывают поддержку на форумах, в учебных пособиях и документации. Такое обилие ресурсов гарантирует, что разработчики имеют доступ к помощи и рекомендациям при решении задач, связанных с веб-парсингом.
Заключение
В этом руководстве вы познакомились с основами использования Python для веб-парсинга. С помощью инструментов, которые мы обсудили, вы можете быстро и легко начать собирать данные из интернета. Независимо от того, нужны ли вам эти данные для проекта, исследования или просто для развлечения, Python позволяет это сделать. Не забывайте, что всегда нужно ответственно подходить к сбору данных и соблюдать правила, установленные веб-сайтами.