Pandas — это библиотека с открытым исходным кодом, используемая для обработки и анализа данных в Python. Это быстрый и мощный инструмент, предлагающий структуры данных и операции для работы с числовыми таблицами и временными рядами. Примеры таких операций с данными включают объединение, изменение формы, выборку, очистку данных и обработку данных. Эта библиотека позволяет импортировать данные из различных форматов файлов, таких как SQL, JSON, Microsoft Excel и значения, разделённые запятыми. В этой статье объясняется, как использовать библиотеку pandas для построения графика временных рядов или линейного графика для заданного набора данных.
Линейный график — это графическое представление, наглядно показывающее взаимосвязь между определёнными переменными или изменения в данных с течением времени с помощью нескольких точек, обычно упорядоченных по значению оси X, которые соединены отрезками прямых линий. Независимая переменная представлена на оси X, а на оси Y представлены данные, которые изменяются в зависимости от переменной на оси X, то есть зависимой переменной.
Чтобы создать линейный график с помощью pandas, мы обычно создаём DataFrame* с набором данных, который нужно построить. Затем вызывается метод plot.line() для DataFrame.
Синтаксис:
DataFrame.plot.line(x, y)
В таблице ниже приведены основные параметры:
| Parameter | Value | Default Value | Use |
| x | Int or string | DataFrame indices | Set the values to be represented in the x-axis. |
| y | Int or string | Remaining columns in DataFrame | Set the values to be represented in the y-axis. |
Дополнительные параметры включают цвет (определяет цвет линии), заголовок (определяет название графика) и тип (определяет тип графика). Переменная по умолчанию для параметра «тип» этого метода — «линия». Поэтому вам не нужно задавать этот параметр, чтобы создать линейный график.
Пример 1:
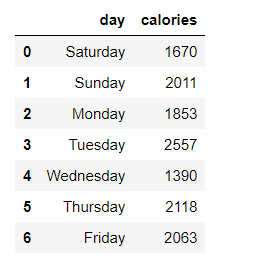
В этом примере показано, как создать базовый линейный график для фрейма данных с одной переменной по оси Y.Используйте pandas в Python3, чтобы построить график на основе следующих данных о потреблении калорий в течение недели. Вот наш фрейм данных.
Код:
import pandas as pd
# Create a list of data to be represented in x-axis
days = [ 'Saturday' , 'Sunday' , 'Monday' , 'Tuesday' ,
'Wednesday' , 'Thursday' , 'Friday' ]
# Create a list of data to be
# represented in y-axis
calories = [ 1670 , 2011 , 1853 , 2557 ,
1390 , 2118 , 2063 ]
# Create a dataframe using the two lists
df_days_calories = pd.DataFrame(
{ 'day' : days , 'calories' : calories })
df_days_calories
Вывод:
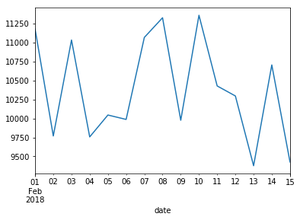
Теперь построим график переменной.
# use plot() method on the dataframe
df_days_calories.plot( 'day' , 'calories' )
# Alternatively, you can use .set_index
# to set the data of each axis as follows:
# df_days_calories.set_index('day')['calories'].plot();
Вывод:
Пример 2:
В этом примере объясняется, как создать линейный график с двумя переменными по оси Y.
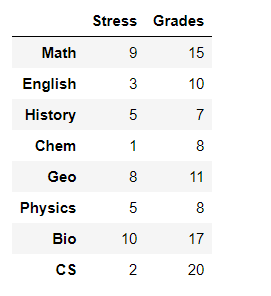
Ученика попросили оценить уровень стресса на промежуточных экзаменах по каждому школьному предмету по шкале от 1 до 10 (10 — самый высокий уровень). Его также попросили оценить свою оценку на каждом промежуточном экзамене (из 20).
Код:
import pandas as pd
# Create a list of data to
# be represented in x-axis
subjects = [ 'Math' , 'English' , 'History' ,
'Chem' , 'Geo' , 'Physics' , 'Bio' , 'CS' ]
# Create a list of data to be
# represented in y-axis
stress = [ 9 , 3 , 5 , 1 , 8 , 5 , 10 , 2 ]
# Create second list of data
# to be represented in y-axis
grades = [ 15 , 10 , 7 , 8 , 11 , 8 , 17 , 20 ]
# Create a dataframe using the three lists
df = pd.DataFrame(list(zip( stress , grades )),
index = subjects ,
columns = [ 'Stress' , 'Grades' ])
df
Вывод:
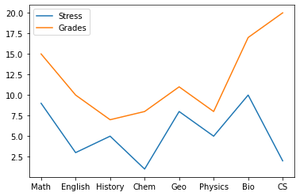
Создайте линейный график, который показывает взаимосвязи между этими тремя переменными.
Код:
# use plot() method on the dataframe.
# No parameters are passed so it uses
# variables given in the dataframe
df.plot()
Вывод:
Альтернативным способом может быть использование метода gca() из библиотеки matplotlib.pyplot следующим образом:
import pandas as pd
import matplotlib.pyplot as plt
# Create a list of data
# to be represented in x-axis
subjects = [ 'Math' , 'English' , 'History ',
'Chem' , 'Geo' , 'Physics' , 'Bio' , 'CS' ]
# Create a list of data
# to be represented in y-axis
stress = [ 9, 3 , 5 , 1 , 8 , 5 , 10 , 2 ]
# Create second list of data to be represented in y-axis
grades = [ 15, 10 , 7 , 8 , 11 , 8 , 17 , 20 ]
# Create a dataframe using the two lists
df_days_calories = pd.DataFrame(
{ 'Subject' : subjects ,
'Stress': stress ,
'Grade': grades})
ax = plt.gca()
#use plot() method on the dataframe
df_days_calories.plot( x = 'Subject' , y = 'Stress', ax = ax )
df_days_calories.plot( x = 'Subject' , y = 'Grade' , ax = ax )
Вывод:
Пример 3:
В этом примере мы создадим график без явного определения списков переменных. Мы также добавим заголовок и изменим цвет.
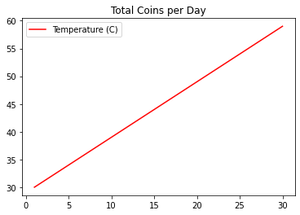
У коллекционера монет изначально было 30 монет. После этого в течение месяца он каждый день находил по одной монете. Покажите на линейном графике, сколько монет у него было каждый день в течение этого месяца.
import pandas as pd
#initialize the temperature value at the first day of the month
c = 30
# Create a dataframe using the three lists
# the y-axis variable is a list created using
# a for loops, in each iteration,
# it adds 1 to previous value
# the x-axis variable is a list of values ranging
# from 1 to 31 (31 not included) with a step of 1
df = pd.DataFrame([ c + x for x in range( 0 , 30 )],
index = [*range( 1 , 31 , 1 )],
columns = [ 'Temperature (C)' ])
# use plot() method on the dataframe.
# No parameters are passed so it uses
# variables given in the dataframe
df.plot(color='red', title = 'Total Coins per Day')
Вывод:
Пример 4:
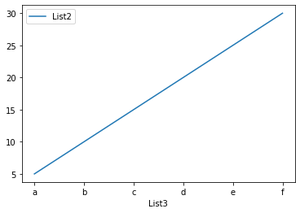
В этом примере мы построим график для определённых столбцов фрейма данных. Фрейм данных состоит из трёх списков, однако для построения графика мы выберем только два списка.
Код:
import pandas as pd
# Create a dataframe using three lists
df = pd.DataFrame(
{'List1': [ 1 , 2 , 3 , 4 , 5 , 6 ],
'List2': [ 5 , 10 , 15 , 20 , 25 , 30 ],
'List3': [ 'a' , 'b' , 'c' , 'd' , 'e' , 'f' ]})
# use plot() method on the dataframe.
# List3 is in the x-axis and List2 in the y-axis
df.plot( 'List3' , 'List2' )
Вывод:
- Информация о материале
- Категория: Data Sciense
- Просмотров: 8
Визуализация данных — это представление данных в графическом формате. Она чрезвычайно важна для анализа данных, в первую очередь благодаря фантастической экосистеме ориентированных на работу с данными пакетов Python. Она помогает понять данные, какими бы сложными они ни были, обобщая и представляя огромный объём данных в простом и понятном формате, а также помогает чётко и эффективно доносить информацию.

Содержание
- Начало работы с Seaborn
- Установка Seaborn для визуализации данных
- Создание базовых графиков с помощью Seaborn
- Настройка графиков Seaborn с помощью Python
- Визуализация попарных связей с помощью Seaborn: парные графики
- Совместные дистрибутивы с Seaborn: совместные графики
- Создание многоплоскостных сеток с помощью FacetGrid от Seaborn
- Иллюстрирование регрессионных зависимостей с помощью Seaborn
Начало работы с Seaborn
Seaborn — это библиотека визуализации данных на Python, которая упрощает процесс создания сложных визуализаций. Она специально разработана для визуализации статистических данных, что упрощает понимание распределения данных и взаимосвязей между переменными. Seaborn тесно интегрируется со структурами данных Pandas, обеспечивая удобство работы с данными и их визуализацию.
Он построен на основе библиотеки matplotlib и тесно интегрирован в структуры данных из pandas.
Ключевые особенности Seaborn:
- Высокоуровневый интерфейс: упрощает создание сложных визуализаций.
- Интеграция с Pandas: работает без сбоев с фреймами данных Pandas для обработки данных.
- Встроенные темы: предлагают привлекательные темы по умолчанию и цветовые палитры.
- Статистические графики: предоставляют различные типы графиков для визуализации статистических взаимосвязей и распределений.
Установка Seaborn для визуализации данных
Перед использованием Seaborn вам нужно будет его установить. Самый простой способ установить Seaborn — использовать pip, менеджер пакетов Python для среды Python:
pip install seaborn

Установка Seaborn
Для получения дополнительной информации, пожалуйста, перейдите по ссылкам ниже:
- Как установить Seaborn в Windows?
- Как установить Seaborn в Pycharm?
- Как установить Seaborn в Linux?
Создание базовых графиков с помощью Seaborn
Прежде чем начать, давайте вкратце рассмотрим двумерные и одномерные данные:
- Двумерные данные: Этот тип данных включает в себя две разные переменные. Анализ этого типа данных связан с причинами и взаимосвязями, и анализ проводится для выявления взаимосвязи между двумя переменными.
- Одномерные данные: Этот тип данных состоит из только одной переменной. Таким образом, анализ одномерных данных является простейшей формой анализа, поскольку информация касается только одной изменяющейся величины. Он не рассматривает причины или взаимосвязи, и основная цель анализа — описать данные и выявить существующие в них закономерности.
Seaborn предлагает множество типов графиков для визуализации различных аспектов данных. Seaborn помогает визуализировать статистические взаимосвязи, понять, как переменные в наборе данных связаны друг с другом и как эта взаимосвязь зависит от других переменных. Мы выполняем статистический анализ.Этот статистический анализ помогает визуализировать тенденции и выявлять различные закономерности в наборе данных. Ниже приведены некоторые распространённые графики, которые можно создать с помощью Seaborn:
1. Линейный график
Линейный график — это самый популярный способ отображения зависимости между x и y с возможностью нескольких семантических группировок. Он часто используется для отслеживания изменений в течение интервалов.
Синтаксис:
sns.lineplot(x=None, y=None)
Параметры:
x, y: Входные переменные данных; должны быть числовыми. Можно передавать данные напрямую или ссылаться на столбцы в данных.
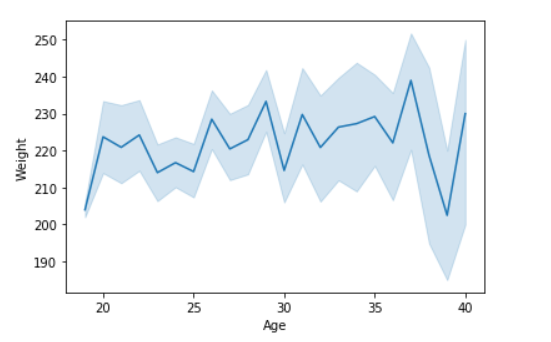
Давайте визуализируем данные с помощью линейного графика и панд:
import pandas as pd
import seaborn as sns
# initialise data of lists
data = {'Name':[ 'Mohe' , 'Karnal' , 'Yrik' , 'jack' ],
'Age':[ 30 , 21 , 29 , 28 ]}
df = pd.DataFrame( data )
# plotting lineplot
sns.lineplot( data['Age'], data['Weight'])
Вывод:
2. Точечная диаграмма
Точечные диаграммы используются для визуализации взаимосвязи между двумя числовыми переменными. Они помогают выявить корреляции или закономерности. С их помощью можно построить двумерный график.
Синтаксис:
seaborn.scatterplot(x=None, y=None)
Параметры:
x, y: переменные входных данных, которые должны быть числовыми.Возвращает: этот метод возвращает объект Axes с нанесённым на него графиком.
Давайте визуализируем данные с помощью точечной диаграммы и панд:
import pandas as pd
import seaborn as sns
# initialise data of lists
data = {'Name':[ 'Mohe' , 'Karnal' , 'Yrik' , 'jack' ],
'Age':[ 30 , 21 , 29 , 28 ]}
df = pd.DataFrame( data )
seaborn.scatterplot(data['Age'],data['Weight'])
Вывод:
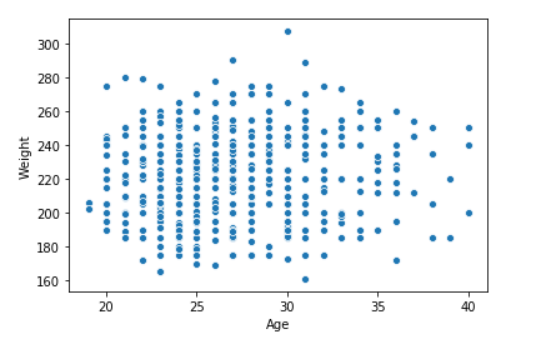
3. Прямоугольная диаграмма
Прямоугольная диаграмма (или график "прямоугольник и усы") - это визуальное представление групп числовых данных через их квартили на основе непрерывных / категориальных данных.
Прямоугольная диаграмма состоит из 5 элементов.
- Минимальный
- Первый квартиль или 25%
- Медиана (Второй квартиль) или 50%
- Третий квартиль или 75%
- Максимум
Синтаксис:
seaborn.boxplot(x=None, y=None, hue=None, data=None)
Параметры:
- x, y, оттенок: Входные данные для построения графика с длинными рядами данных.
- data: Набор данных для построения графика. Если x и y отсутствуют, это интерпретируется как широкоформатный режим.
Возвращает: Возвращает объект Axes с нанесённым на него графиком.
Давайте создадим прямоугольную диаграмму с помощью seaborn на примере.
import pandas as pd
import seaborn as sns
# initialise data of lists
data = {'Name':[ 'Mohe' , 'Karnal' , 'Yrik' , 'jack' ],
'Age':[ 30 , 21 , 29 , 28 ]}
df = pd.DataFrame( data )
sns.boxplot( data['Age'] )
Вывод:
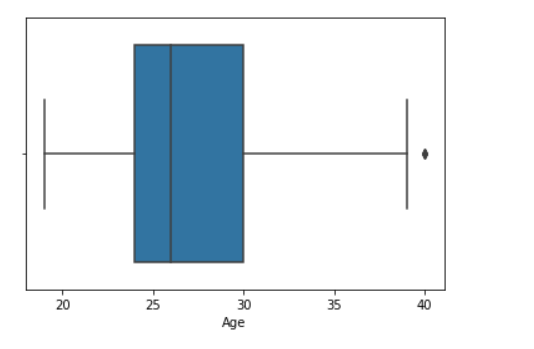
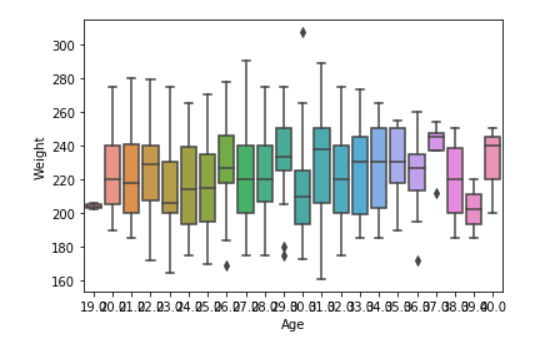
Пример 2: Давайте посмотрим, как создать прямоугольную диаграмму с дополнительными функциями
# import module
import seaborn as sns
import pandas
# read csv and plotting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'], data['Weight'])
Вывод:
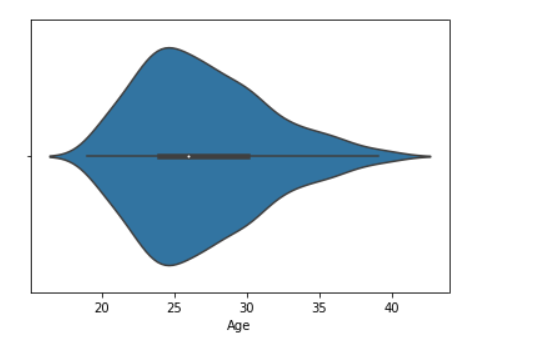
4. График скрипки
Aграфик скрипки похож на boxplot. Он показывает несколько количественных данных по одной или нескольким категориальным переменным, так что эти распределения можно сравнить.
Синтаксис:
seaborn.violinplot(x=None, y=None, hue=None, data=None)
Параметры:
- x, y, оттенок: Входные данные для построения графика с длинными рядами данных.
- data: Набор данных для построения графика.
Пример 1: Нарисуйте график скрипки с пандами
import pandas as pd
import seaborn as sns
# initialise data of lists
data = {'Name':[ 'Mohe' , 'Karnal' , 'Yrik' , 'jack' ],
'Age':[ 30 , 21 , 29 , 28 ]}
df = pd.DataFrame( data )
sns.violinplot(data['Age'])
Вывод:
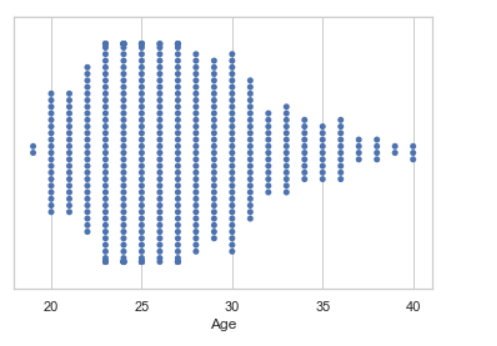
5. График роя
График роя похож на полосовой график, мы можем нарисовать график роя с неперекрывающимися точками на основе категориальных данных.
Синтаксис:
seaborn.swarmplot(x=None, y=None, hue=None, data=None)
Параметры:
- x, y, оттенок: Входные данные для построения графика с длинными рядами данных.
- data: Набор данных для построения графика.
Пример: Нарисуйте график роя с помощью Pandas
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv( "nba.csv" )
seaborn.swarmplot(x = data["Age"])
Вывод:
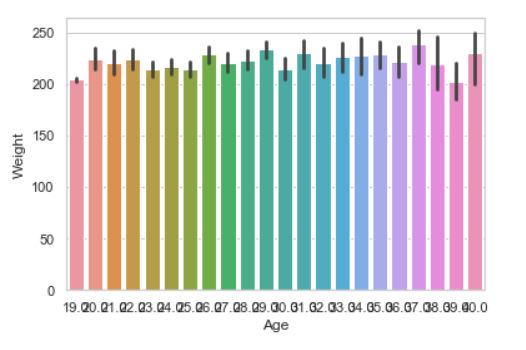
6. Гистограмма
Гистограмма представляет собой оценку центральной тенденции для числовой переменной с помощью высоты каждого прямоугольника и даёт некоторое представление о неопределённости этой оценки с помощью полос ошибок.
Синтаксис:
seaborn.barplot(x=None, y=None, hue=None, data=None)
Параметры :
- x, y : Этот параметр принимает имена переменных в данных или векторных данных, а также входные данные для построения графиков с длинными названиями.
- hue : (необязательно) Этот параметр принимает имя столбца для цветовой кодировки.
- data : (необязательно) Этот параметр принимает DataFrame, массив или список массивов, набор данных для построения графика. Если x и y отсутствуют, это интерпретируется как широкоформатный режим. В противном случае ожидается, что это будет длинный формат.
Возвращает : Возвращает объект Axes с нанесённым на него графиком.
Пример: Нарисуйте линейчатый график с помощью Pandas
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x ="Age", y ="Weight", data = data)
Вывод:
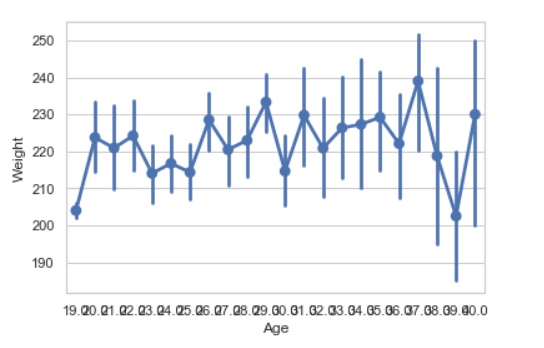
7. Точечный график
Точечная диаграммаиспользуется для отображения точечных оценок и доверительных интервалов с помощью точек на диаграмме рассеяния. Точечная диаграмма представляет собой оценку центральной тенденции для числовой переменной по расположению точек на диаграмме рассеяния и даёт некоторое представление о неопределённости этой оценки с помощью полос ошибок.
Синтаксис:
seaborn.pointplot(x=None, y=None, hue=None, data=None)
Параметры:
- x, y: Входные данные для построения графиков данных длинной формы.
- hue: (необязательно) название столбца для цветовой кодировки.
- data: dataframe как набор данных для построения графика.
Возвращает: Объект Axes с нанесенным на него графиком.
Пример: Нарисуйте точечный график с помощью Pandas
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.pointplot(x = "Age", y = "Weight", data = data)
Вывод:
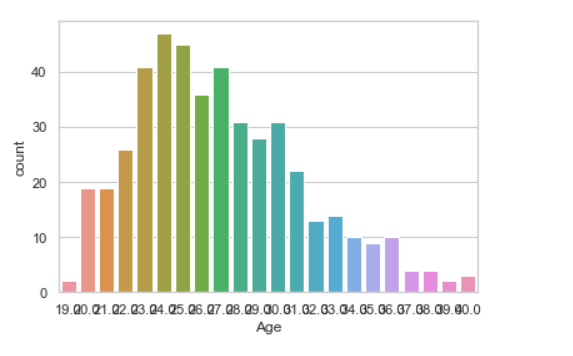
8. График подсчета
Гистограмма используется для отображения количества наблюдений в каждой категории с помощью столбцов.
Синтаксис:
seaborn.countplot(x=None, y=None, hue=None, data=None)
Параметры :
- x, y: Этот параметр принимает имена переменных в data или векторных данных, необязательно, входных данных для построения данных длинной формы.
- hue : (необязательно) Этот параметр принимает имя столбца для цветовой кодировки.
- data : (необязательно) Этот параметр принимает фрейм данных, массив или список массивов, набор данных для построения графика. Если x и y отсутствуют, это интерпретируется как широкоформатный режим. В противном случае ожидается, что это будет длинно форматный режим.
Возвращает: возвращает объект Axes с нанесённым на него графиком.
Пример: Нарисуйте график подсчета с помощью Pandas
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.countplot(data["Age"])
Выход:
 9. Сюжет KDE
9. Сюжет KDE
График KDE, описанный как Оценка плотности ядра, используется для визуализации плотности вероятности непрерывной переменной. Он отображает плотность вероятности при различных значениях непрерывной переменной. Мы также можем построить один график для нескольких выборок, что помогает более эффективно визуализировать данные.
Синтаксис:
seaborn.kdeplot(x=None, *, y=None, vertical=False, palette=None, **kwargs)
Параметры:
x, y: векторы или ключи в данных
vertical : логическое значение (истина или ложь)
data : панды.DataFrame, numpy.ndarray, сопоставление или последовательность.
Пример: рисование графика KDE с помощью Pandas
# importing the required libraries
from sklearn import datasets
import pandas as pd
import seaborn as sns
# Setting up the Data Frame
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data, columns=['Sepal_Length',
'Sepal_Width', 'Patal_Length', 'Petal_Width'])
iris_df['Target'] = iris.target
iris_df['Target'].replace([0], 'Iris_Setosa', inplace=True)
iris_df['Target'].replace([1], 'Iris_Vercicolor', inplace=True)
iris_df['Target'].replace([2], 'Iris_Virginica', inplace=True)
# Plotting the KDE Plot
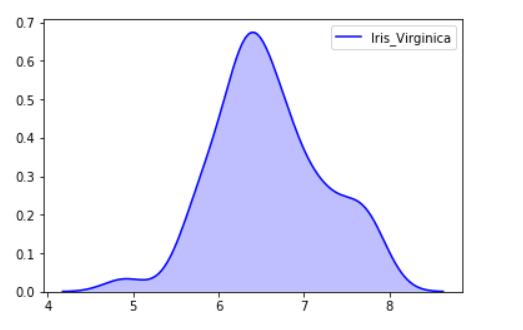
sns.kdeplot(iris_df.loc[(iris_df['Target'] =='Iris_Virginica'),
'Sepal_Length'], color = 'b', shade = True, Label ='Iris_Virginica')
Вывод:
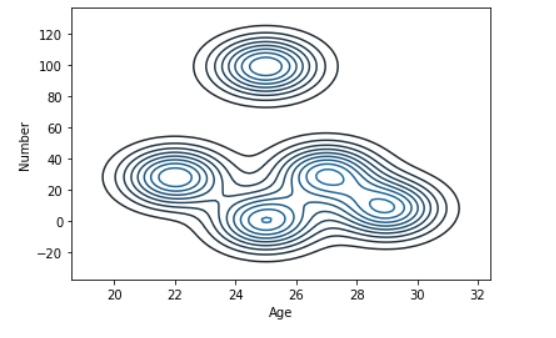
Пример 2: график KDE для функции возраста и числа
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Number'])
Вывод:
Двумерные и одномерные данные с использованием Seaborn
Давайте посмотрим пример Двумерных данных :
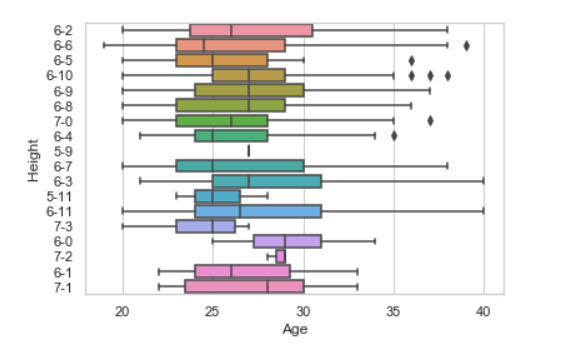
Пример 1: Использование прямоугольной диаграммы.
# import module
import seaborn as sns
import pandas
# read csv and plotting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'], data['Height'])
Вывод:
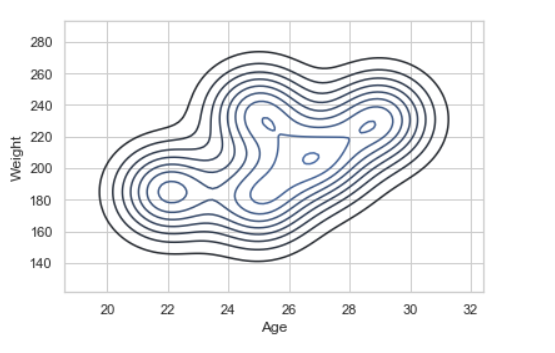
Пример 2: Высоздаете график KDE
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Weight'])
Вывод:
Давайте посмотрим пример одномерного распределения данных
Пример 1: Использование графика dist
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.distplot( data['Age'])
Вывод:
 Настройка графиков Seaborn с помощью Python
Настройка графиков Seaborn с помощью Python
Графики Seaborn можно широко настраивать для улучшения их удобочитаемости и эстетичности.
1. Изменение стиля и темы графика
Seaborn предлагает несколько встроенных тем, которые можно использовать для изменения общего вида графиков. Эти темы включают darkgrid, whitegrid, dark, white, и ticks.
import seaborn as sns
import matplotlib.pyplot as plt
# Set the style of the plots
sns.set_style("whitegrid")
# Example plot with the selected style
sns.boxplot(x='species', y='petal_length', data=sns.load_dataset('iris'))
plt.title('Petal Length Distribution by Species')
plt.show()
Вывод:

Изменение стиля и темы графика
2. Настройка цветовых палитр
Seaborn позволяет использовать различные цветовые палитры для повышения визуальной привлекательности ваших графиков. Вы можете использовать готовые палитры или создавать собственные.
# Set a custom color palette
custom_palette = sns.color_palette("husl", 8)
# Apply the custom palette
sns.set_palette(custom_palette)
# Example plot with the custom palette
sns.violinplot(x='species', y='petal_length', data=sns.load_dataset('iris'))
plt.title('Petal Length Distribution by Species')
plt.show()
Вывод:

Настройка цветовых палитр
3. Добавление заголовков и меток осей
Добавление описательных заголовков и меток к вашим графикам может сделать их более информативными.
# Adding title and labels
sns.scatterplot(x='sepal_length', y='sepal_width', data=sns.load_dataset('iris'))
plt.title('Sepal Length vs Sepal Width')
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.show()
Вывод:

Добавление заголовков и меток осей
4. Настройка размера рисунка и соотношения сторон
Вы можете изменить размер рисунка, чтобы он лучше подходил для ваших презентаций или отчётов.
# Adjust figure size
plt.figure(figsize=(10, 6))
# Example plot with adjusted figure size
sns.lineplot(x='year', y='passengers', data=sns.load_dataset('flights'))
plt.title('Number of Passengers Over Time')
plt.show()
Вывод:

Настройка размера рисунка и соотношения сторон
5. Добавление маркеров к линейным графикам
На линейные графики можно добавлять маркеры для выделения точек данных.
# Adding markers to a line plot
sns.lineplot(x='year', y='passengers', data=sns.load_dataset('flights'), marker='o')
plt.title('Number of Passengers Over Time')
plt.show()
Вывод:

Добавление маркеров к линейным графикам
Визуализация попарных связей с помощью Seaborn: парные графики
Пары диаграмм визуализируют взаимосвязи между переменными в наборе данных. Они отображают парные диаграммы рассеяния для всех комбинаций переменных, а также одномерные распределения по диагонали. Это полезно для изучения наборов данных с несколькими переменными и выявления потенциальных взаимосвязей. Отлично подходит для изучения закономерностей, взаимосвязей и распределений в наборах данных с несколькими числовыми переменными.
Синтаксис:
sns.pairplot(data, hue=None)
Пример:
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset("iris")
sns.pairplot(data, hue="species")
plt.show()
Вывод:

Парный график
Функция pairplot автоматически генерирует сетку точечных диаграмм, показывающих взаимосвязи между каждой парой признаков. Параметр hue добавляет цветовую кодировку на основе категориальных переменных, таких как виды в наборе данных Iris.
Совместные дистрибутивы с Seaborn: совместные графики
Совместные графики объединяют точечную диаграмму с распределениями отдельных переменных. Это позволяет быстро получить визуальное представление о том, как распределяются переменные по отдельности и как они связаны друг с другом.
Синтаксис:
sns.jointplot(x, y, data, kind='scatter')
Пример:
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset("tips")
sns.jointplot(x="total_bill", y="tip", data=data, kind="scatter")
plt.show()
Вывод:

Совместный сюжет
Это создает точечную диаграмму между total_bill и tip с гистограммами отдельных распределений по краям. Параметр kind можно установить на 'kde' для оценки плотности ядра или 'reg' для регрессионных диаграмм.
Понимание построения сетки с помощью Seaborn
Сетка в Seaborn — это эффективный способ визуализации данных по нескольким измерениям.
- Они позволяют создавать сетку графиков на основе подмножеств ваших данных, что упрощает сравнение различных групп или условий.
- Это особенно полезно при исследовательском анализе данных, когда вы хотите понять, как различные переменные взаимодействуют друг с другом в разных категориях.
Построение сетки, в частности, с использованием Seaborn's FacetGrid представляет собой многоплановую сетку, которая позволяет отображать функцию (например, график) на сетку вспомогательных графиков.
Создание многоплоскостных сеток с помощью FacetGrid от Seaborn
FacetGrid Seaborn — это мощный инструмент для визуализации данных, создающий сетку графиков на основе подмножеств вашего набора данных. Он особенно полезен для изучения сложных наборов данных с несколькими категориальными переменными. Ниже представлен подробный обзор FacetGrid и способов его эффективного использования.
Пример: Чтобы использовать FacetGrid, вам сначала нужно инициализировать его с помощью набора данных и указать переменные, которые будут формировать размеры строки, столбца или оттенка сетки. Вот пример использования tips dataset:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the example dataset
tips = sns.load_dataset("tips")
# Initialize the FacetGrid object
g = sns.FacetGrid(tips, col="time", row="sex")
Вывод:

Многоплановые сетки с помощью FacetGrid от Seaborn
Иллюстрирование регрессионных зависимостей с помощью Seaborn
Seaborn упрощает процесс выполнения и визуализации регрессий, в частности линейных регрессий, которые крайне важны для выявления взаимосвязей между переменными, определения тенденций и составления прогнозов.
- Seaborn предоставляет различные функции, которые позволяют визуализировать результаты регрессии, а также доверительные интервалы и остатки.
- Эта функция особенно полезна при изучении статистических данных, позволяя пользователям быстро понять линейную зависимость между переменными.
Seaborn поддерживает две основные функции для визуализации регрессии:
regplot(): Эта функция строит точечный график вместе с соответствием модели линейной регрессии.lmplot()Эта функция также строит графики линейных моделей, но обеспечивает большую гибкость при работе с несколькими аспектами и наборами данных.
Пример: Давайте используем простой набор данных для визуализации линейной регрессии между двумя переменными: x (независимая переменная) и y (зависимая переменная).
import seaborn as sns
import matplotlib.pyplot as plt
# Sample dataset
tips = sns.load_dataset('tips')
# Plot regression line
sns.regplot(x='total_bill', y='tip', data=tips, scatter_kws={'s':10}, line_kws={'color':'red'})
plt.show()
Вывод:

Reg Plot
Заключение
В заключение отметим, что Seaborn — это бесценный инструмент для визуализации данных, обеспечивающий простоту и глубину исследовательского анализа данных и статистической визуализации. Используя мощный высокоуровневый интерфейс Seaborn, специалисты по анализу данных могут создавать самые разные графики для выявления закономерностей, тенденций и взаимосвязей в своих данных. Изучая Seaborn, экспериментируйте с различными типами графиков, настройками и наборами данных, чтобы лучше понять, как наглядно представить свои выводы. Со временем Seaborn может стать ключевой частью вашего набора инструментов для анализа данных.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 11
Построение графика оценки плотности ядра (KDE) — это мощный инструмент для оценки функции плотности вероятности непрерывных или непараметрических данных. Построение графика KDE реализовано с помощью функции kdeplot в Seaborn. В этой статье рассматривается синтаксис и использование функции kdeplot в Python с акцентом на одномерные и двумерные сценарии для эффективной визуализации данных.
Содержание
- Что такое KDE plot?
- Как визуализировать график KDE с помощью Seaborn?
- График KDE для набора данных Iris
- Заключение
Что такое KDE plot?
Построение графика оценки плотности ядра (KDE) позволяет оценить функцию плотности вероятности непрерывной или непараметрической кривой из нашего набора данных в одном или нескольких измерениях. Это означает, что мы можем построить один график для нескольких выборок, что помогает более эффективно визуализировать данные.
Чтобы использовать модуль Seaborn, нам нужно установить его с помощью следующей команды:
!pip install seaborn
Синтаксис:
seaborn.kdeplot(x=None, *, y=None, vertical=False, palette=None, **kwargs)
Параметры:
x, y : векторы или ключи в данных
vertical : логическое значение (True или False)
data : pandas.DataFrame, numpy.ndarray, отображение или последовательность
Как визуализировать график KDE с помощью Seaborn?
Мы изучаем использование некоторых параметров на нескольких конкретных примерах:
Импорт библиотек
Сначала импортируйте соответствующую библиотеку
import pandas as pd
import seaborn as sb
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
Нарисуйте простое одномерное изображение kde:
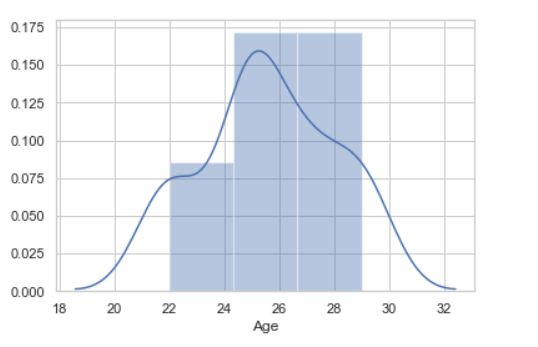
Давайте посмотрим на Kde для нашей переменной по оси X и по оси Y. Для этого передадим переменную x в метод kdeplot().
# data x and y axis for seaborn
x= np.random.randn(200)
y = np.random.randn(200)
# Kde for x var
sns.kdeplot(x)
Вывод:
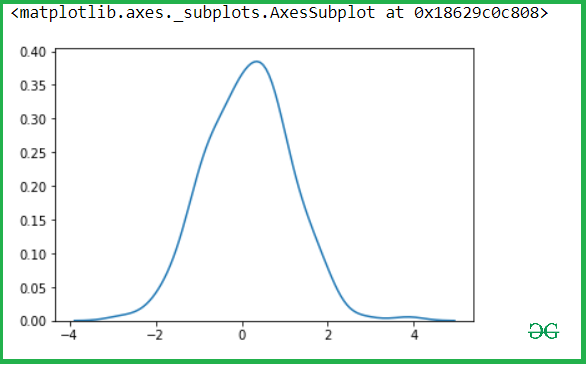
Затем после проверки наличия оси y.
sns.kdeplot(y)
Вывод:
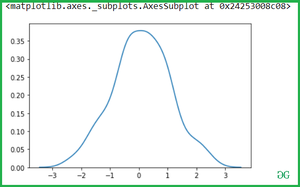
Используйте тень для заливки области, охватываемой кривой:
Мы можем выделить график, нанеся тень на область, покрытую кривой. Если значение равно True, обработка тени выполняется в области под кривой kde, а цвет определяет цвет кривой и тени.
sns.kdeplot(x, shade = True)
Вывод:
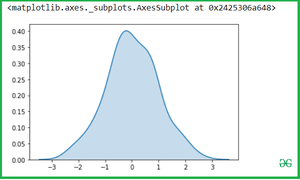
Вы можете изменить цвет оттенка с помощью атрибутов color:
sns.kdeplot(x, shade = True , color = "Green")
Вывод:
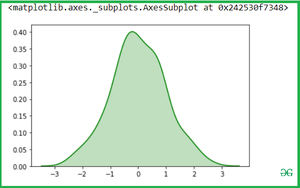
Используйте вертикальную линию для рисования, чтобы указать, нужно ли рисовать по оси X или по оси Y
sns.kdeplot(x, vertical = True)
Вывод:
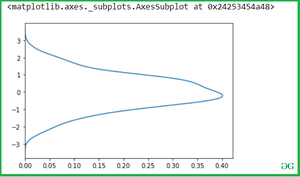
Создайте двумерный Kdeplot для двух переменных:
Просто передайте две переменные в метод seaborn.kdeplot().
sns.kdeplot(x,y)
Вывод:
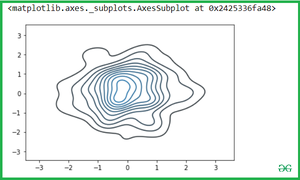
Затенение области, покрытой кривой, с помощью затенения атрибутов:
sns.kdeplot(x,y, shade = True)
Вывод:
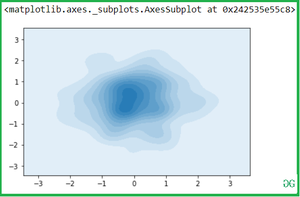
Теперь вы можете изменить цвет с помощью cmap атрибутов:
sns.kdeplot(x,y, cmap = "winter_r")
Вывод:
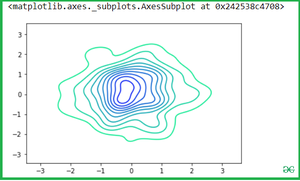
Использование Cbar: Если значение равно True, добавьте цветовую шкалу для обозначения цветового отображения на двумерном графике. Примечание: в настоящее время не поддерживает хорошо графики с переменной оттенка.
sns.kdeplot(x, y, shade=True, cbar=True)
Вывод:
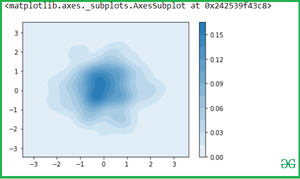
График KDE для набора данных Iris
Давайте рассмотрим пример с набором данных Iris, в котором для каждого столбца широкоформатного набора данных строится распределение:
Набор данных Iris состоит из 3 различных типов ирисов (Setosa, Versicolour и Virginica) с разной длиной лепестков и чашелистиков, сохранённых в массиве NumPy размером 150×4
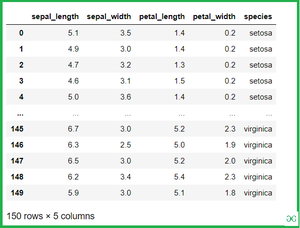
Загрузка набора данных iris для Kdeplot:
iris = sns.load_dataset('iris')
iris
Вывод:
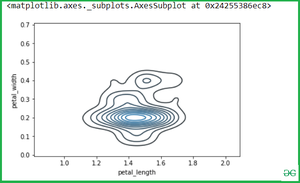
Двумерный Kdeplot для двух переменных iris:
Как только мы зададим виды, если мы захотим просто вычислить длину и ширину лепестков, то просто передадим две переменные (Setosa и virginica) в метод seaborn.kdeplot().
setosa = iris.loc[iris.species=="setosa"]
virginica = iris.loc[iris.species == "virginica"]
sns.kdeplot(setosa.petal_length, setosa.petal_width)
Вывод:
Рассмотрим другой пример, если мы хотим вычислить другой атрибут переменной — sepal_width и sepal_length.
sns.kdeplot(setosa.sepal_width, setosa.sepal_length)
Вывод:
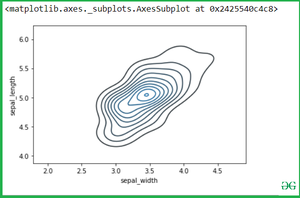
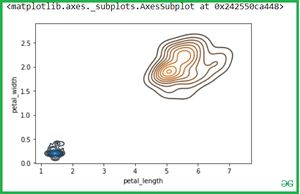
Если мы передадим два отдельных Kdeplot с разными переменными:
sns.kdeplot(setosa.petal_length, setosa.petal_width)
sns.kdeplot(virginica.petal_length, virginica.petal_width)
Вывод:
Заключение
Подводя итог, kdeplot Seaborn предлагает универсальный подход к визуализации функций плотности вероятности, который помогает исследовать одно или несколько измерений в наборах данных. Будь то затенение областей, настройка цветов или применение к реальным наборам данных, таким как Iris, kdeplot Seaborn является ценным инструментом для специалистов по обработке данных и аналитиков.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 14
3D-графика — это очень важные инструменты для визуализации данных с разными измерениями, например, данных с двумя зависимыми и одной независимой переменной.Построив 3D-графику, мы можем глубже понять данные с переменными состояниями.Для построения 3D-графиков можно использовать различные функции библиотеки matplotlib.
Пример построения трехмерных графиков с использованием Matplotlib
Сначала мы построим 3D-ось с помощью библиотеки Matplotlib. Для построения 3D-оси нам нужно просто изменить параметры проекции в plt.оси() с None в 3D.
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.axes(projection='3d')
Вывод:

Построение 3D-осей с использованием matplotlib
С помощью приведенного выше синтаксиса можно включить трехмерные оси и отображать данные в трех измерениях.Трехмерный график обеспечивает динамичный подход и делает данные более интерактивными.Как и в случае с двумерными графиками, мы можем использовать разные способы представления трёхмерных графиков.Мы можем переместить точечный график, контурный график, поверхностный график и т. д.Давайте рассмотрим различные трехмерные графики.
Графики с линиями и точками — это простейшие трехмерные графики.Мы будем использовать ax.plot3d и ax.scatter функции для построение линейного и точечного графиков соответственно.
Трехмерный линейный график использование Matplotlib
Для строительства трехмерного линейного графика мы будем использовать функцию mplot3d из библиотеки mpl_toolkits.Для построения линий в 3D нам необходимо создать три переменные точки для уравнения линии.В нашем случае мы определяем три переменных как х, у и z.
# importing mplot3d toolkits, numpy and matplotlib
from mpl_toolkits import mplot3d
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
# syntax for 3-D projection
ax = plt.axes(projection ='3d')
# defining all 3 axis
z = np.linspace(0, 1, 100)
x = z * np.sin(25 * z)
y = z * np.cos(25 * z)
# plotting
ax.plot3D(x, y, z, 'green')
ax.set_title('3D line plot geeks for geeks')
plt.show()
Выход:

3D линейный график с использованием библиотеки matplotlib
3-мерный рассеянный график с использованием Matplotlib
Для построения того же графика с использованием точек рассеяния мы воспользуемся функцией scatter() из matplotlib. Она построит то же уравнение прямой, используя другие точки.
# importing mplot3d toolkits
from mpl_toolkits import mplot3d
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
# syntax for 3-D projection
ax = plt.axes(projection ='3d')
# defining axes
z = np.linspace(0, 1, 100)
x = z * np.sin(25 * z)
y = z * np.cos(25 * z)
c = x + y
ax.scatter(x, y, z, c = c)
# syntax for plotting
ax.set_title('3d Scatter plot geeks for geeks')
plt.show()
Вывод:

Трехмерное построение точек с использованием библиотеки Matplotlib
Графики поверхности с использованием библиотеки Matplotlib
Поверхностные графики и каркасные графики работают с данными в виде сетки. Они берут значение сетки и отображают его на трёхмерной поверхности. Мы будем использовать функцию plot_surface() для построения поверхностного графика.
# importing libraries
from mpl_toolkits import mplot3d
import numpy as np
import matplotlib.pyplot as plt
# defining surface and axes
x = np.outer(np.linspace(-2, 2, 10), np.ones(10))
y = x.copy().T
z = np.cos(x ** 2 + y ** 3)
fig = plt.figure()
# syntax for 3-D plotting
ax = plt.axes(projection='3d')
# syntax for plotting
ax.plot_surface(x, y, z, cmap='viridis',\
edgecolor='green')
ax.set_title('Surface plot geeks for geeks')
plt.show()
Вывод:

Построение графиков поверхности с использованием библиотеки matplotlib
Построение каркасных графиков с использованием библиотеки Matplotlib
Для построения графика каркасных диаграмм мы будем использовать функцию plot_wireframe() из библиотеки matplotlib.
from mpl_toolkits import mplot3d
import numpy as np
import matplotlib.pyplot as plt
# function for z axis
def f(x, y):
return np.sin(np.sqrt(x ** 2 + y ** 2))
# x and y axis
x = np.linspace(-1, 5, 10)
y = np.linspace(-1, 5, 10)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
fig = plt.figure()
ax = plt.axes(projection ='3d')
ax.plot_wireframe(X, Y, Z, color ='green')
ax.set_title('wireframe geeks for geeks');
Вывод:

ТРЕХМЕРНЫЙ каркасный график с использованием библиотеки matplotlib
Контурные графики с использованием библиотеки Matplotlib
Контурный график принимает все входные данные в виде двумерных регулярных сеток, и данные Z вычисляются в каждой точке. Мы используем функцию ax.contour 3D для построения контурного графика. Контурные графики - отличный способ визуализации графиков оптимизации.
def function(x, y):
return np.sin(np.sqrt(x ** 2 + y ** 2))
x = np.linspace(-10, 10, 40)
y = np.linspace(-10, 10, 40)
X, Y = np.meshgrid(x, y)
Z = function(X, Y)
fig = plt.figure(figsize=(10, 8))
ax = plt.axes(projection='3d')
ax.plot_surface(X, Y, Z, cmap='cool', alpha=0.8)
ax.set_title('3D Contour Plot of function(x, y) =\
sin(sqrt(x^2 + y^2))', fontsize=14)
ax.set_xlabel('x', fontsize=12)
ax.set_ylabel('y', fontsize=12)
ax.set_zlabel('z', fontsize=12)
plt.show()
Вывод:

Трехмерное построение контура функции с использованием matplotlib
Построение триангуляций поверхности на Python
Приведённый выше график иногда слишком ограничен и неудобен. Поэтому в этом методе мы используем набор случайных значений. Функция ax.plot_trisurf используется для построения этого графика. Он не такой понятный, но более гибкий.
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.tri import Triangulation
def f(x, y):
return np.sin(np.sqrt(x ** 2 + y ** 2))
x = np.linspace(-6, 6, 30)
y = np.linspace(-6, 6, 30)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
tri = Triangulation(X.ravel(), Y.ravel())
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
ax.plot_trisurf(tri, Z.ravel(), cmap='cool', edgecolor='none', alpha=0.8)
ax.set_title('Surface Triangulation Plot of f(x, y) =\
sin(sqrt(x^2 + y^2))', fontsize=14)
ax.set_xlabel('x', fontsize=12)
ax.set_ylabel('y', fontsize=12)
ax.set_zlabel('z', fontsize=12)
plt.show()
Вывод:

График триангуляции поверхности контурного графика с использованием matplotlib
Построение полосы Мебиуса на Python
Лента Мёбиуса,также называемая скрученным цилиндром, представляет собой одностороннюю поверхность без границ. Чтобы создать ленту Мёбиуса, подумайте о её параметризации, это двумерная лента, и нам нужны два внутренних измерения. Её угол варьируется от 0 до 2 π вокруг петли, а ширина — от -1 до 1.
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# Define the parameters of the Möbius strip
R = 2
# Define the Möbius strip surface
u = np.linspace(0, 2*np.pi, 100)
v = np.linspace(-1, 1, 100)
u, v = np.meshgrid(u, v)
x = (R + v*np.cos(u/2)) * np.cos(u)
y = (R + v*np.cos(u/2)) * np.sin(u)
z = v * np.sin(u/2)
# Create the plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# Plot the Möbius strip surface
ax.plot_surface(x, y, z, alpha=0.5)
# Set plot properties
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
ax.set_title('Möbius Strip')
# Set the limits of the plot
ax.set_xlim([-3, 3])
ax.set_ylim([-3, 3])
ax.set_zlim([-3, 3])
# Show the plot
plt.show()
Вывод:

Построение полос Мебиуса с использованием библиотеки matplotlib
- Информация о материале
- Категория: Data Sciense
- Просмотров: 14
В этой статье мы расскажем о построении тепловых карт с помощью библиотеки matplotlib. Тепловая карта — отличный инструмент для визуализации данных на поверхности. Она выделяет данные с более высокой или более низкой концентрацией в распределении данных.
Тепловая карта
2D-тепловая карта — это инструмент визуализации данных, который помогает представить величину матрицы в виде цветной таблицы. В Python мы можем создавать 2D-тепловые карты, используя пакеты Matplotlib и Seaborn. Существуют различные методы построения 2D-тепловых карт, некоторые из которых обсуждаются ниже.
Примеры использования тепловых карт
Как мы знаем, тепловая карта — это просто цветное представление матрицы. Однако у тепловой карты очень широкий спектр применения. Мы можем использовать тепловые карты для следующих целей.
- Он используется для отображения корреляции между столбцами набора данных, где мы можем использовать более тёмный цвет для столбцов с высокой корреляцией.
- Мы также можем использовать тепловые карты для построения различных временных рядов и финансовых данных, где по оси Y будет отображаться месяц, по оси X — год, а элементом тепловой карты будут наши данные.
Базовая тепловая карта с использованием библиотеки Python Matplotlib
Здесь мы построим тепловую карту с помощью функции matplotlib.pyplot.imshow().
Синтаксис:
matplotlib.pyplot.imshow(X, cmap=None, alpha=None)
- X:- это матрица входных данных, которая должна отображаться
- cmap:- Colormap мы используем для отображения тепловой карты
- alpha : - определяет непрозрачность или прозрачность тепловой карты
# Program to plot 2-D Heat map
# using matplotlib.pyplot.imshow() method
import numpy as np
import matplotlib.pyplot as plt
data = np.random.random(( 12 , 12 ))
plt.imshow( data )
plt.title( "2-D Heat Map" )
plt.show()
Вывод:
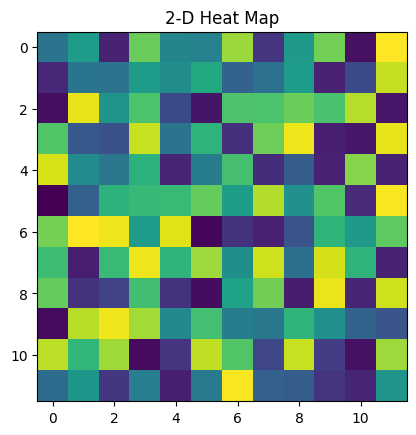
Hetamap из случайной матрицы 12 × 12
Выбор различных цветовых карт в Heatmap с помощью Matplotlib
Мы можем выбрать разные цвета для тепловой карты с помощью параметра cmap. cmap поможет нам сделать тепловую карту более информативной.
# Program to plot 2-D Heat map
# using matplotlib.pyplot.imshow() method
import numpy as np
import matplotlib.pyplot as plt
data = np.random.random((12, 12))
plt.imshow(data, cmap='autumn')
plt.title("Heatmap with different color")
plt.show()
Вывод:
.png)
тепловая карта с параметром camp
Добавление цветовой панели к тепловой карте с помощью Matplotlib
мы можем добавить цветовую шкалу к тепловой карте с помощью plt.colorbar(). Цветовая шкала показывает относительную интенсивность цвета в определённом диапазоне.
data = np.random.random((12, 12))
plt.imshow(data, cmap='autumn', interpolation='nearest')
# Add colorbar
plt.colorbar()
plt.title("Heatmap with color bar")
plt.show()
Вывод:
.png)
Тепловая карта с цветовой шкалой
Настраиваемая тепловая карта с использованием библиотеки Matplotlib
мы можем настроить эту тепловую карту, используя различные функции и параметры, чтобы сделать ее более информативной и красивой. мы будем использовать plt.annotate() для аннотирования значений в тепловой карте. Кроме того, мы будем использовать библиотеку цветов для настройки цвета тепловой карты.
import matplotlib.colors as colors
# Generate random data
data = np.random.randint(0, 100, size=(8, 8))
# Create a custom color map
# with blue and green colors
colors_list = ['#0099ff', '#33cc33']
cmap = colors.ListedColormap(colors_list)
# Plot the heatmap with custom colors and annotations
plt.imshow(data, cmap=cmap, vmin=0,\
vmax=100, extent=[0, 8, 0, 8])
for i in range(8):
for j in range(8):
plt.annotate(str(data[i][j]), xy=(j+0.5, i+0.5),
ha='center', va='center', color='white')
# Add colorbar
cbar = plt.colorbar(ticks=[0, 50, 100])
cbar.ax.set_yticklabels(['Low', 'Medium', 'High'])
# Set plot title and axis labels
plt.title("Customized heatmap with annotations")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
# Display the plot
plt.show()
Вывод:
.png)
заранее настроенная тепловая карта с использованием библиотеки matplotlib
Построение корреляционной матрицы набора данных с использованием тепловой карты
Далее мы построим тепловую карту для отображения корреляции между столбцами набора данных. Мы будем использовать корреляцию для поиска взаимосвязи между столбцами набора данных.
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import colors
df = pd.read_csv("gold_price_data.csv")
# Calculate correlation between columns
corr_matrix = df.corr()
# Create a custom color
# map with blue and green colors
colors_list = ['#FF5733', '#FFC300']
cmap = colors.ListedColormap(colors_list)
# Plot the heatmap with custom colors and annotations
plt.imshow(corr_matrix, cmap=cmap, vmin=0\
, vmax=1, extent=[0, 5, 0, 5])
for i in range(5):
for j in range(5):
plt.annotate(str(round(corr_matrix.values[i][j], 2)),\
xy=(j+0.25, i+0.7),
ha='center', va='center', color='white')
# Add colorbar
cbar = plt.colorbar(ticks=[0, 0.5, 1])
cbar.ax.set_yticklabels(['Low', 'Medium', 'High'])
# Set plot title and axis labels
plt.title("Correlation Matrix Of The Dataset")
plt.xlabel("Features")
plt.ylabel("Features")
# Set tick labels
plt.xticks(range(len(corr_matrix.columns)),\
corr_matrix.columns, rotation=90)
plt.yticks(range(len(corr_matrix.columns)),
corr_matrix.columns)
# Display the plot
plt.show()
Вывод:
.png)
Корреляционная матрица набора данных
Тепловая карта с использованием библиотеки Seaborn
Мы также можем использовать библиотеку Seaborn для построения тепловых карт, причём построение тепловых карт с помощью Seaborn сравнительно проще, чем с помощью библиотеки matplotlib. Чтобы построить тепловую карту с помощью Seaborn, мы будем использовать функцию sns.heatmap() из библиотеки Seaborn.
# importing the modules
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# generating 2-D 10x10 matrix of random numbers
# from 1 to 100
data = np.random.randint(low=1,
high=100,
size=(10, 10))
# plotting the heatmap
hm = sns.heatmap(data=data,
annot=True)
# displaying the plotted heatmap
plt.show()
Вывод:
.png)
- Информация о материале
- Категория: Data Sciense
- Просмотров: 24