Визуализация данных является важнейшим аспектом анализа данных, позволяя специалистам по данным и аналитикам представлять сложные данные в более понятной и содержательной форме. Одной из самых популярных библиотек для визуализации данных в Python является Matplotlib. В этой статье мы предоставим полное руководство по использованию Matplotlib для создания различных типов графиков и их настройки в соответствии с конкретными потребностями, а также по визуализации данных с помощью библиотеки Matplotlib в Python.
Содержание
- Начало работы с Matplotlib
- Установка Matplotlib для визуализации данных
- Предварительный просмотр данных с помощью Pyplot в Matplotlib
- Базовое построение графиков с помощью Matplotlib: пошаговые примеры
- Руководство по настройке и стилю Matplotlib
- Понимание основных компонентов Matplotlib: фигуры и осей
- Расширенное построение графиков: методы визуализации вложенных графиков
- Сохранение графиков Matplotlib с помощью savefig()
Начало работы с Мatplotlib
Matplotlib — это универсальная и широко используемая библиотека визуализации данных на Python.Она позволяет пользователям создавать статические, интерактивные и анимированные изображения.
Библиотека построена на основе NumPy, что делает ее эффективной для работы с наборами заданных данных. Эта библиотека построена на основе массивов NumPy и состоит из нескольких графиков, таких как линейная диаграмма, гистограмма и т. д. Она обеспечивает большую гибкость, но требует написания большего количества кода.
Установка Matplotlib для визуализации данных
Мы будем использовать команду pip для установки этого модуля.Если у вас не установлен пункт, обратитесь к статье. Загрузите и установите полную версию pip.
Чтобы установить Matplotlib, введите в терминале приведенную ниже команду.
pip установить matplotlib
Мы также можем установить matplotlib в Jupyter Notebook и Google Colab с помощью той же команды:

Установка Matplotlib для визуализации данных
Если вы используете Jupyter Notebook, вы можете установить его в ячейку блокнота с помощью:
!pip установить matplotlib
Data Visualization With Pyplot in Matplotlib
Matplotlib предоставляет модуль под названием pyplot, который предлагает интерфейс, похожий на MATLAB, для создания графиков и диаграмм. Этот процесс создания различных типов визуализации включает набор функций, которые выполняют распространённые задачи по построению графиков.каждая функция в Pyplot изменяет фигуру определенным образом, например:
Ключевые функции Pyplot:
| Category | Function | Description |
|---|---|---|
| Plot Creation | plot() | Creates line plots with customizable styles. |
| scatter() | Generates scatter plots to visualize relationships. | |
| Graphical Elements | bar() | Creates bar charts for comparing categories. |
| hist() | Draws histograms to show data distribution. | |
| pie() | Creates pie charts to represent parts of a whole. | |
| Customization | xlabel(), ylabel() | Sets labels for the X and Y axes. |
| title() | Adds a title to the plot. | |
| legend() | Adds a legend to differentiate data series. | |
| Visualization Control | xlim(), ylim() | Sets limits for the X and Y axes. |
| grid() | Adds gridlines to the plot for readability. | |
| show() | Displays the plot in a window. | |
| Figure Management | figure() | Creates or activates a figure. |
| subplot() | Creates a grid of subplots within a figure. | |
| savefig() | Saves the current figure to a file. |
Базовое построение графиков с помощью Matplotlib: пошаговые примеры
Matplotlib поддерживает различные графики, включая линейные диаграммы, столбчатые диаграммы, гистограммы, диаграммы рассеяния и т. д. В этой статье мы обсудим наиболее часто используемые диаграммы на нескольких хороших примерах, а также рассмотрим, как настроить каждый график.
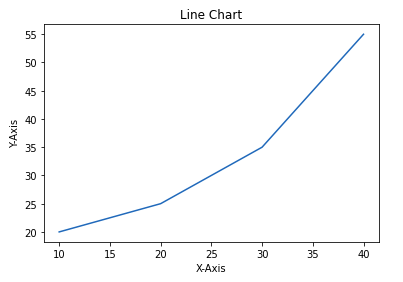
1. Линейный график
Линейная диаграмма является одним из основных графиков и может быть создана с помощью функции plot() Она используется для представления взаимосвязи между двумя наборами данных X и Y на разных осях.
Синтаксис:
matplotlib.pyplot.plot(\*args, scalex=True, scaley=True, data=None, \*\*kwargs)
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# plotting the data
plt.plot(x, y)
# Adding title to the plot
plt.title("Line Chart")
# Adding label on the y-axis
plt.ylabel('Y-Axis')
# Adding label on the x-axis
plt.xlabel('X-Axis')
plt.show()Выход:
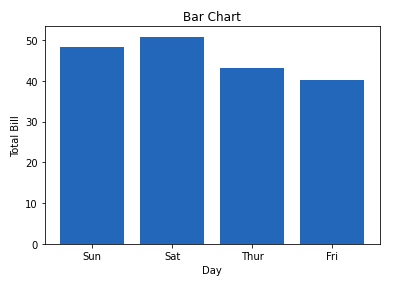
2. Столбчатая диаграмма
Столбчатая диаграмма — это график, представляющий категорию данных с помощью прямоугольных столбцов, длина и высота которых пропорциональны значениям, которые они представляют. Столбчатые диаграммы могут быть построены горизонтально или вертикально. Столбчатая диаграмма описывает сравнения между дискретными категориями. Ее можно создать с помощью метода bar().
В примере ниже мы будем использовать набор данных о чаевых. База данных о чаевых — это запись о чаевых, оставленных клиентами ресторана за два с половиной месяца в начале 1990-х годов. Она содержит 6 столбцов: общая сумма счёта, чаевые, пол, официант, день, время, размер.
Пример:
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
x = data['day']
y = data['total_bill']
# plotting the data
plt.bar(x, y)
# Adding title to the plot
plt.title("Tips Dataset")
# Adding label on the y-axis
plt.ylabel('Total Bill')
# Adding label on the x-axis
plt.xlabel('Day')
plt.show()
Выход:
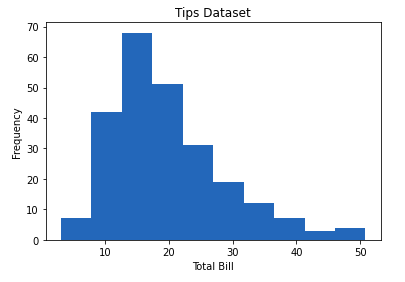
3. Гистограмма
Гистограмма в В основном используется для представления данных, представленных в виде некоторых групп. Это тип столбчатой диаграммы, где ось X представляет диапазоны бинов, а ось Y даёт информацию о частоте. Функция hist() используется для вычисления и создания гистограммы x.
Синтаксис:
matplotlib.pyplot.hist(x, bins=None, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype=’bar’, align=’mid’, orientation=’vertical’, rwidth=None, log=False, color=None, label=None, stacked=False, \*, data=None, \*\*kwargs)
Пример:
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
x = data['total_bill']
# plotting the data
plt.hist(x)
# Adding title to the plot
plt.title("Tips Dataset")
# Adding label on the y-axis
plt.ylabel('Frequency')
# Adding label on the x-axis
plt.xlabel('Total Bill')
plt.show()
Выход:
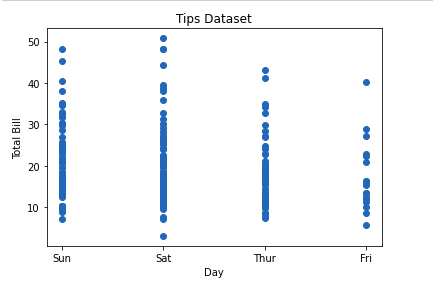
4. Диаграмма рассеяния
Диаграммы рассеяния используются для наблюдения за отношениями между переменными. Метод scatter() в библиотеке matplotlib используется для построения диаграммы рассеяния.
Синтаксис:
matplotlib.pyplot.scatter(x_axis_data, y_axis_data, s=None, c=None, marker=None, cmap=None, vmin=None, vmax=None, alpha=None, linewidths=None, edgecolors=None
Пример:
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
x = data['day']
y = data['total_bill']
# plotting the data
plt.scatter(x, y)
# Adding title to the plot
plt.title("Tips Dataset")
# Adding label on the y-axis
plt.ylabel('Total Bill')
# Adding label on the x-axis
plt.xlabel('Day')
plt.show()
Выход:
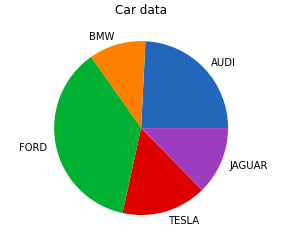
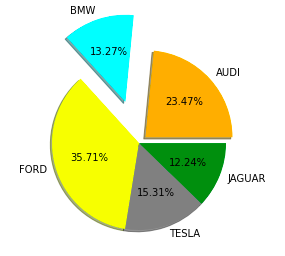
5. Круговая диаграмма
Круговая диаграммаЭта круговая диаграмма используется для отображения только одного ряда данных.Площадь срезов круга представляет собой процентное соотношение частей данных.Кусочки пирога называются клиньями.Его можно создать с помощью метода pie().
Синтаксис:
matplotlib.pyplot.pie(data, explode=None, labels=None, colors=None, autopct=None, shadow=False)
Пример:
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
cars = ['AUDI', 'BMW', 'FORD',
'TESLA', 'JAGUAR',]
data = [23, 10, 35, 15, 12]
# plotting the data
plt.pie(data, labels=cars)
# Adding title to the plot
plt.title("Car data")
plt.show()
Выход:
6. Диаграмма ящиков
Ящичковая диаграмма, также известная как диаграмма «усы», — это стандартизированный способ отображения распределения данных на основе сводки из пяти чисел: минимум, первый квартиль (Q1), медиана (Q2), третий квартиль (Q3) и максимум. Она также может отображать выбросы.
Давайте рассмотрим пример создания диаграммы с использованием Matplotlib в Python:
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(10)
data = [np.random.normal(0, std, 100) for std in range(1, 4)]
# Create a box plot
plt.boxplot(data, vert=True, patch_artist=True,
boxprops=dict(facecolor='skyblue'),
medianprops=dict(color='red'))
plt.xlabel('Data Set')
plt.ylabel('Values')
plt.title('Example of Box Plot')
plt.show()
Выход:

Диаграмма ящиков в Python с использованием Matplotlib
Объяснение:
plt.boxplot(data): Создает диаграмму ящиков . Аргументvert=Trueделает диаграмму вертикальной иpatch_artist=Trueзаполняет ящик цветом.boxpropsиmedianprops: Настройте внешний вид полей и срединных линий соответственно.
Прямоугольник показывает межквартильный размах (IQR), линия внутри прямоугольника показывает медиану, а «усы» простираются до минимальных и максимальных значений в пределах 1,5 * IQR от первого и третьего квартилей. Любые точки за пределами этого диапазона считаются выбросами и отображаются как отдельные точки.
7. Тепловая карта
Тепловая карта — это метод визуализации данных, который представляет данные в матричной форме, где отдельные значения представлены в виде цветов. Тепловые карты особенно полезны для визуализации величины данных на двумерной поверхности и выявления закономерностей, корреляций и концентраций.
Давайте рассмотрим пример создания тепловой карты с использованием Matplotlib в Python:
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(0)
data = np.random.rand(10, 10)
# Create a heatmap
plt.imshow(data, cmap='viridis', interpolation='nearest')
# Add a color bar to show the scale
plt.colorbar()
plt.xlabel('X-axis Label')
plt.ylabel('Y-axis Label')
plt.title('Example of Heatmap')
plt.show()
Объяснение:
plt.imshow(data, cmap='viridis'): Отображает данные в виде изображения (тепловой карты). Аргументcmap='viridis'определяет цветовую карту, используемую для тепловой карты.interpolation='nearest': Обеспечивает отображение каждой точки данных в виде цветного блока без сглаживания.
Цветовая шкала сбоку позволяет интерпретировать цвета: более тёмные цвета обозначают меньшие значения, а более светлые — большие. Этот тип графика часто используется в таких областях, как анализ данных, биоинформатика и финансы, для визуализации корреляций и распределений данных в матрице.
Руководство по настройке и стилю Matplotlib
Matplotlib позволяет настраивать графики по своему усмотрению, в том числе менять цвета, добавлять подписи и изменять стили графиков.
1. Добавление заголовка
Метод title() в модуле matplotlib используется для указания заголовка отображаемой визуализации и отображает заголовок с помощью различных атрибутов.
Синтаксис:
matplotlib.pyplot.title(label, fontdict=None, loc=’center’, pad=None, **kwargs)
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# plotting the data
plt.plot(x, y)
# Adding title to the plot
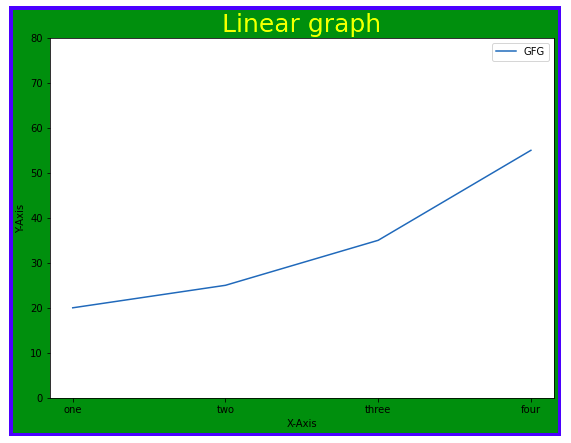
plt.title("Linear graph")
plt.show()
Вывод:
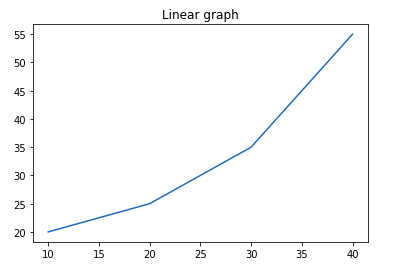
Мы также можем изменить внешний вид заголовка, используя параметры этой функции.
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# plotting the data
plt.plot(x, y)
# Adding title to the plot
plt.title("Linear graph", fontsize=25, color="green")
plt.show()
2. Добавление меток X и Y
Проще говоря, метка X и метка Y — это названия осей X и Y соответственно. Их можно добавить на график с помощью методов xlabel() и ylabel() .
Синтаксис:
matplotlib.pyplot.xlabel(xlabel, fontdict=None, labelpad=None, **kwargs)
matplotlib.pyplot.ylabel(ylabel, fontdict=None, labelpad=None, **kwargs)
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# plotting the data
plt.plot(x, y)
# Adding title to the plot
plt.title("Linear graph", fontsize=25, color="green")
# Adding label on the y-axis
plt.ylabel('Y-Axis')
# Adding label on the x-axis
plt.xlabel('X-Axis')
plt.show()
Вывод:
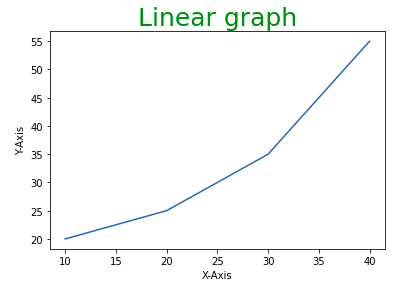
3. Установка ограничений и меток
Возможно, вы заметили, что Matplotlib автоматически устанавливает значения и маркеры (точки) на осях X и Y, однако можно установить ограничения и маркеры вручную.
- Функции xlim() и ylim() используются для установки пределов оси X и оси Y соответственно.
- Аналогичным образом, функции xticks() и yticks() используются для установки меток тиков.
Пример: В этом примере мы изменим предел оси Y и установим метки для оси X.
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# plotting the data
plt.plot(x, y)
# Adding title to the plot
plt.title("Linear graph", fontsize=25, color="green")
# Adding label on the y-axis
plt.ylabel('Y-Axis')
# Adding label on the x-axis
plt.xlabel('X-Axis')
# Setting the limit of y-axis
plt.ylim(0, 80)
# setting the labels of x-axis
plt.xticks(x, labels=["one", "two", "three", "four"])
plt.show()
Вывод:
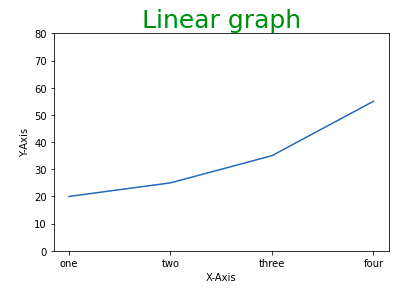
4. Добавление условных обозначений
Легенда — это область, описывающая элементы графика. Проще говоря, она отражает данные, отображаемые на оси Y графика. Обычно она выглядит как прямоугольник, содержащий небольшую выборку каждого цвета на графике и краткое описание этих данных.
Атрибут bbox_to_anchor=(x, y) функции legend() используется для указания координат легенды, а атрибут ncol обозначает количество столбцов в легенде. Его значение по умолчанию равно 1.
Синтаксис:
matplotlib.pyplot.legend([“name1”, “name2”], bbox_to_anchor=(x, y), ncol=1)
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# plotting the data
plt.plot(x, y)
# Adding title to the plot
plt.title("Linear graph", fontsize=25, color="green")
# Adding label on the y-axis
plt.ylabel('Y-Axis')
# Adding label on the x-axis
plt.xlabel('X-Axis')
# Setting the limit of y-axis
plt.ylim(0, 80)
# setting the labels of x-axis
plt.xticks(x, labels=["one", "two", "three", "four"])
# Adding legends
plt.legend(["GFG"])
plt.show()
Вывод:
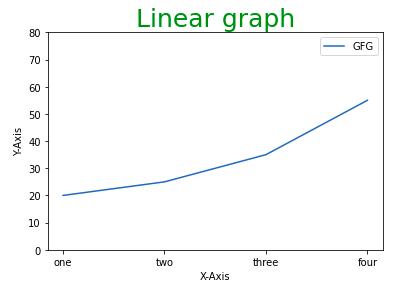
Давайте применим изученные нами методы настройки к базовым графикам, которые мы создали ранее. Это позволит дополнить каждый график заголовками, метками осей, пределами, метками тиков и легендами, чтобы сделать их более информативными и визуально привлекательными.
-> Настройка линейной диаграммы
Давайте посмотрим, как настроить созданную выше линейчатую диаграмму. Мы будем использовать следующие свойства:
- color: Изменение цвета строки
- linewidth: Настройка ширины линии
- marker: Для изменения стиля фактической нанесенной точки
- markersize: Для изменения размера маркеров
- linestyle: Для определения стиля отображаемой линии
Доступны различные стили строкe
|
Character |
Definition |
|---|---|
|
– |
Solid line |
|
— |
Dashed line |
|
-. |
dash-dot line |
|
: |
Dotted line |
|
. |
Point marker |
|
o |
Circle marker |
|
, |
Pixel marker |
|
v |
triangle_down marker |
|
^ |
triangle_up marker |
|
< |
triangle_left marker |
|
> |
triangle_right marker |
|
1 |
tri_down marker |
|
2 |
tri_up marker |
|
3 |
tri_left marker |
|
4 |
tri_right marker |
|
s |
square marker |
|
p |
pentagon marker |
|
* |
star marker |
|
h |
hexagon1 marker |
|
H |
hexagon2 marker |
|
+ |
Plus marker |
|
x |
X marker |
|
D |
Diamond marker |
|
d |
thin_diamond marker |
|
| |
vline marker |
|
_ |
hline marker |
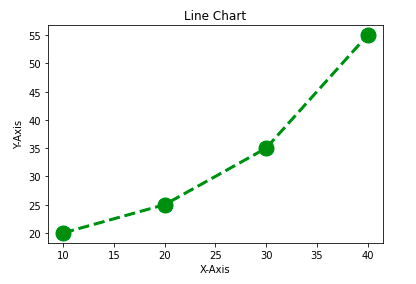
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# plotting the data
plt.plot(x, y, color='green', linewidth=3, marker='o',
markersize=15, linestyle='--')
# Adding title to the plot
plt.title("Line Chart")
# Adding label on the y-axis
plt.ylabel('Y-Axis')
# Adding label on the x-axis
plt.xlabel('X-Axis')
plt.show()
Вывод:
-> Настройка гистограммы
Чтобы сделать гистограммы более информативными и визуально привлекательными, доступны различные параметры настройки. Для настройки гистограммы доступны следующие параметры:
- color: Для штриховых граней
- edgecolor: Цвет краев панели
- linewidth: Ширина краев полосы
- width: Ширина полосы
Пример:
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
x = data['day']
y = data['total_bill']
# plotting the data
plt.bar(x, y, color='green', edgecolor='blue',
linewidth=2)
# Adding title to the plot
plt.title("Tips Dataset")
# Adding label on the y-axis
plt.ylabel('Total Bill')
# Adding label on the x-axis
plt.xlabel('Day')
plt.show()
Вывод:
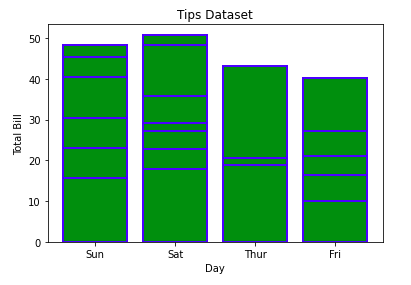
Note: The lines in between the bars refer to the different values in the Y-axis of the particular value of the X-axis.
-> Настройка графика гистограммы
Чтобы сделать гистограммы более эффективными и адаптированными к вашим данным, вы можете применить различные настройки:
- bins: Количество ячеек одинаковой ширины
- color: Для изменения цвета лица
- edgecolor: Цвет ребер
- linestyle: Для линий по краям
- alpha: Значение наложения, от 0 (прозрачный) до 1 (непрозрачный)
Пример:
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
x = data['total_bill']
# plotting the data
plt.hist(x, bins=25, color='green', edgecolor='blue',
linestyle='--', alpha=0.5)
# Adding title to the plot
plt.title("Tips Dataset")
# Adding label on the y-axis
plt.ylabel('Frequency')
# Adding label on the x-axis
plt.xlabel('Total Bill')
plt.show()
Вывод:
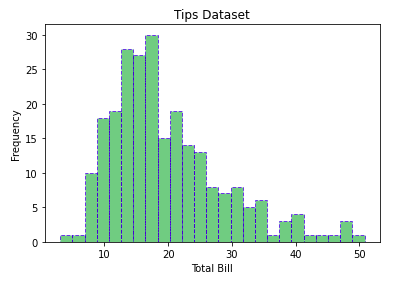
-> Настройка точечной диаграммы
Точечные диаграммы — это универсальные инструменты для визуализации взаимосвязей между двумя переменными. Настройки, доступные для точечных диаграмм, повышают их наглядность и эффективность:
- s: размер маркера (может быть скаляром или массивом размером, равным размеру x или y)
- c: цвет последовательности цветов для маркеров
- marker: Стиль маркера
- linewidths: ширина границы маркера
- edgecolor: цвет границы маркера
- alpha: значение наложения, от 0 (прозрачный) до 1 (непрозрачный)
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
x = data['day']
y = data['total_bill']
# plotting the data
plt.scatter(x, y, c=data['size'], s=data['total_bill'],
marker='D', alpha=0.5)
# Adding title to the plot
plt.title("Tips Dataset")
# Adding label on the y-axis
plt.ylabel('Total Bill')
# Adding label on the x-axis
plt.xlabel('Day')
plt.show()
Вывод:
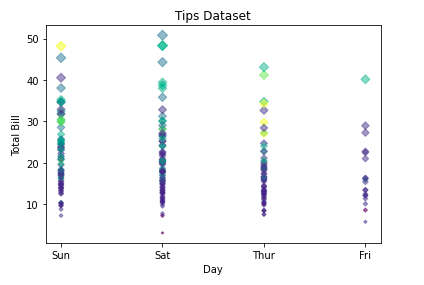
-> Настройка круговой диаграммы
Круговые диаграммы — отличный способ наглядно представить пропорции и части целого. Чтобы сделать круговые диаграммы более эффективными и визуально привлекательными, воспользуйтесь следующими методами настройки:
- explode: перемещение клиньев графика
- autocct: Обозначьте клин их числовым значением.
- color: Атрибут используется для придания цвета фрагментам.
- shadow: используется для создания тени клина.
Пример:
import matplotlib.pyplot as plt
import pandas as pd
# Reading the tips.csv file
data = pd.read_csv('tips.csv')
# initializing the data
cars = ['AUDI', 'BMW', 'FORD',
'TESLA', 'JAGUAR',]
data = [23, 13, 35, 15, 12]
explode = [0.1, 0.5, 0, 0, 0]
colors = ( "orange", "cyan", "yellow",
"grey", "green",)
# plotting the data
plt.pie(data, labels=cars, explode=explode, autopct='%1.2f%%',
colors=colors, shadow=True)
plt.show()
Вывод:
Понимание основных компонентов Matplotlib: фигур и осей
Прежде чем продолжить работу с Matplotlib, давайте обсудим некоторые важные классы, которые будут использоваться в дальнейшем в этом руководстве. К этим классам относятся:
- Рисунок
- Оси
Примечание: Matplotlib позаботится о создании встроенных элементов по умолчанию, таких как Figure и Axes.
1. Класс Figure
Представьте, что класс figure — это общее окно или страница, на которой всё рисуется. Это контейнер верхнего уровня, содержащий одну или несколько осей. Фигуру можно создать с помощью метода figure().
Синтаксис:
class matplotlib.figure.Figure(figsize=None, dpi=None, facecolor=None, edgecolor=None, linewidth=0.0, frameon=None, subplotpars=None, tight_layout=None, constrained_layout=None)
Пример:
# Python program to show pyplot module
import matplotlib.pyplot as plt
from matplotlib.figure import Figure
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# Creating a new figure with width = 7 inches
# and height = 5 inches with face color as
# green, edgecolor as red and the line width
# of the edge as 7
fig = plt.figure(figsize =(7, 5), facecolor='g',
edgecolor='b', linewidth=7)
# Creating a new axes for the figure
ax = fig.add_axes([1, 1, 1, 1])
# Adding the data to be plotted
ax.plot(x, y)
# Adding title to the plot
plt.title("Linear graph", fontsize=25, color="yellow")
# Adding label on the y-axis
plt.ylabel('Y-Axis')
# Adding label on the x-axis
plt.xlabel('X-Axis')
# Setting the limit of y-axis
plt.ylim(0, 80)
# setting the labels of x-axis
plt.xticks(x, labels=["one", "two", "three", "four"])
# Adding legends
plt.legend(["GFG"])
plt.show()
Вывод:
2. Класс Axes
Класс Axes является наиболее базовым и гибким модулем для создания вспомогательных графиков. Один рисунок может содержать несколько осей, но одна ось может присутствовать только на одном рисунке. Функция axes() создает объект осей.
Синтаксис:
axes([left, bottom, width, height])
Как и класс pyplot, класс axes также предоставляет методы для добавления заголовков, легенд, ограничений, меток и т. д. Давайте рассмотрим некоторые из них.
- Добавление заголовка – ax.set_title()
- Добавление метки X и метки Y — ax.set_xlabel(), ax.set_ylabel()
- Установка пределов — ax.set_xlim(), ax.set_ylim()
- Метки тиков — ax.set_xticklabels(), ax.set_yticklabels()
- Добавление условных обозначений – ax.legend()
Пример:
# Python program to show pyplot module
import matplotlib.pyplot as plt
from matplotlib.figure import Figure
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
fig = plt.figure(figsize = (5, 4))
# Adding the axes to the figure
ax = fig.add_axes([1, 1, 1, 1])
# plotting 1st dataset to the figure
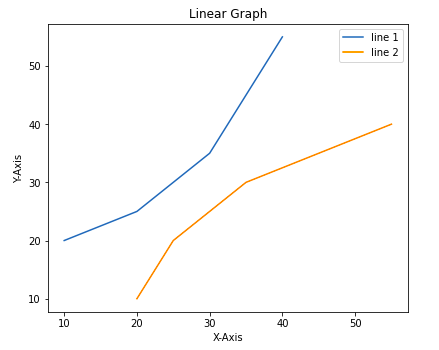
ax1 = ax.plot(x, y)
# plotting 2nd dataset to the figure
ax2 = ax.plot(y, x)
# Setting Title
ax.set_title("Linear Graph")
# Setting Label
ax.set_xlabel("X-Axis")
ax.set_ylabel("Y-Axis")
# Adding Legend
ax.legend(labels = ('line 1', 'line 2'))
plt.show()
Вывод:
Расширенное построение графиков: методы визуализации вложенных графиков
Мы узнали об основных компонентах графика, которые можно добавить, чтобы он передавал больше информации. Один из способов — снова и снова вызывать функцию построения графика с другим набором значений, как показано в приведённом выше примере. Теперь давайте посмотрим, как построить несколько графиков с помощью некоторых функций, а также как построить подзаголовки.
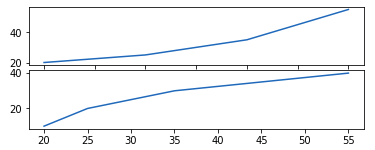
Способ 1: Использование метода add_axes()
Метод add_axes() используется для добавления осей на рисунок. Это метод класса figure
Синтаксис:
add_axes(self, *args, **kwargs)
Пример:
# Python program to show pyplot module
import matplotlib.pyplot as plt
from matplotlib.figure import Figure
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# Creating a new figure with width = 5 inches
# and height = 4 inches
fig = plt.figure(figsize =(5, 4))
# Creating first axes for the figure
ax1 = fig.add_axes([0.1, 0.1, 0.8, 0.8])
# Creating second axes for the figure
ax2 = fig.add_axes([1, 0.1, 0.8, 0.8])
# Adding the data to be plotted
ax1.plot(x, y)
ax2.plot(y, x)
plt.show()
Вывод:
Метод 2: С помощью subplot() метод
Этот метод добавляет еще один график в указанном положении сетки на текущем рисунке.
Синтаксис:
subplot(nrows, ncols, index, **kwargs)
subplot(pos, **kwargs)
subplot(ax)
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# Creating figure object
plt.figure()
# adding first subplot
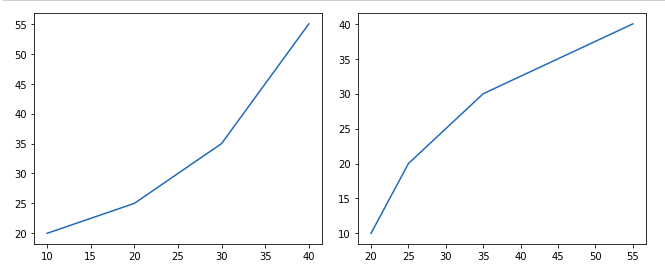
plt.subplot(121)
plt.plot(x, y)
# adding second subplot
plt.subplot(122)
plt.plot(y, x)
Вывод:
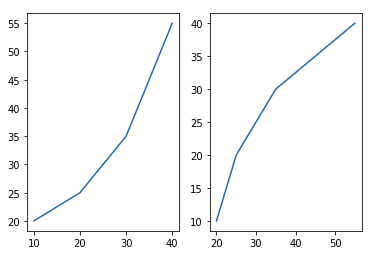
Метод 3: С помощью subplots() метод
Эта функция используется для одновременного создания фигур и нескольких вспомогательных графиков.
Синтаксис:
matplotlib.pyplot.subplots(nrows=1, ncols=1, sharex=False, sharey=False, squeeze=True, subplot_kw=None, gridspec_kw=None, **fig_kw)
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# Creating the figure and subplots
# according the argument passed
fig, axes = plt.subplots(1, 2)
# plotting the data in the
# 1st subplot
axes[0].plot(x, y)
# plotting the data in the 1st
# subplot only
axes[0].plot(y, x)
# plotting the data in the 2nd
# subplot only
axes[1].plot(x, y)
Вывод:
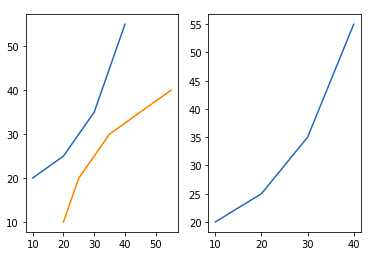
Способ 4: Использование метода subplot2grid()
Эта функция создаёт объект осей в указанном месте внутри сетки, а также помогает растянуть объект осей на несколько строк или столбцов. Проще говоря, эта функция используется для создания нескольких диаграмм на одном рисунке.
Синтаксис:
Plt.subplot2grid(shape, location, rowspan, colspan)
Пример:
import matplotlib.pyplot as plt
# initializing the data
x = [10, 20, 30, 40]
y = [20, 25, 35, 55]
# adding the subplots
axes1 = plt.subplot2grid (
(7, 1), (0, 0), rowspan = 2, colspan = 1)
axes2 = plt.subplot2grid (
(7, 1), (2, 0), rowspan = 2, colspan = 1)
# plotting the data
axes1.plot(x, y)
axes2.plot(y, x)
Вывод:
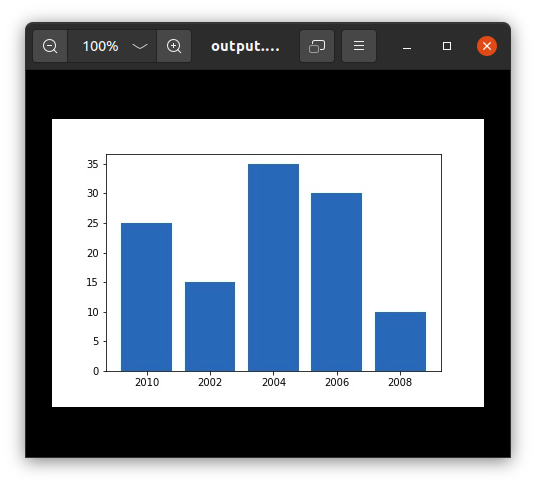
Сохранение графиков Matplotlib с использованием savefig()
Для сохранения графика в файле на диске используется метод savefig(). Файл можно сохранить во многих форматах, таких как .png, .jpg, .pdf и т. д.
Синтаксис:
pyplot.savefig(fname, dpi=None, facecolor=’w’, edgecolor=’w’, orientation=’portrait’, papertype=None, format=None, transparent=False, bbox_inches=None, pad_inches=0.1, frameon=None, metadata=None)
Пример:
import matplotlib.pyplot as plt
# Creating data
year = ['2010', '2002', '2004', '2006', '2008']
production = [25, 15, 35, 30, 10]
# Plotting barchart
plt.bar(year, production)
# Saving the figure.
plt.savefig("output.jpg")
# Saving figure by changing parameter values
plt.savefig("output1", facecolor='y', bbox_inches="tight",
pad_inches=0.3, transparent=True)
Вывод:
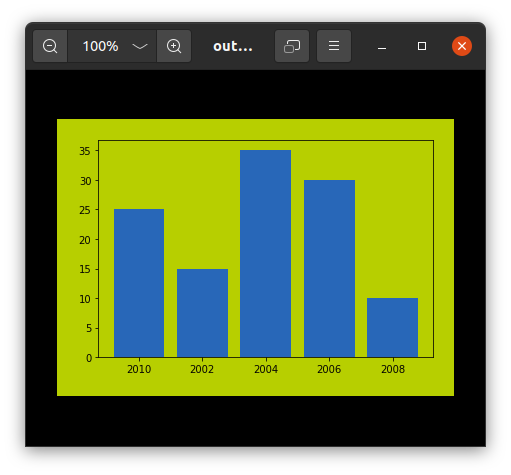
Заключение
В этом руководстве мы рассмотрели основы Matplotlib, от установки до продвинутых методов построения графиков. Освоив эти концепции, вы сможете создавать и настраивать широкий спектр визуализаций для эффективного представления данных. Независимо от того, работаете ли вы с простыми линейными диаграммами или сложными тепловыми картами, Matplotlib предоставляет инструменты, необходимые для оживления ваших данных.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 16
Визуализация данных — это графическое представление информации и данных. С помощью визуальных элементов, таких как диаграммы, графики и карты, инструменты визуализации данных позволяют наглядно увидеть и понять тенденции, отклонения и закономерности в данных.

Эта практика имеет решающее значение в процессе обработки данных, поскольку она помогает сделать данные более понятными и пригодными для использования широким кругом пользователей — от бизнес-специалистов до специалистов по обработке данных.
Содержание
- Что такое визуализация данных?
- Почему важна визуализация данных?
- 1. Визуализация данных выявляет тенденции в области обработки данных
- 2. Визуализация данных дает представление о данных
- 3. Визуализация данных помещает данные в правильный контекст
- 4. Визуализация данных экономит время
- 5. Визуализация данных рассказывает историю данных
- Типы методов визуализации данных
- Инструменты для визуализации данных
- Преимущества и недостатки визуализации данных
- Рекомендации по визуализации данных
- Примеры использования и применения визуализации данных
Что такое визуализация данных?
Визуализация данных преобразует сложные наборы данных в визуальные форматы, которые легче воспринимаются человеческим мозгом. Это может включать в себя различные визуальные инструменты, такие как:
- Диаграммы: Столбчатые диаграммы, линейчатые диаграммы, круговые диаграммы и т.д.
- Графики: точечные диаграммы, гистограммы и т.д.
- Карты: Географические карты, тепловые карты и т.д.
- Информационные панели: Интерактивные платформы, объединяющие несколько визуализаций.
Основная цель визуализации данных — сделать их более доступными и простыми для интерпретации, чтобы пользователи могли быстро выявлять закономерности, тенденции и отклонения. Это особенно важно в контексте больших данных, когда объём информации может быть огромным и без эффективных методов визуализации.
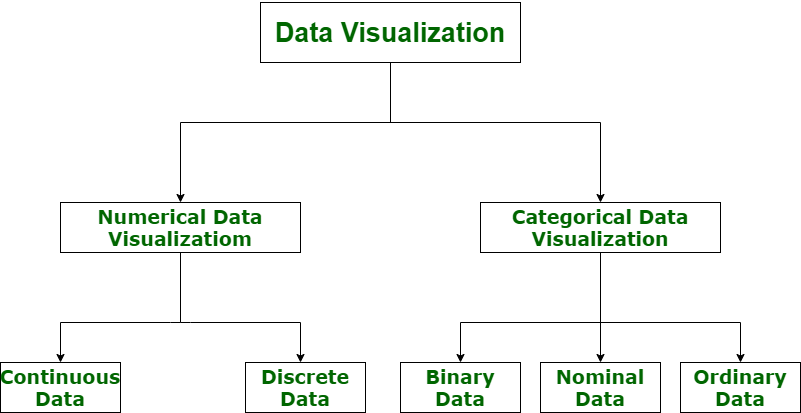
Типы данных для визуализации
Точная визуализация данных очень важна для маркетинговых исследований, где можно визуализировать как числовые, так и категориальные данные, что помогает повысить эффективность анализа, а также снизить риск «паралича анализа». Таким образом, визуализация данных делится на следующие категории:
- Числовые данные
- Категориальные данные
Давайте рассмотрим визуализацию данных с помощью диаграммы со всеми её категориями.
Почему важна визуализация данных?
Давайте рассмотрим пример. Предположим, вы собираете данные о прибыли компании с 2013 по 2023 год и создаёте линейную диаграмму. Очень легко заметить, что линия постоянно растёт, а в 2018 году падает. Таким образом, вы можете за секунду увидеть, что компания получала прибыль во все годы, кроме 2018-го.
Было бы непросто так быстро получить эту информацию из таблицы данных. Это лишь один пример того, насколько полезна визуализация данных. Давайте рассмотрим ещё несколько причин, почему визуализация данных так важна.
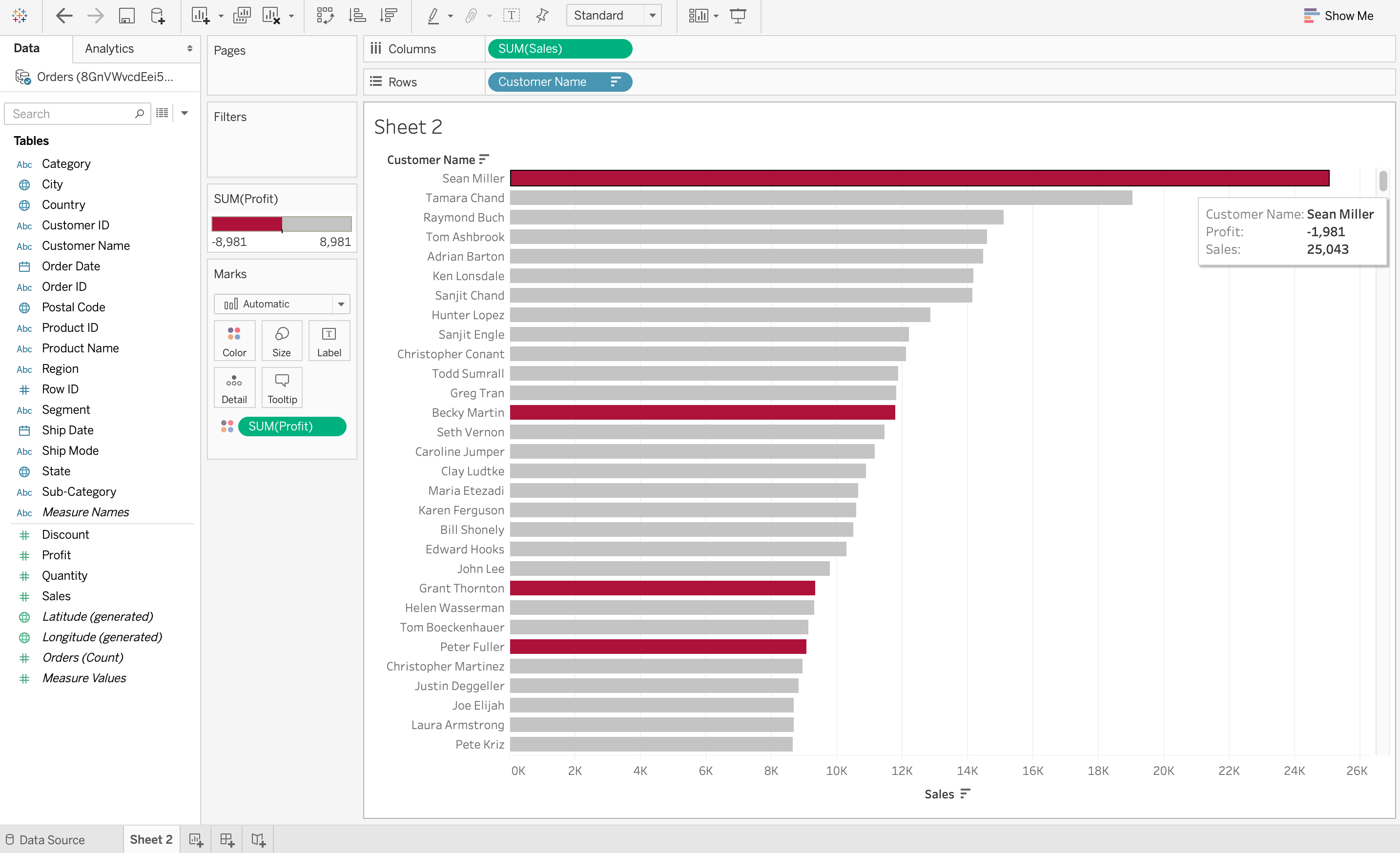
1. Визуализация данных выявляет тенденции в области обработки данных
Самое важное, что делает визуализация данных, — это выявляет тенденции в данных. В конце концов, гораздо проще наблюдать за тенденциями в данных, когда все данные представлены в наглядной форме, а не в виде таблицы. Например, на скриншоте ниже в Tableau показана сумма продаж каждого клиента в порядке убывания. Однако красный цвет обозначает убытки, а серый — прибыль. Таким образом, из этой визуализации очень легко понять, что, хотя у некоторых клиентов могут быть огромные продажи, они всё равно несут убытки. Это было бы очень сложно наблюдать из таблицы.
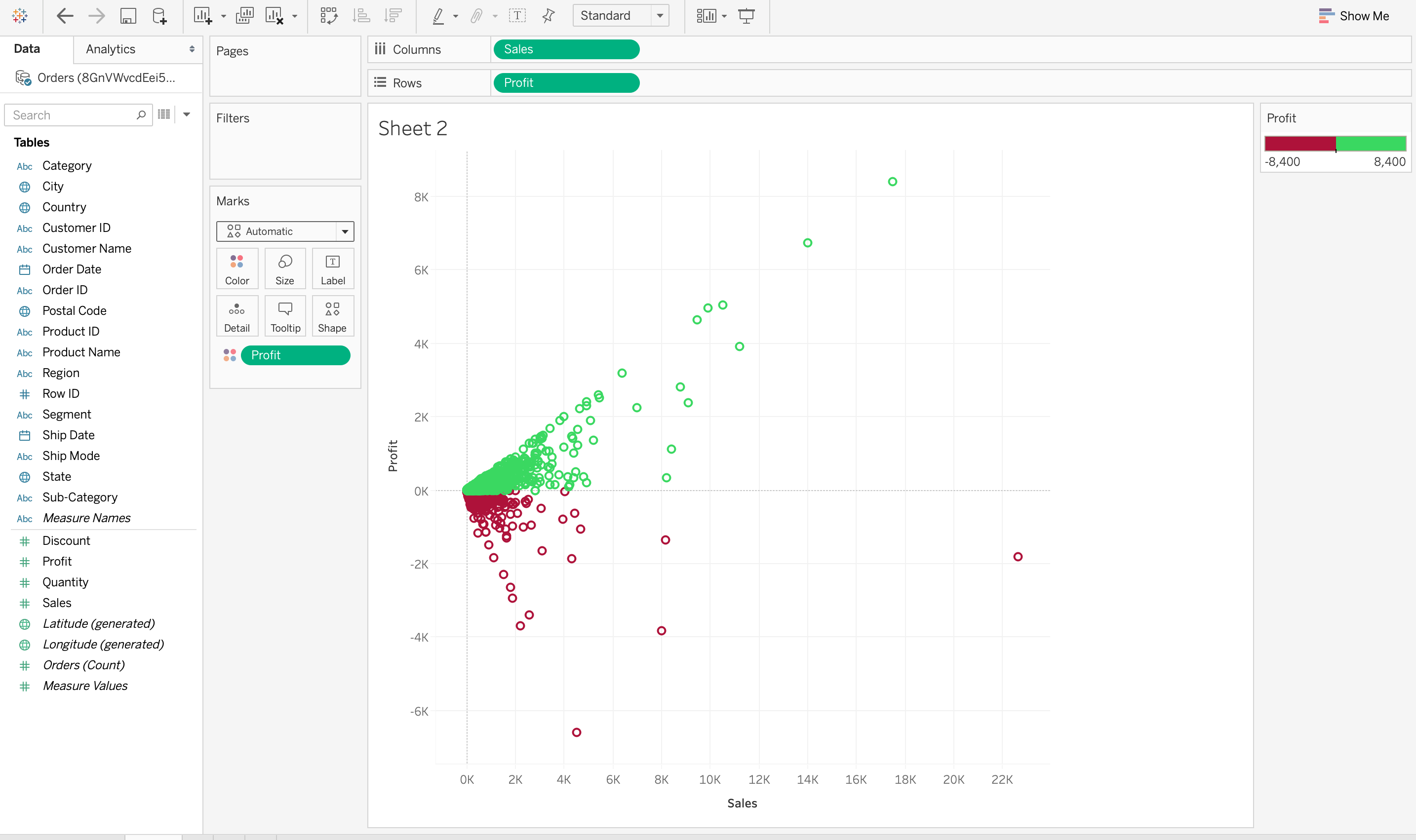
2. Визуализация данных дает представление о данных
Визуализация данных позволяет взглянуть на них со стороны, показав их значение в более широком контексте. Она демонстрирует, как отдельные данные соотносятся с общей картиной данных. На приведённой ниже визуализации данных соотношение между продажами и прибылью позволяет взглянуть на эти два показателя со стороны. Она также показывает, что очень немногие продажи превышают 12 000, а более высокие продажи не обязательно означают более высокую прибыль.
3. Визуализация данных помещает данные в правильный контекст
Нелегко понять контекст данных с помощью визуализации данных. Поскольку контекст отражает все обстоятельства, связанные с данными, его очень трудно понять, просто читая цифры в таблице. В приведенной ниже визуализации данных на Tableau используется древовидная диаграмма для демонстрации количества продаж в каждом регионе США. Из этой визуализации данных очень легко понять, что в Калифорнии самое большое количество продаж по сравнению с другими регионами, поскольку прямоугольник для Калифорнии самый большой. Но эту информацию нелегко понять вне контекста, без визуализации данных.
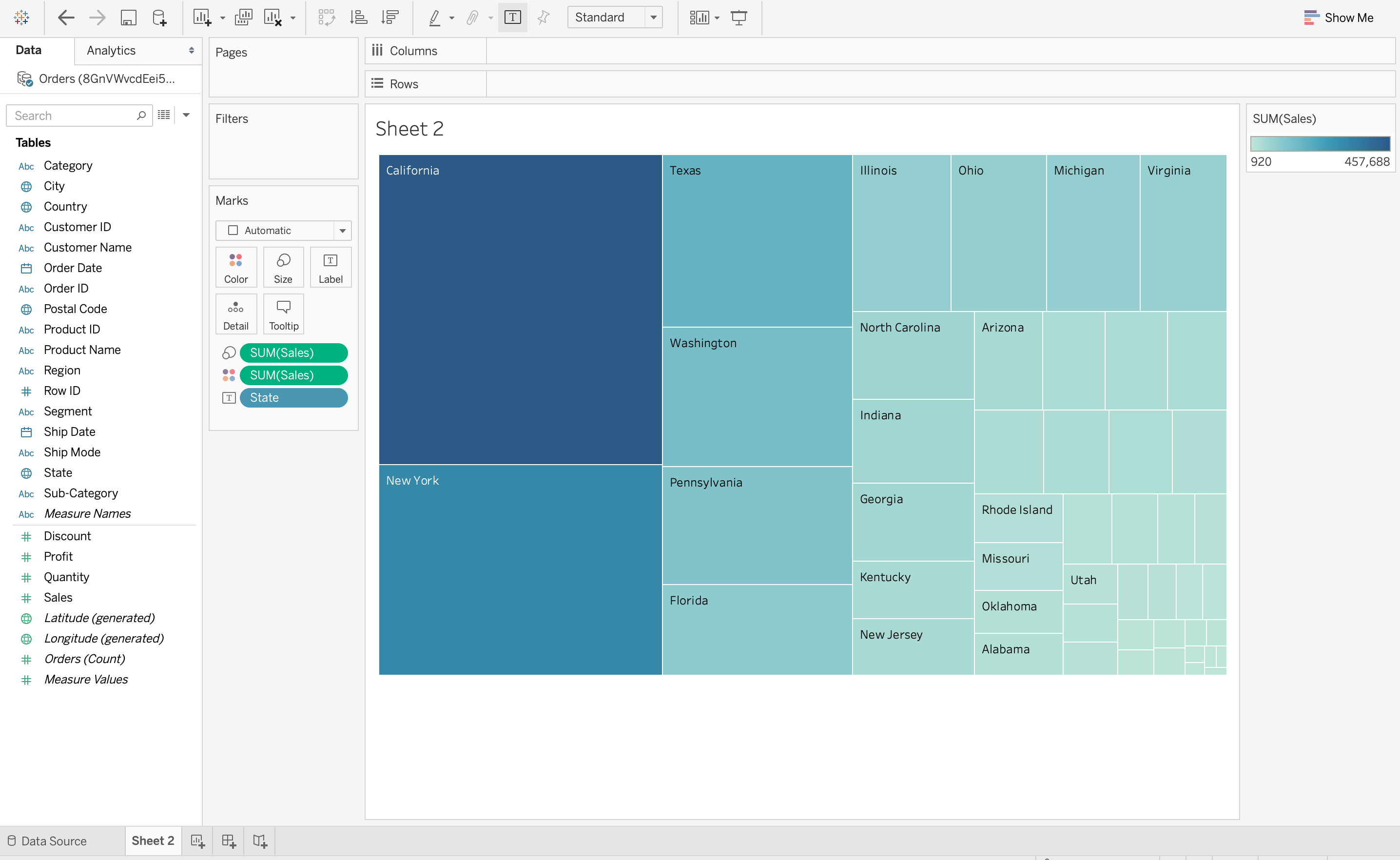
4. Визуализация данных экономит время
Определённо, быстрее получить представление о данных с помощью визуализации, чем просто изучать диаграмму. На скриншоте ниже в Tableau очень легко определить штаты, которые понесли чистый убыток, а не прибыль. Это связано с тем, что все ячейки с убытком окрашены в красный цвет с помощью тепловой карты, поэтому очевидно, что штаты понесли убыток. Сравните это с обычной таблицей, в которой вам нужно было бы проверять каждую ячейку, чтобы определить убыток. Визуализация данных может сэкономить много времени в этой ситуации!
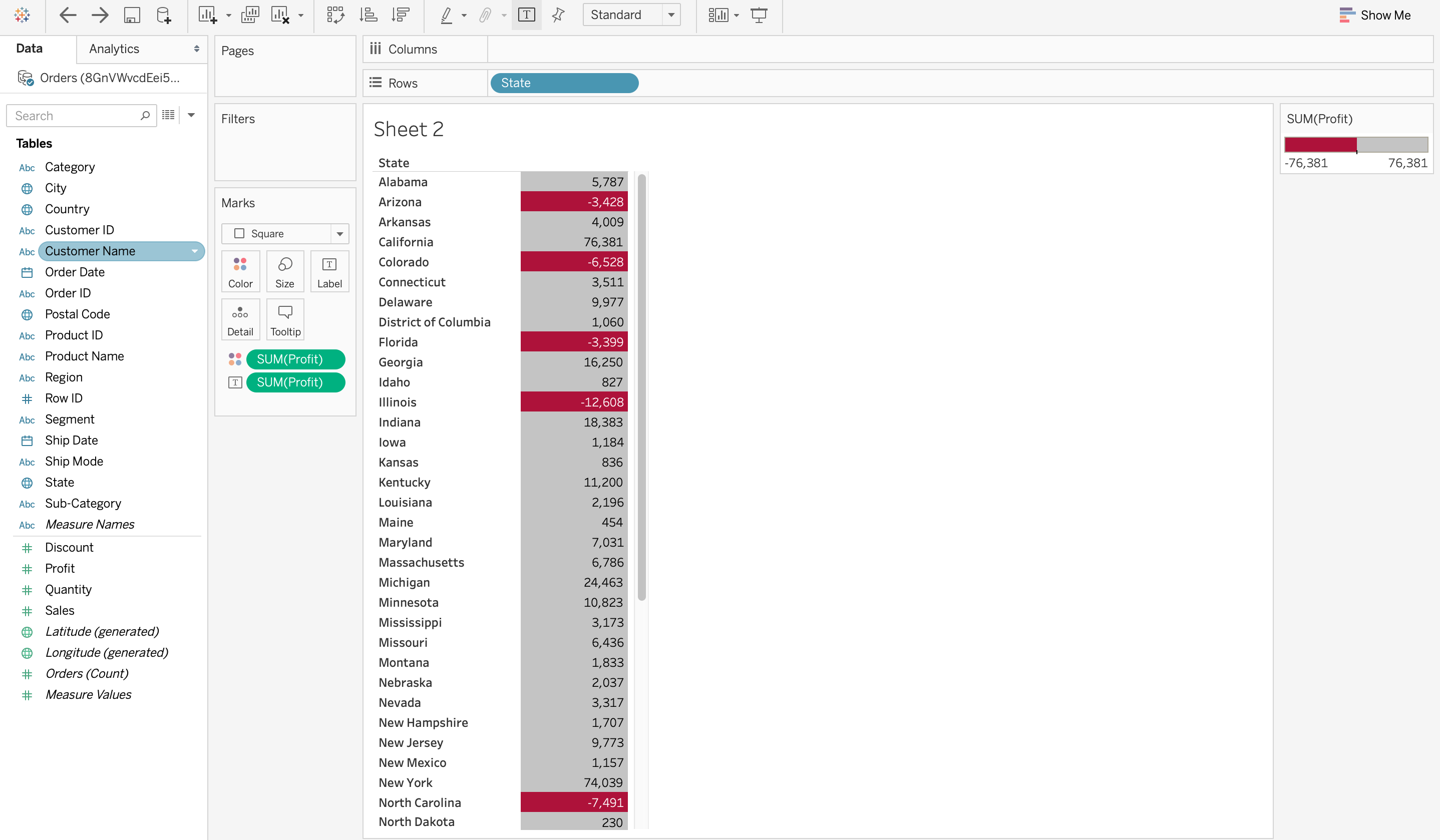
5. Визуализация данных рассказывает историю данных
Визуализация данных — это также способ рассказать зрителям историю, основанную на данных. Визуализация может использоваться для представления фактов в понятной форме, рассказывая историю и подводя зрителей к неизбежному выводу. Эта история, основанная на данных, как и любая другая история, должна иметь хорошее начало, основной сюжет и концовку, к которой она ведёт. Например, если аналитику данных нужно создать визуализацию данных для руководителей компании, подробно описывающую прибыль от различных продуктов, то история данных может начинаться с прибыли и убытков от нескольких продуктов и переходить к рекомендациям по устранению убытков.
Теперь, когда мы разобрались с основами визуализации данных и её важностью, мы обсудим преимущества, недостатки и этапы обработки данных (вместе со схемой), которые помогут вам понять, как данные собираются на разных этапах.
Типы методов визуализации данных
Различные типы визуализаций подходят для разных наборов данных и аналитических целей.
- Гистограммы: идеально подходят для сравнения категориальных данных или отображения частот, гистограммы обеспечивают наглядное визуальное представление значений.
- Линейные диаграммы: идеально подходят для демонстрации тенденций с течением времени. Линейные диаграммы соединяют точки данных, чтобы выявить закономерности и колебания.
- Круговые диаграммы: Круговые диаграммы, эффективно отображающие части целого, представляют собой простой способ понять пропорции и проценты.
- Точечные диаграммы: демонстрируют взаимосвязи между двумя переменными, выявляя закономерности и выбросы с помощью разбросанных точек данных.
- Гистограммы: отображают распределение непрерывной переменной, предоставляя информацию о закономерностях, лежащих в основе данных.
- Тепловые карты: визуализируйте сложные наборы данных с помощью цветовой кодировки, подчеркивающей различия и взаимосвязи в матрице.
- Ящичковые диаграммы: отображают статистические сводные данные, такие как медиана, квартили и выбросы, помогая анализировать распределение данных.
- Точечные диаграммы: похожи на линейные диаграммы, но область под линией закрашена. Эти диаграммы подчёркивают кумулятивные закономерности в данных.
- Пузырьковые диаграммы: улучшите точечные диаграммы, добавив третье измерение за счёт изменения размера пузырьков, что позволит получить дополнительную информацию.
- Древовидные карты: эффективно представляют иерархические структуры данных, разбивая категории на вложенные прямоугольники.
- Гистограммы с накоплением: Гистограммы с накоплением сочетают в себе элементы ящичковых диаграмм и диаграмм плотности ядра, обеспечивая детальное представление распределения данных.
- Облака слов: облака слов — это визуальное представление текстовых данных, в котором размер слов зависит от их частоты встречаемости.
- 3D-поверхностные графики: 3D-поверхностные графики визуализируют трехмерные данные, показывая, как изменяется зависимая переменная в зависимости от двух независимых переменных.
- Сетевые графы: сетевые графы представляют взаимосвязи между объектами с помощью узлов и рёбер. Они полезны для визуализации связей в сложных системах, таких как социальные сети, транспортные сети или организационные структуры.
- Диаграммы Санки: диаграммы Санки визуализируют взаимосвязи потоков и количеств между несколькими объектами. Часто используются в технологической инженерии или при анализе потоков энергии.
Визуализация данных не только упрощает сложную информацию, но и улучшает процессы принятия решений. Выбор подходящего типа визуализации помогает выявить скрытые закономерности и тенденции в данных, делая обоснованные и эффективные выводы.
Инструменты для визуализации данных
Ниже приведены 10 лучших инструментов визуализации данных
- Tableau
- Looker
- Zoho Analytics
- Sisense
- IBM Cognos Analytics
- Qlik Sense
- Domo
- Microsoft Power BI
- Klipfolio
- SAP Analytics Cloud
Преимущества и недостатки визуализации данных
Преимущества визуализации данных:
- Расширенное сравнение: визуализация результатов сравнения двух элементов или сценариев упрощает анализ, экономя время по сравнению с традиционным изучением данных.
- Улучшенная методология: Графическое представление данных позволяет лучше понять ситуацию, о чём свидетельствуют такие инструменты, как Google Trends, иллюстрирующие отраслевые тенденции в графической форме.
- Эффективный обмен данными: визуальное представление данных способствует эффективному общению, делая информацию более понятной и привлекательной по сравнению с обменом необработанными данными.
- Анализ продаж: визуализация данных помогает специалистам по продажам понять тенденции продаж, выявить факторы, оказывающие влияние, с помощью таких инструментов, как тепловые карты, а также понять типы клиентов, географические факторы и поведение постоянных клиентов.
- Выявление взаимосвязей между событиями: обнаружение взаимосвязей между событиями помогает компаниям понять внешние факторы, влияющие на их деятельность, например, всплески онлайн-продаж в праздничные сезоны.
- Изучение возможностей и тенденций: визуализация данных позволяет руководителям компаний выявлять закономерности и возможности в обширных наборах данных, обеспечивая более глубокое понимание поведения клиентов и новых тенденций в бизнесе.
Недостатки визуализации данных:
- Может занимать много времени: создание визуализаций может быть трудоемким процессом, особенно при работе с большими и сложными наборами данных.
- Может вводить в заблуждение: хотя визуализация данных может помочь выявить закономерности и взаимосвязи в данных, она также может вводить в заблуждение, если выполнена неправильно. Визуализация может создавать впечатление о закономерностях или тенденциях, которых может не существовать, что приводит к неверным выводам и принятию неверных решений.
- Может быть сложно интерпретировать: Некоторые типы визуализаций, например, те, которые включают 3D или интерактивные элементы, могут быть сложными для интерпретации и понимания.
- Может не подходить для всех типов данных: Некоторые типы данных, например текстовые или аудиоданные, могут плохо поддаваться визуализации. В таких случаях более подходящими могут оказаться альтернативные методы анализа.
- Может быть недоступно для всех пользователей: у некоторых пользователей могут быть нарушения зрения или другие ограничения, которые затрудняют или делают невозможным интерпретацию визуализаций. В таких случаях для обеспечения доступности могут потребоваться альтернативные способы представления данных.
Рекомендации по визуализации данных
Эффективная визуализация данных имеет решающее значение для точной передачи информации. Следуйте этим рекомендациям, чтобы создавать убедительные и понятные визуализации:
- Подход, ориентированный на аудиторию: адаптируйте визуализацию к уровню знаний вашей аудитории, обеспечивая понятность и актуальность. Учитывайте их опыт в интерпретации данных и соответствующим образом корректируйте сложность визуальных элементов.
- Ясность и согласованность дизайна: выбирайте подходящие типы диаграмм, упрощайте визуальные элементы и придерживайтесь единой цветовой схемы и разборчивых шрифтов. Это обеспечит четкую, согласованную и легко интерпретируемую визуализацию.
- Контекстная коммуникация: обеспечьте контекст с помощью понятных меток, заголовков, аннотаций и ссылок на источники данных. Это поможет зрителям понять важность представленной информации и повысит прозрачность и доверие.
- Привлекательный и доступный дизайн: Тщательно продумывайте интерактивные функции, чтобы они улучшали понимание. Кроме того, уделяйте приоритетное внимание доступности, тестируя визуализации на отзывчивость и адаптируясь к различным потребностям аудитории, чтобы обеспечить инклюзивный и привлекательный опыт.
Примеры использования и применения визуализации данных
1. Бизнес-аналитика и отчетность
В сфере бизнес-аналитики и отчётности организации используют сложные инструменты для улучшения процессов принятия решений. Это включает в себя внедрение комплексных информационных панелей, предназначенных для отслеживания ключевых показателей эффективности (KPI) и основных бизнес-показателей. Кроме того, компании проводят тщательный анализ тенденций, чтобы выявлять закономерности и аномалии в продажах, доходах и других важных наборах данных. Эти визуальные данные играют ключевую роль в принятии стратегических решений, позволяя заинтересованным сторонам оперативно реагировать на динамику рынка.
2. Финансовый анализ
Финансовый анализ в корпоративном секторе предполагает использование визуальных представлений для принятия инвестиционных решений. Визуализация цен на акции и рыночных тенденций даёт инвесторам ценную информацию. Кроме того, организации проводят сравнительный анализ запланированных и фактических расходов, чтобы получить полное представление о финансовых результатах. Визуализация движения денежных средств и финансовых отчётов способствует более чёткой оценке общего финансового состояния и помогает разрабатывать надёжные финансовые стратегии.
3. Здравоохранение
В сфере здравоохранения визуализация играет важную роль в передаче сложной информации. Визуальные представления используются для информирования о результатах лечения пациентов и оценки эффективности лечения, что способствует более доступному пониманию для медицинских работников и заинтересованных сторон. Кроме того, визуальное представление распространения заболеваний и эпидемиологических данных имеет решающее значение для поддержки усилий в области общественного здравоохранения. С помощью визуальной аналитики организации здравоохранения добиваются эффективного распределения и использования ресурсов, обеспечивая оптимальное предоставление медицинских услуг.
4. Маркетинг и продажи
В сфере маркетинга и продаж визуализация данных становится мощным инструментом для понимания поведения клиентов. Визуально понятные диаграммы упрощают сегментацию и анализ поведения, предоставляя информацию, на основе которой разрабатываются целевые маркетинговые стратегии. Визуализация воронки продаж позволяет получить полное представление о пути клиента, что дает организациям возможность оптимизировать свои процессы продаж. Визуальная аналитика взаимодействия в социальных сетях и эффективности кампаний еще больше повышает эффективность маркетинговых стратегий, позволяя проводить более эффективные и целенаправленные кампании.
5. Человеческие ресурсы
Отделы кадров используют визуализацию данных для оптимизации процессов и улучшения управления персоналом. Разработка информационных панелей для оценки эффективности работы сотрудников способствует повышению эффективности HR-операций. Демографические данные и показатели разнообразия персонала представлены в наглядном виде, что способствует внедрению инклюзивных практик в организациях. Кроме того, визуализация аналитических данных для стратегий найма и удержания сотрудников способствует более эффективному управлению талантами.
Визуализация данных в Big Data
В современной сфере управления информацией взаимодействие между визуализацией данных и большими данными становится все более важным для организаций, стремящихся получить полезную информацию из обширных и сложных наборов данных. Визуализация данных с помощью графических методов представления, таких как диаграммы, графики и тепловые карты, играет ключевую роль в выявлении сложных закономерностей и тенденций, присущих огромным наборам данных.
- Он служит связующим звеном между необработанными данными и значимой информацией, позволяя заинтересованным сторонам понимать сложные взаимосвязи и принимать обоснованные решения.
- В совокупности большие данные, характеризующиеся экспоненциальным ростом и разнообразием информации, обеспечивают содержательную основу для этих визуализаций.
По мере того, как организации сталкиваются с проблемами и возможностями, которые открывает огромный объём, скорость и разнообразие данных, интеграция визуализации данных становится незаменимой стратегией для извлечения пользы и более глубокого понимания сложной информации. Сочетание визуализации данных и больших данных не только повышает интерпретируемость, но и позволяет лицам, принимающим решения, извлекать полезную информацию из огромных массивов данных, доступных в современном мире.
Заключение
Визуализация данных является краеугольным камнем в современном мире интерпретации информации. Её способность преобразовывать сложные данные в понятные визуальные форматы, такие как диаграммы и графики, помогает принимать более взвешенные решения в различных отраслях.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 11
Отсутствие данных может возникать, когда не предоставляется информация по одному или нескольким элементам или по целому подразделению. Отсутствие данных является очень большой проблемой в реальных сценариях. Отсутствующие данные также могут относиться к значениям NA (Недоступно) в pandas. В DataFrame иногда многие наборы данных просто поступают с отсутствующими данными, либо потому, что они существуют и не были собраны, либо они никогда не существовали. Например, предположим, что разные опрашиваемые пользователи могут предпочесть не делиться своими доходами, некоторые пользователи могут предпочесть не делиться адресом, таким образом, пропало много наборов данных.

В Pandas отсутствующие данные представлены двумя значениями:
- None: None — это одноэлементный объект Python, который часто используется для обозначения отсутствующих данных в коде Python.
- NaN (сокращение от Not a Number — «не число») — это специальное значение с плавающей запятой, распознаваемое всеми системами, использующими стандартное представление чисел с плавающей запятой IEEE
В Pandas значения None и NaN по сути взаимозаменяемы для обозначения отсутствующих или нулевых значений. Чтобы упростить это соглашение, существует несколько полезных функций для обнаружения, удаления и замены нулевых значений в Pandas DataFrame:
- isnull()
- notnull()
- dropna()
- fillna()
- replace()
- interpolate()
В этой статье мы используем CSV-файл.
Проверка на отсутствие значений с помощью isnull() и notnull()
Чтобы проверить наличие пропущенных значений в Pandas DataFrame, мы используем функции isnull() и notnull(). Обе функции помогают проверить, является ли значение NaN. Эти функции также можно использовать в Pandas Series, чтобы найти пропущенные значения в серии.
Проверка на отсутствие значений с помощью isnull()
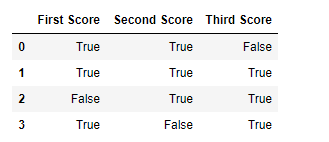
Чтобы проверить нулевые значения в Pandas DataFrame, мы используем функцию isnull(). Эта функция возвращает фрейм данных с логическими значениями, которые равны True для значений NaN.
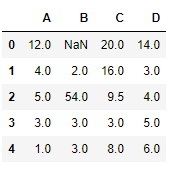
Код # 1:
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.isnull()
Вывод: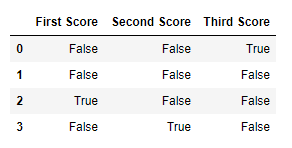
Код # 2:
import pandas as pd
data = pd.read_csv("employees.csv")
bool_series = pd.isnull(data["Gender"])
data[bool_series]
Вывод: Как показано на изображении, отображаются только строки, в которых поле «Пол» равно NULL.
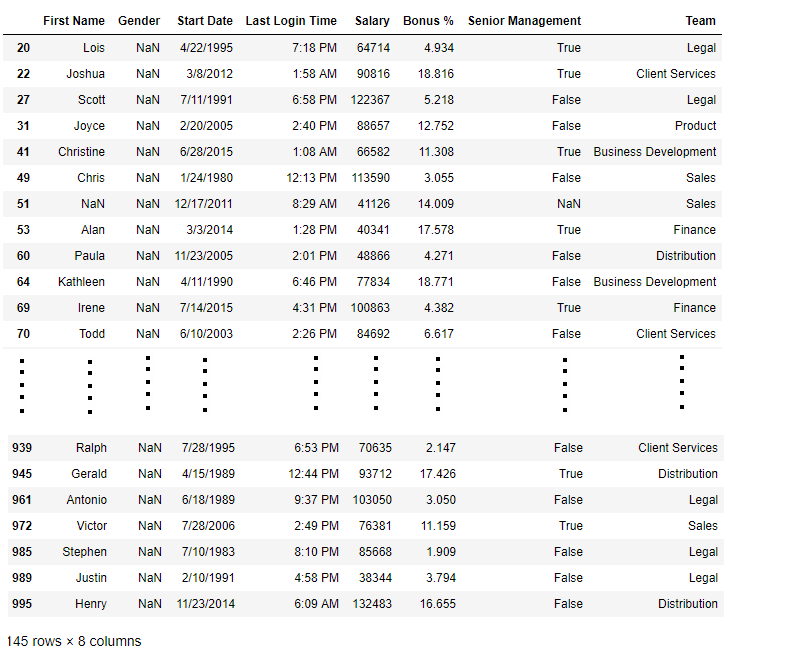
Проверка на отсутствие значений с помощью notnull()
Чтобы проверить нулевые значения в фрейме данных Pandas, мы используем функцию notnull(). Эта функция возвращает фрейм данных с логическими значениями, которые равны False для значений NaN.
Код # 3:
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.notnull()
Вывод:
Код # 4:
import pandas as pd
data = pd.read_csv("employees.csv")
bool_series = pd.notnull(data["Gender"])
data[bool_series]
Вывод: Как показано на изображении вывода, отображаются только строки, в которых поле «Пол» не равно NULL.
Заполнение отсутствующих значений с помощью fillna(), replace() и interpolate()
Чтобы заполнить нулевые значения в наборах данных, мы используем функции fillna(), replace() и interpolate(). Эти функции заменяют значения NaN на какое-то другое значение. Все эти функции помогают заполнить нулевые значения в наборах данных фрейма данных. Функция interpolate() в основном используется для заполнения значений NA в фрейме данных, но она использует различные методы интерполяции для заполнения пропущенных значений, а не жёстко задаёт значение.
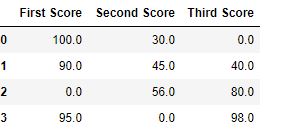
Код №1: Заполнение нулевых значений одним значением
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(0)
Вывод:
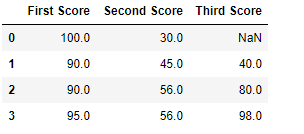
Код №2: Заполнение нулевых значений предыдущими
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(method ='pad')
Вывод:
Код # 3:
Заполнение нулевого значения следующими данными
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(method ='bfill')
Вывод:
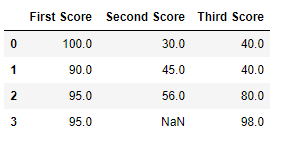
Код №4: Заполнение нулевых значений в CSV-файле
import pandas as pd
data = pd.read_csv('employees.csv')
data[10:25]
Вывод
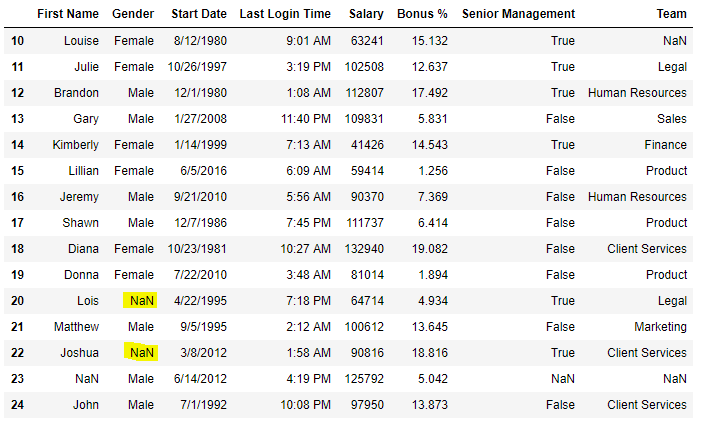
Теперь мы заполним все пустые значения в столбце «Пол» текстом «Без пола»
import pandas as pd
data = pd.read_csv("employees.csv")
data["Gender"].fillna('No Gender', inplace = True)
data
Вывод:
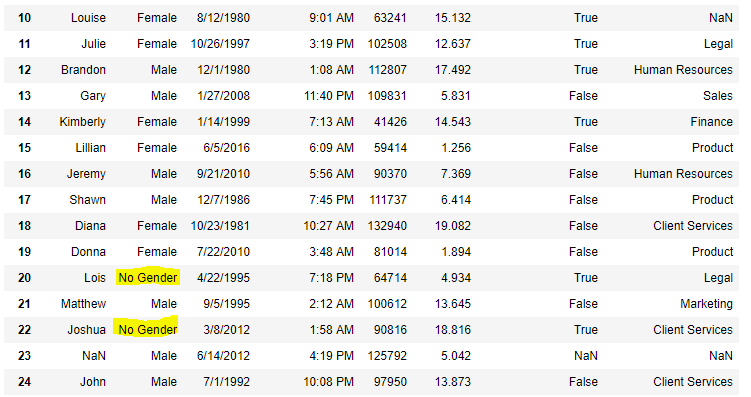
Код № 5: Заполнение нулевых значений с помощью метода replace()
import pandas as pd
data = pd.read_csv('employees')
data[10:25]
Вывод:
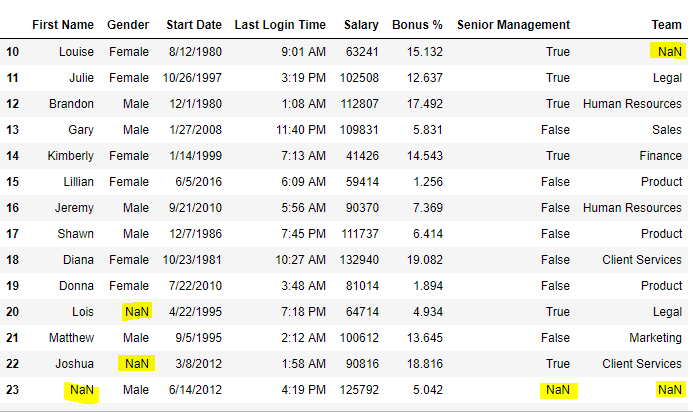
Теперь мы заменим все значения Nan в фрейме данных на значение -99.
import pandas as pd
data = pd.read_csv("employees.csv")
data.replace(to_replace = np.nan, value = -99)
Вывод:
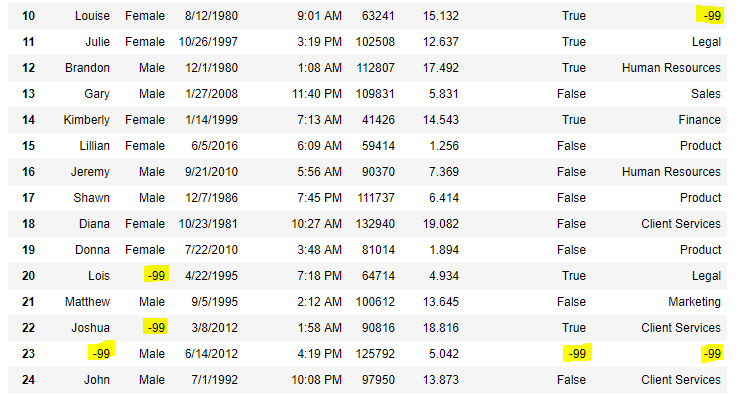
Код № 6: Использование функции interpolate() для заполнения пропущенных значений с помощью линейного метода.
import pandas as pd
df = pd.DataFrame({'A':[12, 4, 5, None, 1],
'B':[None, 2, 54, 3, None],
'C':[20, 16, None, 3, 8],
'D':[14, 3, None, None, 6]})
df
Вывод:
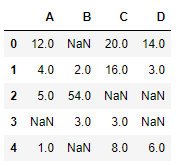
Давайте интерполируем недостающие значения с помощью линейного метода. Обратите внимание, что линейный метод игнорирует индекс и рассматривает значения как равномерно распределённые.
df.interpolate(method ='linear', limit_direction ='forward')
Вывод:
Как видно из результата, значения в первой строке не могли быть заполнены, так как направление заполнения значений идёт вперёд, а предыдущего значения, которое можно было бы использовать для интерполяции, нет.
Удаление отсутствующих значений с помощью dropna()
Чтобы удалить нулевые значения из фрейма данных, мы использовали функцию dropna(). Эта функция удаляет строки/столбцы наборов данных с нулевыми значениями различными способами.
Код № 1: Удаление строк, содержащих хотя бы одно нулевое значение.
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df
Вывод
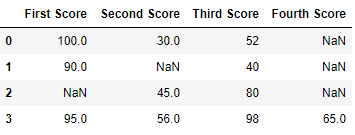
Теперь мы удаляем строки, содержащие хотя бы одно значение Nan (нулевое значение)
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna()
Вывод:
Код № 2: Удаление строк, если все значения в этой строке отсутствуют.
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df
Вывод
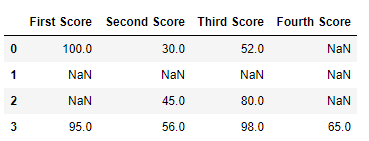
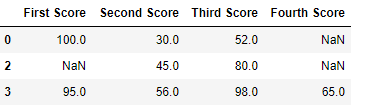
Теперь мы удалим строки, в которых все данные отсутствуют или содержат нулевые значения (NaN)
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna(how = 'all')
Вывод:
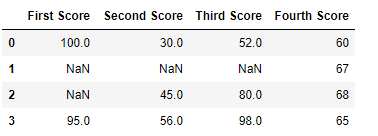
Код # 3:
Удаление столбцов, содержащих как минимум 1 нулевое значение.
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
df = pd.DataFrame(dict)
df
Вывод
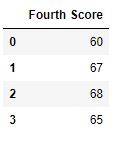
Теперь мы удаляем столбцы, в которых отсутствует как минимум 1 значение
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
df = pd.DataFrame(dict)
df.dropna(axis = 1)
Вывод :
Код № 4: Удаление строк с хотя бы одним нулевым значением в CSV-файле
import pandas as pd
data = pd.read_csv("employees.csv")
new_data = data.dropna(axis = 0, how ='any')
new_data
Вывод:
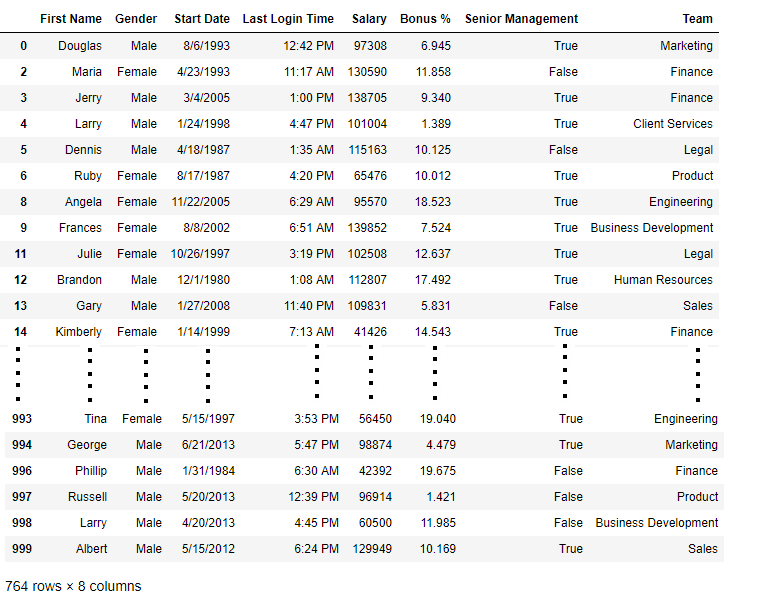
Теперь мы сравниваем размеры фреймов данных, чтобы узнать, в скольких строках есть хотя бы одно нулевое значение
print('Old data frame length:', len(data))
print('New data frame length:', len(new_data))
print('Number of rows with at least 1 NA value: ', (len(data)-len(new_data)))
Вывод :
Old data frame length: 1000
New data frame length: 764
Number of rows with at least 1 NA value: 236
Поскольку разница составляет 236, в 236 строках было хотя бы одно нулевое значение в каком-либо столбце.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 35
С помощью Pandas мы можем выполнить нарезку в кадре данных.Нарезка во фреймах данных Pandas с помощью iloc[] — это новый метод в Python для извлечения определенных подмножеств данных.Метод iloc[] Позволяет находить и извлекать стоки и столбцы на основе их целочисленных позиций.
Чтобы настроить резку с помощью iloc[] вы указываете индексы строк и столбцов, которые необходимо включить в нарезанный кадр данных.Синтаксис аналогичен традиционной нарезке массивов, что делает его преобразование понятным для пользователей Python.Например, df.iloc[1:5, 2:4] извлекает строки со 2-й по 5-ю и столбцы с 3-го по 4-й из кадра данных.
Создание каркаса данных в Pandas включает в себя следующие шаги:
- Создание каркаса данных
- Нарезать каркас данных
Давайте импортируем библиотеку pandas и создадим структуру данных pandas из пользовательского вложенного списка.
import pandas as pd
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villers', 38, 74, 3428000],
['V.Kohli', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
df = pd.DataFrame(player_list, columns=['Name', 'Age', 'Weight', 'Salary'])
df # data frame before slicing
Вывод:
Имя Возраст Вес Зарплата
0 MSDhoni 36 75 5428000
1 ABD Villers 38 74 3428000
2 V.Kohli 31 70 8428000
3 S.Smith 34 80 4428000
4 C.Gayle 40 100 4528000
5 J.Root 33 72 7028000
6 K.Peterson 42 85 2528000
1. Нарезка с помощью iloc
A. Нарезка строки в кадре данных в Python
df1 = df.iloc[0:4]
df1
Вывод:
Name Age Weight Salary
0 M.S.Dhoni 36 75 5428000
1 A.B.D Villers 38 74 3428000
2 V.Kohli 31 70 8428000
3 S.Smith 34 80 4428000
В приведенном выше примере мы вырезали строки из фрейма данных.
B. Нарезка столбцов в фрейме данных в python
df1 = df.iloc[:, 0:2]
df1
Вывод:
Name Age
0 M.S.Dhoni 36
1 A.B.D Villers 38
2 V.Kohli 31
3 S.Smith 34
4 C.Gayle 40
5 J.Root 33
6 K.Peterson 42
В приведенном выше примере мы вырезали столбцы из фрейма данных.
C. Выбор определенной ячейки в фрейме данных в Python
specific_cell_value = df.iloc[2, 3]
print("Specific Cell Value:", specific_cell_value)
Вывод:
Specific Cell Value: 8428000
D. Использование логических условий в фрейме данных в Python
filtered_data = df[df['Age'] > 35].iloc[:, :]
print("\nFiltered Data based on Age > 35:\n", filtered_data)
Вывод:
Filtered Data based on Age > 35:
Name Age Weight Salary
0 M.S.Dhoni 36 75 5428000
1 A.B.D Villers 38 74 3428000
4 C.Gayle 40 100 4528000
6 K.Peterson 42 85 2528000
2. Нарезка с использованием loc[]
Мы также можем реализовать нарезку через loc, но есть некоторые ограничения:
locОн полагается на метки, и если в вашем DataFrame есть пользовательские метки, вам нужно быть осторожным при их указании.- Если метки являются целыми числами, может возникнуть путаница между использованием целых чисел в качестве позиций и фактическими метками.
Для этого нам нужно вручную установить индекс в виде меток с помощью следующего кода:
df_custom = df.set_index('Name')
df_custom
Вывод:
Age Weight Salary
Name
M.S.Dhoni 36 75 5428000
A.B.D Villers 38 74 3428000
V.Kohli 31 70 8428000
S.Smith 34 80 4428000
C.Gayle 40 100 4528000
J.Root 33 72 7028000
K.Peterson 42 85 2528000
A. Нарезка строк в фрейме данных в Python
sliced_rows_custom = df_custom.loc['A.B.D Villers':'S.Smith']
sliced_rows_custom
Вывод:
Age Weight Salary
Name
A.B.D Villers 38 74 3428000
V.Kohli 31 70 8428000
S.Smith 34 80 4428000
B. Выбор указанной ячейки в фрейме данных в Python
specific_cell_value = df_custom.loc['V.Kohli', 'Salary']
print("\nValue of the Specific Cell (V.Kohli, Salary):", specific_cell_value)
Заключение
Таким образом, и iloc[], и loc[] предоставляют в Pandas универсальные возможности нарезки. В то время как iloc[] работает с целыми числами, loc[] использует метки, что требует внимательного подхода при работе с пользовательскими индексами или смешанными типами данных.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 25
Очистка данных — одна из важных составляющих машинного обучения. Она играет значительную роль в построении модели. В этой статье мы рассмотрим очистку данных, её значение и реализацию на Python.
Что такое очистка данных?
Очистка данных является важным этапом в конвейере машинного обучения (ML), поскольку она включает в себя выявление и удаление любых отсутствующих, дублирующихся или нерелевантных данных. Целью очистки данных является обеспечение точности, согласованности и отсутствия ошибок, поскольку неправильные или противоречивые данные могут негативно повлиять на производительность модели машинного обучения. Профессиональные специалисты по обработке данных обычно тратят очень много времени на этот этап, поскольку считают, что «более качественные данные превосходят более сложные алгоритмы».
Очистка данных, также известная как очистка и подготовка данных или предварительная обработка данных, является важным этапом в процессе обработки данных, который включает в себя выявление и исправление или удаление ошибок, несоответствий и неточностей в данных для повышения их качества и удобства использования. Очистка данных необходима, поскольку необработанные данные часто бывают зашумлёнными, неполными и противоречивыми, что может негативно сказаться на точности и надёжности выводов, полученных на их основе.
Почему важна очистка данных?
Очистка данных — важнейший этап в процессе подготовки данных, играющий важную роль в обеспечении точности, надёжности и общего качества набора данных.
При принятии решений достоверность сделанных выводов в значительной степени зависит от чистоты исходных данных. Без надлежащей очистки данных неточности, выбросы, пропущенные значения и несоответствия могут поставить под угрозу достоверность результатов анализа. Более того, очистка данных способствует более эффективному моделированию и распознаванию образов, поскольку алгоритмы работают оптимально при вводе высококачественных данных без ошибок.
Кроме того, чистые наборы данных повышают интерпретируемость результатов, помогая формулировать практические выводы.
Очистка данных в науке о данных
Очистка данных — неотъемлемая часть науки о данных, играющая фундаментальную роль в обеспечении точности и надёжности наборов данных. В области науки о данных, где выводы и прогнозы делаются на основе обширных и сложных наборов данных, качество входных данных существенно влияет на достоверность аналитических результатов. Очистка данных включает в себя систематическое выявление и исправление ошибок, несоответствий и неточностей в наборе данных и включает в себя такие задачи, как обработка пропущенных значений, удаление дубликатов и выявление выбросов. Этот тщательный процесс необходим для повышения достоверности анализа, содействия более точному моделированию и, в конечном счёте, для принятия обоснованных решений на основе достоверных и высококачественных данных.
Шаги по очистке данных
Очистка данных — это систематический процесс выявления и исправления ошибок, несоответствий и неточностей в наборе данных. Ниже приведены основные этапы очистки данных.
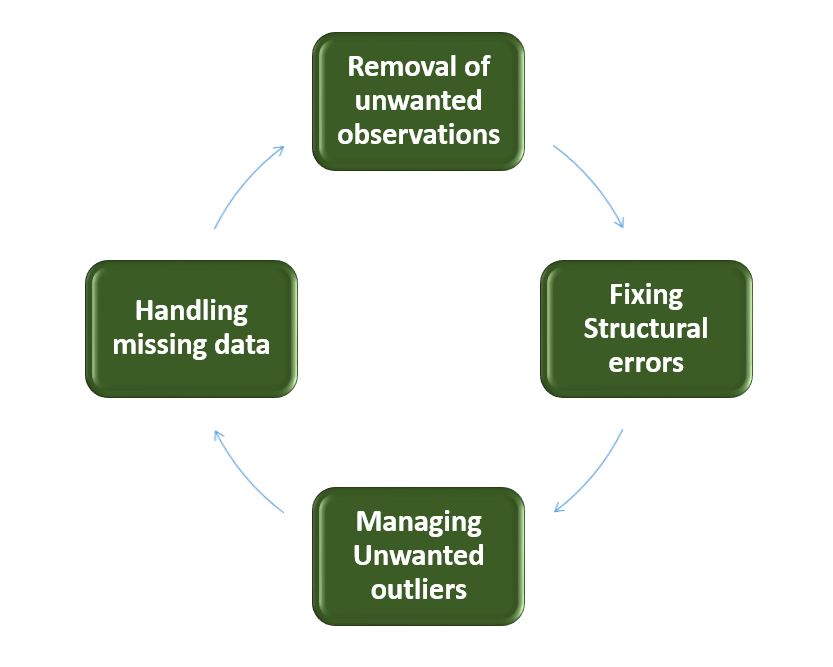
Очистка данных
- Удаление нежелательных наблюдений: выявление и удаление нерелевантных или избыточных наблюдений из набора данных. Этот этап включает в себя проверку записей данных на наличие дубликатов, нерелевантной информации или точек данных, которые не вносят значимого вклада в анализ. Удаление нежелательных наблюдений упрощает набор данных, уменьшая количество шума и повышая общее качество.
- Исправление структурных ошибок: устранение структурных проблем в наборе данных, таких как несоответствия в форматах данных, соглашениях об именовании или типах переменных. Стандартизируйте форматы, устраняйте несоответствия в именовании и обеспечивайте единообразие в представлении данных. Исправление структурных ошибок повышает согласованность данных и облегчает их точный анализ и интерпретацию.
- Управление нежелательными выбросами: выявляйте выбросы и управляйте ими, то есть точками данных, значительно отличающимися от нормы. В зависимости от контекста решите, удалять ли выбросы или преобразовывать их, чтобы минимизировать их влияние на анализ. Управление выбросами имеет решающее значение для получения более точных и надёжных результатов анализа данных.
- Обработка отсутствующих данных: Разработайте стратегии для эффективной обработки отсутствующих данных. Это может включать в себя вменение отсутствующих значений на основе статистических методов, удаление записей с отсутствующими значениями или использование передовых методов вменения. Обработка отсутствующих данных обеспечивает более полный набор данных, предотвращая искажения и сохраняя целостность анализа.
Как выполнить очистку данных
Выполнение очистки данных предполагает системный подход к повышению качества и надежности набора данных. Процесс начинается с тщательного понимания данных, проверки их структуры и выявления проблем, таких как пропущенные значения, дубликаты и выбросы. Устранение недостающих данных требует стратегических решений по условному исчислению или удалению, в то время как дубликаты систематически устраняются для уменьшения избыточности. Управление выбросами гарантирует, что экстремальные значения не окажут чрезмерного влияния на анализ. Структурные ошибки исправлены для стандартизации форматов и типов переменных, что способствует согласованности.
На протяжении всего процесса документирование изменений имеет решающее значение для прозрачности и воспроизводимости. Итеративная проверка и тестирование подтверждают эффективность этапов очистки данных, что в конечном итоге приводит к получению уточненного набора данных, готового к содержательному анализу и выводам.
Реализация Python для очистки базы данных
Давайте рассмотрим каждый этап очистки базы данных на примере набора данных Titanic. Ниже приведены необходимые шаги:
- Импортируйте необходимые библиотеки
- Загрузить набор данных
- Проверьте информацию о данных с помощью df.info ()
import pandas as pd
import numpy as np
df = pd.read_csv('titanic.csv')
df.head()
Результат:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
Проверка и исследование данных
Давайте сначала проанализируем данные, изучив их структуру и выявив пропущенные значения, выбросы и несоответствия, а также проверим повторяющиеся строки с помощью приведенного ниже кода на Python:
df.duplicated()Результат:
0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Length: 891, dtype: bool
Проверьте информацию о данных с помощью df.info()
df.info()Результат:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
Из приведённых выше данных мы видим, что возраст и номер каюты имеют разное количество значений. Некоторые столбцы являются категориальными и содержат объекты, а некоторые — целочисленные и числовые значения.
Проверьте столбцы категорий и цифр.
cat_col = [col for col in df.columns if df[col].dtype == 'object']
print('Categorical columns :',cat_col)
num_col = [col for col in df.columns if df[col].dtype != 'object']
print('Numerical columns :',num_col)
Результат:
Categorical columns : ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']
Numerical columns : ['PassengerId', 'Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare']
Проверьте общее количество уникальных значений в столбцах категорий
df[cat_col].nunique()Результат:
Name 891
Sex 2
Ticket 681
Cabin 147
Embarked 3
dtype: int64
Шаги по выполнению очистки данных
Удаление всех вышеперечисленных нежелательных наблюдений
Это включает в себя удаление дублирующихся/избыточных или нерелевантных значений из вашего набора данных. Дублирующиеся наблюдения чаще всего возникают во время сбора данных, а нерелевантные наблюдения — это те, которые на самом деле не соответствуют конкретной проблеме, которую вы пытаетесь решить.
- Избыточные наблюдения в значительной степени снижают эффективность, поскольку данные повторяются и могут быть как в пользу правильной, так и в пользу неправильной стороны, тем самым выдавая недостоверные результаты.
- Ненужные наблюдения — это любые данные, которые не представляют для нас никакой пользы и могут быть удалены напрямую.
Теперь нам нужно принять решение в соответствии с предметом анализа, который является важным фактором для нашего обсуждения.
Как мы знаем, наши машины не понимают текстовые данные. Поэтому нам нужно либо удалить, либо преобразовать значения категориальных столбцов в числовые типы. Здесь мы удаляем столбцы с именами, потому что имя всегда будет уникальным и не оказывает большого влияния на целевые переменные. Для билета давайте сначала выведем 50 уникальных билетов.
df['Ticket'].unique()[:50]
Результат:
array(['A/5 21171', 'PC 17599', 'STON/O2. 3101282', '113803', '373450',
'330877', '17463', '349909', '347742', '237736', 'PP 9549',
'113783', 'A/5. 2151', '347082', '350406', '248706', '382652',
'244373', '345763', '2649', '239865', '248698', '330923', '113788',
'347077', '2631', '19950', '330959', '349216', 'PC 17601',
'PC 17569', '335677', 'C.A. 24579', 'PC 17604', '113789', '2677',
'A./5. 2152', '345764', '2651', '7546', '11668', '349253',
'SC/Paris 2123', '330958', 'S.C./A.4. 23567', '370371', '14311',
'2662', '349237', '3101295'], dtype=object)
Из приведенных выше примеров мы видим, что они состоят из двух похожих значений: «A/5 21171» состоит из «A/5» и «21171», что может повлиять на наши целевые переменные. Это будет случай разработки функций. где мы получаем новые функции из столбца или группы столбцов. В данном случае мы удаляем столбцы «Имя» и «Номер».
Укажите имя пользователя и столбцы для тикетов
df1 = df.drop(columns=['Name','Ticket'])
df1.shape
Результат:
(891, 10)
Обработка недостающих данных
Отсутствующие данные — распространённая проблема в реальных наборах данных, которая может возникать по разным причинам, таким как ошибки человека, системные сбои или проблемы со сбором данных. Для обработки отсутствующих данных можно использовать различные методы, такие как вменение, удаление или замена.
Давайте проверим % пропущенных значений по столбцам для каждой строки с помощью df.isnull(). Эта функция проверяет, являются ли значения нулевыми, и возвращает логические значения.и .sum() суммируют общее количество строк с нулевыми значениями, и мы делим его на общее количество строк в наборе данных, а затем умножаем, чтобы получить значения в %, то есть сколько значений из 100 являются нулевыми.
round((df1.isnull().sum()/df1.shape[0])*100,2)
Результат:
PassengerId 0.00
Survived 0.00
Pclass 0.00
Sex 0.00
Age 19.87
SibSp 0.00
Parch 0.00
Fare 0.00
Cabin 77.10
Embarked 0.22
dtype: float64
Мы не можем просто проигнорировать или удалить отсутствующие наблюдения. С ними нужно обращаться осторожно, так как они могут указывать на что-то важное.
Два наиболее распространенных способа обработки отсутствующих данных::
- Удаление наблюдений с пропущенными значениями.
- Тот факт, что значение отсутствовало, может быть информативным сам по себе.
- Кроме того, в реальном мире вам часто приходится делать прогнозы на основе новых данных, даже если некоторые характеристики отсутствуют!
Как видно из приведённого выше результата, в столбце «Каюта» 77% нулевых значений, в столбце «Возраст» 19,87%, а в столбце «Отплытие» 0,22% нулевых значений.
Таким образом, не стоит заполнять 77% нулевых значений. Поэтому мы удалим столбец «Каюта». В столбце «Прибытие» только 0,22% нулевых значений, поэтому мы удалим строки с нулевыми значениями в столбце «Прибытие».
df2 = df1.drop(columns='Cabin')
df2.dropna(subset=['Embarked'], axis=0, inplace=True)
df2.shape
Результат:
(889, 9)
- Вычисляем недостающие значения из прошлых наблюдений.
- Опять же, «отсутствие» почти всегда само по себе информативно, и вы должны сообщить своему алгоритму, если значение отсутствует.
- Даже если вы создадите модель для прогнозирования значений, вы не добавите никакой реальной информации. Вы просто усилите закономерности, уже выявленные другими функциями.
Мы можем использовать среднее значение или медианное значение для этого случая.
Примечание:
- Метод среднего значения подходит, когда данные распределены нормально и не содержат экстремальных значений.
- Метод медианного вменения предпочтительнее, когда данные содержат выбросы или искажены.
df3 = df2.fillna(df2.Age.mean())
df3.isnull().sum()
Результат:
PassengerId 0
Survived 0
Pclass 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
Обработка выбросов
Выбросы — это экстремальные значения, которые значительно отличаются от большинства данных. Они могут негативно влиять на анализ и производительность модели. Для обработки выбросов можно использовать такие методы, как кластеризация, интерполяция или преобразование.
Чтобы проверить наличие выбросов, мы обычно используем диаграмму размаха. Диаграмма размаха, также называемая диаграммой «ящик с усами», представляет собой графическое изображение распределения набора данных. Она показывает медиану, квартили и потенциальные выбросы. Линия внутри прямоугольника обозначает медиану, а сам прямоугольник обозначает межквартильный размах (IQR). Усы доходят до самых крайних значений, не являющихся выбросами, в пределах 1,5 IQR. Отдельные точки, выходящие за пределы «усов», считаются потенциальными выбросами. BOXplot диаграмма даёт простое для понимания представление о диапазоне данных и позволяет выявить выбросы или асимметрию в распределении.
Давайте построим прямоугольную диаграмму для данных столбца возраста.
import matplotlib.pyplot as plt
plt.boxplot(df3['Age'], vert=False)
plt.ylabel('Variable')
plt.xlabel('Age')
plt.title('Box Plot')
plt.show()
Результат:
.png)
Блок-схема
Как видно из приведённого выше графика «ящик с усами», в нашем наборе данных о возрасте есть выбросы. Значения меньше 5 и больше 55 являются выбросами.
mean = df3['Age'].mean()
std = df3['Age'].std()
lower_bound = mean - std*2
upper_bound = mean + std*2
print('Lower Bound :',lower_bound)
print('Upper Bound :',upper_bound)
df4 = df3[(df3['Age'] >= lower_bound)
& (df3['Age'] <= upper_bound)]
Результат:
Lower Bound : 3.705400107925648
Upper Bound : 55.578785285332785
Аналогичным образом мы можем удалить выбросы из оставшихся столбцов.
Преобразование данных
Преобразование данных — это перевод данных из одной формы в другую, чтобы сделать их более подходящими для анализа. Для преобразования данных можно использовать такие методы, как нормализация, масштабирование или кодирование.
Проверка достоверности данных
Проверка и подтверждение данных подразумевают обеспечение их точности и согласованности путём сравнения с внешними источниками или экспертными знаниями.
Для прогнозирования с помощью машинного обучения сначала мы разделяем независимые и целевые признаки. Здесь мы будем рассматривать только «пол», «возраст», «наличие братьев и сестер», «наличие родителей», «стоимость проезда», «место посадки»только в качестве независимых признаков и выживших в качестве целевых переменных. Потому что PassengerId не повлияет на уровень выживаемости.
X = df3[['Pclass','Sex','Age', 'SibSp','Parch','Fare','Embarked']]
Y = df3['Survived']
Форматирование данных
Форматирование данных подразумевает преобразование данных в стандартный формат или структуру, которые могут быть легко обработаны алгоритмами или моделями, используемыми для анализа. Здесь мы рассмотрим часто используемые методы форматирования данных, такие как масштабирование и нормализация.
Масштабирование
- Масштабирование предполагает преобразование значений признаков в определённый диапазон. При этом сохраняется форма исходного распределения, но меняется масштаб.
- Особенно полезно, когда признаки имеют разные масштабы, а некоторые алгоритмы чувствительны к величине признаков.
- К распространённым методам масштабирования относятся масштабирование по минимуму и максимуму и стандартизация (масштабирование по Z-оценке).
Масштабирование по минимальному и максимальному значениям: Масштабирование по минимальному и максимальному значениям преобразует значения в заданный диапазон, обычно от 0 до 1. Оно сохраняет исходное распределение и гарантирует, что минимальное значение преобразуется в 0, а максимальное — в 1.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
num_col_ = [col for col in X.columns if X[col].dtype != 'object']
x1 = X
x1[num_col_] = scaler.fit_transform(x1[num_col_])
x1.head()
Результат:
Pclass Sex Age SibSp Parch Fare Embarked
0 1.0 male 0.271174 0.125 0.0 0.014151 S
1 0.0 female 0.472229 0.125 0.0 0.139136 C
2 1.0 female 0.321438 0.000 0.0 0.015469 S
3 0.0 female 0.434531 0.125 0.0 0.103644 S
4 1.0 male 0.434531 0.000 0.0 0.015713 S
Стандартизация (масштабирование по Z-критерию): Стандартизация преобразует значения таким образом, чтобы среднее значение равнялось 0, а стандартное отклонение — 1. Она центрирует данные вокруг среднего значения и масштабирует их на основе стандартного отклонения. Стандартизация делает данные более подходящими для алгоритмов, которые предполагают нормальное распределение или требуют, чтобы признаки имели нулевое среднее значение и единичную дисперсию.
Z = (X - μ) / σ
Где,
- X = Данные
- μ = Среднее значение X
- σ = Стандартное отклонение X
Инструменты для очистки данных
Некоторые инструменты для очистки данных:
- OpenRefine
- Trifacta Wrangler
- TIBCO Clarity
- Cloudingo
- Этап качества IBM Infosphere
Преимущества очистки данных в машинном обучении:
- Повышение производительности модели: устранение ошибок, несоответствий и нерелевантных данных помогает модели лучше обучаться на этих данных.
- Повышенная точность: помогает обеспечить точность, согласованность и отсутствие ошибок в данных.
- Более наглядное представление данных: очистка данных позволяет преобразовать их в формат, который лучше отражает взаимосвязи и закономерности в данных.
- Улучшенное качество данных: повысьте качество данных, сделав их более надёжными и точными.
- Улучшенная защита данных: помогает выявлять и удалять конфиденциальную информацию, которая может поставить под угрозу безопасность данных.
Недостатки очистки данных в машинном обучении
- Занимает много времени: трудоёмкая задача, особенно для больших и сложных наборов данных.
- Склонность к ошибкам: очистка данных может приводить к ошибкам, поскольку она включает в себя преобразование и очистку данных, что может привести к потере важной информации или появлению новых ошибок.
- Затратный и ресурсоёмкий: ресурсоёмкий процесс, требующий значительных затрат времени, усилий и опыта. Он также может потребовать использования специализированных программных инструментов, что может увеличить стоимость и сложность очистки данных.
- Переобучение: очистка данных может непреднамеренно привести к переобучению, если удалить слишком много данных.
Заключение
Итак, мы рассмотрели четыре различных этапа очистки данных, чтобы сделать их более надёжными и получить хорошие результаты. После правильной очистки данных у нас будет надёжный набор данных, в котором не будет многих наиболее распространённых ошибок. Подводя итог, можно сказать, что очистка данных — это важный этап в процессе обработки данных, который включает в себя выявление и исправление ошибок, несоответствий и неточностей в данных для повышения их качества и удобства использования.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 29