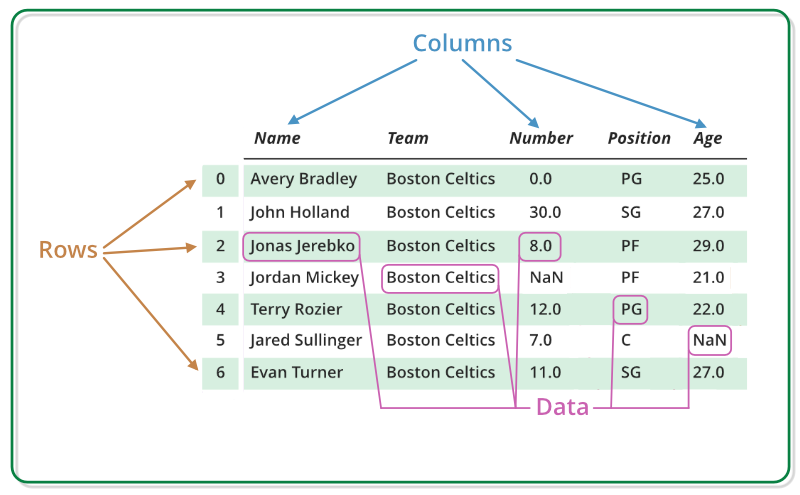
Pandas DataFrame — это двумерная изменяемая по размеру, потенциально неоднородная табличная структура данных с помеченными осями (строками и столбцами). Фрейм данных — это двумерная структура данных, то есть данные расположены в виде таблицы по строкам и столбцам. Pandas DataFrame состоит из трёх основных компонентов: данных, строк и столбцов.
Мы вкратце рассмотрим все эти базовые операции, которые можно выполнять с помощью Pandas DataFrame:
- Создание фрейма данных
- Работа со строками и столбцами
- Индексирование и выбор данных
- Работа с отсутствующими данными
- Перебор строк и столбцов
Создание фрейма данных Pandas
В реальном мире Pandas DataFrame создаётся путём загрузки наборов данных из существующего хранилища. Это может быть база данных SQL, файл CSV или Excel. Pandas DataFrame можно создать из списков, словарей, списков словарей и т. д.Фрейм данных можно создать разными способами. Вот несколько способов создания фрейма данных:
Создание фрейма данных с помощью списка: Фрейм данных можно создать с помощью одного списка или списка списков.
import pandas as pd
lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks']
df = pd.DataFrame(lst)
df
Вывод:

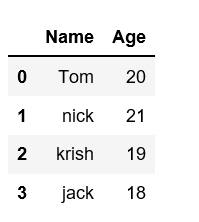
Создание DataFrame из словаря ndarray/списков: Чтобы создать DataFrame из словаря ndarray/списка, все массивы должны быть одинаковой длины. Если передан индекс, то длина индекса должна быть равна длине массивов. Если индекс не передан, то по умолчанию индекс будет равен range(n), где n — длина массива.
import pandas as pd
data = {'Name':['Tom', 'nick', 'krish', 'jack'], 'Age':[20, 21, 19, 18]}
df = pd.DataFrame(data)
df
Вывод:
Для получения более подробной информации обратитесь к Создание фрейма данных Pandas
Работа со строками и столбцами
Фрейм данных — это двумерная структура данных, то есть данные представлены в виде таблицы со строками и столбцами. Мы можем выполнять базовые операции со строками и столбцами, такие как выборка, удаление, добавление и переименование.
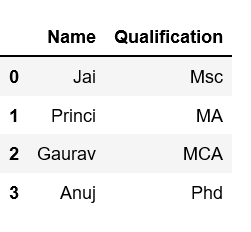
Выбор столбца: Чтобы выбрать столбец в Pandas DataFrame, мы можем получить к нему доступ, назвав его имя.
import pandas as pd
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
df = pd.DataFrame(data)
df[['Name', 'Qualification']]
Вывод:
Выбор строк: Pandas предоставляет уникальный метод для извлечения строк из фрейма данных. DataFrame.loc[] Метод используется для извлечения строк из фрейма данных Pandas. Строки также можно выбрать, передав целочисленное местоположение в функцию iloc[].
Примечание: в приведенных ниже примерах мы будем использовать nba.csv файл.
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
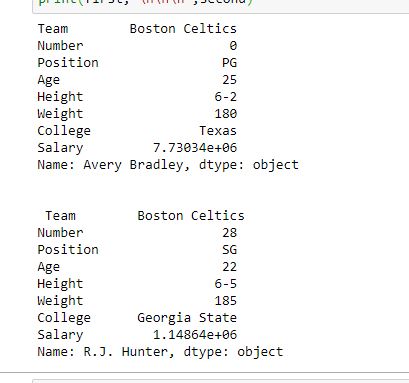
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)
Вывод:
Как показано на выходном изображении, были возвращены две серии, поскольку в обоих случаях был только один параметр.
Индексирование и выбор данных
Индексирование в pandas означает простой выбор определённых строк и столбцов данных из DataFrame. Индексирование может означать выбор всех строк и некоторых столбцов, некоторых строк и всех столбцов или некоторых строк и столбцов. Индексирование также может называться выбором подмножества.
Индексирование фрейма данных с помощью оператора индексации [] :
Оператор индексирования используется для обращения к квадратным скобкам, следующим за объектом. Индексы .loc и .iloc также используют оператор индексирования для выбора. В этом операторе индексирования для обращения к df[].
Выбор отдельных столбцов
Чтобы выбрать один столбец, мы просто вставляем название столбца в скобки
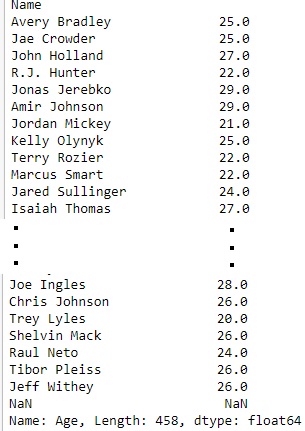
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
first = data["Age"]
print(first)
Вывод:
Индексирование фрейма данных с помощью .loc[ ] :
Эта функция выбирает данные по меткам строк и столбцов. Индексатор df.loc выбирает данные иначе, чем оператор индексации. Он может выбирать подмножества строк или столбцов. Он также может одновременно выбирать подмножества строк и столбцов.
Выбор одной строки
Чтобы выбрать одну строку с помощью .loc[], мы помещаем метку одной строки в .loc функцию.
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
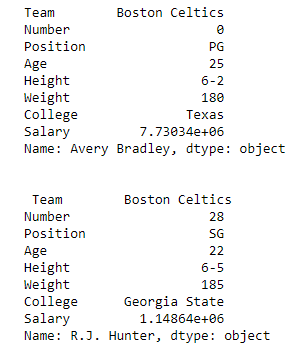
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)
Вывод:
Как показано на выходном изображении, были возвращены две серии, поскольку в обоих случаях был только один параметр.
Индексирование фрейма данных с помощью .iloc[ ] :
Эта функция позволяет нам извлекать строки и столбцы по позициям. Для этого нам нужно указать позиции нужных нам строк и позиции нужных нам столбцов. df.iloc Индексатор очень похож на df.loc , но для выбора использует только целочисленные позиции.
Выбор одной строки
Чтобы выбрать одну строку с помощью .iloc[], мы можем передать одно целое число в .iloc[] функцию.
import pandas as pd
data = pd.read_csv("nba.csv", index_col ="Name")
row2 = data.iloc[3]
print(row2)
Вывод:

Работа с отсутствующими данными
Пропущенные данные могут возникать, когда отсутствует информация по одному или нескольким элементам или по всему объекту. Пропущенные данные — очень серьёзная проблема в реальных условиях. Пропущенные данные также могут обозначаться как NA (недоступно) в pandas.
Проверка пропущенных значений с помощью isnull() и notnull() :
Чтобы проверить наличие пропущенных значений в Pandas DataFrame, мы используем функции isnull() и notnull(). Обе функции помогают проверить, является ли значение NaN или нет. Эти функции также можно использовать в Pandas Series для поиска нулевых значений в серии.
import pandas as pd
import numpy as np
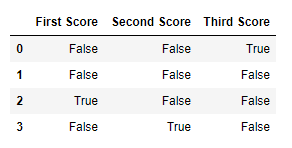
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.isnull()
Вывод:
Заполнение недостающих значений с помощью fillna(), replace() и interpolate() :
Чтобы заполнить нулевые значения в наборах данных, мы используем fillna(), replace() и interpolate() функции. Эти функции заменяют значения NaN на какое-то собственное значение. Все эти функции помогают заполнить нулевые значения в наборах данных фрейма данных. Функция Interpolate() в основном используется для заполнения NA значений в фрейме данных, но она использует различные методы интерполяции для заполнения пропущенных значений, а не жёстко задаёт значение.
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
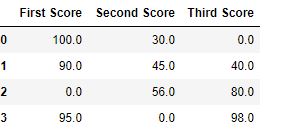
df.fillna(0)
Вывод:
Удаление недостающих значений с помощью dropna() :
Чтобы удалить нулевые значения из фрейма данных, мы использовали dropna() функцию, которая удаляет строки/столбцы наборов данных с нулевыми значениями различными способами.
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
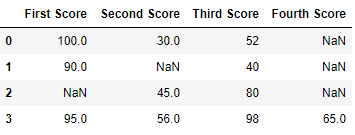
df = pd.DataFrame(dict)
df
Вывод:
Теперь мы удаляем строки, содержащие хотя бы одно значение Nan (нулевое значение).
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna()
Вывод:

Перебор строк и столбцов
Итерация — это общий термин, обозначающий последовательное выполнение действий с каждым элементом чего-либо. Фрейм данных Pandas состоит из строк и столбцов, поэтому для итерации по фрейму данных мы должны перебирать его как словарь.
Перебор строк :
Чтобы перебирать строки, мы можем использовать три функции: iteritems(), iterrows(), itertuples() . Эти три функции помогут перебирать строки.
import pandas as pd
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
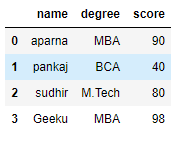
df = pd.DataFrame(dict)
df
Вывод:
Теперь мы применяем iterrows() функцию, чтобы получить каждый элемент строк.
import pandas as pd
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict)
for i, j in df.iterrows():
print(i, j)
print()
Вывод:

Перебор столбцов :
Чтобы перебрать столбцы, нам нужно создать список столбцов фрейма данных, а затем перебрать этот список, чтобы извлечь столбцы фрейма данных.
import pandas as pd
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict)
df
Вывод:
Теперь мы перебираем столбцы. Чтобы перебрать столбцы, сначала создадим список столбцов фрейма данных, а затем переберём этот список.
columns = list(df)
for i in columns:
print (df[i][2])
Вывод:

- Информация о материале
- Категория: Data Sciense
- Просмотров: 25
Обработка данных — это преобразование данных из одной формы в другую, более удобную и желаемую, то есть придание им более осмысленного и информативного характера. С помощью алгоритмов машинного обучения, математического моделирования и статистических знаний весь этот процесс можно автоматизировать. Результатом этого процесса могут быть любые желаемые формы, такие как графики, видео, диаграммы, таблицы, изображения и многое другое, в зависимости от выполняемой задачи и требований машины. Это может показаться простым, но когда речь идёт о таких крупных организациях, как Twitter, Facebook, административных органах, таких как парламент, ЮНЕСКО, и организациях здравоохранения, весь этот процесс должен быть очень структурированным. Итак, выполните следующие действия:
Обработка данных — важнейший этап в процессе машинного обучения (ML), поскольку она подготавливает данные для использования при создании и обучении моделей ML. Цель обработки данных — очистить, преобразовать и подготовить данные в формате, подходящем для моделирования.
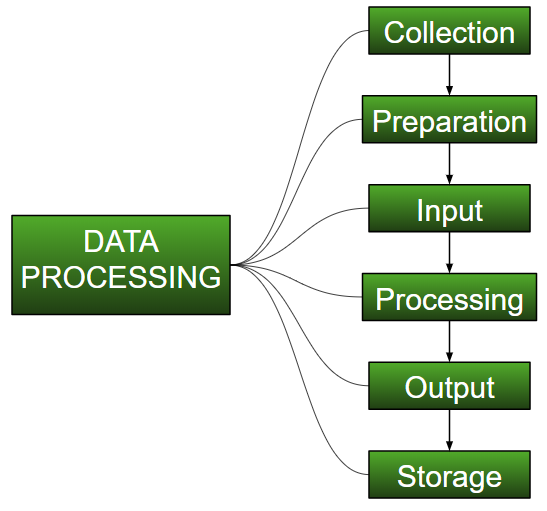
Основные этапы, связанные с обработкой данных, обычно включают:
1. Сбор данных — это процесс получения данных из различных источников, таких как датчики, базы данных или другие системы. Данные могут быть структурированными или неструктурированными и могут поступать в различных форматах, таких как текст, изображения или аудио.
2. Предварительная обработка данных. На этом этапе данные очищаются, фильтруются и преобразуются, чтобы их можно было использовать для дальнейшего анализа. Это может включать удаление пропущенных значений, масштабирование или нормализацию данных, а также их преобразование в другой формат.
3. Анализ данных. На этом этапе данные анализируются с помощью различных методов, таких как статистический анализ, алгоритмы машинного обучения или визуализация данных. Цель этого этапа — извлечь из данных полезную информацию или знания.
4. Интерпретация данных. На этом этапе необходимо интерпретировать результаты анализа данных и делать выводы на основе полученной информации. Также может потребоваться представить результаты в понятной и лаконичной форме, например в виде отчётов, информационных панелей или других визуализаций.
5. Хранение данных и управление ими. После обработки и анализа данных их необходимо хранить и управлять ими таким образом, чтобы обеспечить их безопасность и удобный доступ. Это может включать хранение данных в базе данных, облачном хранилище или других системах, а также реализацию стратегий резервного копирования и восстановления для защиты от потери данных.
6. Визуализация данных и составление отчётов. Наконец, результаты анализа данных представляются заинтересованным сторонам в понятном и удобном для использования формате. Это может включать создание визуализаций, отчётов или информационных панелей, которые подчёркивают ключевые выводы и тенденции в данных.
Существует множество инструментов и библиотек для обработки данных в машинном обучении, в том числе pandas для Python и инструмент преобразования и очистки данных в RapidMiner. Выбор инструментов будет зависеть от конкретных требований проекта, в том числе от размера и сложности данных, а также от желаемого результата.
- Коллекция :
Самый важный шаг при начале работы с машинным обучением — это наличие данных хорошего качества и точности. Данные можно собирать из любого проверенного источника, например, с сайта data.gov.in, Kaggle или из репозитория наборов данных UCI. Например, при подготовке к конкурсному экзамену студенты изучают лучшие учебные материалы, к которым у них есть доступ, чтобы получить наилучшие результаты. Точно так же высококачественные и точные данные упростят и улучшат процесс изучения модели, а во время тестирования модель будет выдавать самые современные результаты.
На сбор данных затрачивается огромное количество капитала, времени и ресурсов. Организации или исследователи должны решить, какие данные им нужны для выполнения своих задач или исследований.
Пример: Для работы с распознавателем выражений лица требуется множество изображений, содержащих различные выражения человеческого лица. Качественные данные гарантируют, что результаты модели достоверны и им можно доверять.
- Подготовка :
Собранные данные могут быть в необработанном виде, которые нельзя напрямую отправить на компьютер. Итак, это процесс сбора наборов данных из разных источников, анализа этих наборов данных и последующего создания нового набора данных для дальнейшей обработки и изучения. Эта подготовка может быть выполнена как вручную, так и с помощью автоматического подхода. Данные также могут быть подготовлены в числовой форме, что ускорит обучение модели.
Пример: изображение можно преобразовать в матрицу размером N X N, где значение каждой ячейки будет указывать на пиксель изображения. - Ввод :
Теперь подготовленные данные могут быть представлены в форме, которая не является машиночитаемой, поэтому для преобразования этих данных в машиночитаемую форму необходимы некоторые алгоритмы преобразования. Для выполнения этой задачи требуются высокие вычислительные мощности и точность. Пример: данные могут быть собраны из таких источников, как данные MNIST (изображения), комментарии в Twitter, аудиофайлы, видеоклипы. - Обработка :
На этом этапе требуются алгоритмы и методы машинного обучения, чтобы выполнять инструкции, предоставленные для большого объёма данных, с точностью и оптимальными вычислениями. - Вывод :
На этом этапе машина получает значимые результаты, которые пользователь может легко интерпретировать. Выводы могут быть представлены в виде отчётов, графиков, видео и т. д. - Хранение :
Это заключительный этап, на котором полученные результаты, данные модели и вся полезная информация сохраняются для дальнейшего использования.
Преимущества обработки данных в машинном обучении:
- Повышение производительности модели: обработка данных помогает повысить производительность модели машинного обучения за счёт очистки и преобразования данных в формат, подходящий для моделирования.
- Более точное представление данных: обработка данных позволяет преобразовать их в формат, который лучше отражает взаимосвязи и закономерности в данных, что упрощает обучение модели машинного обучения на этих данных.
- Повышенная точность: обработка данных помогает обеспечить их точность, согласованность и отсутствие ошибок, что может повысить точность модели машинного обучения.
Недостатки обработки данных в машинном обучении:
- Занимает много времени: обработка данных может занимать много времени, особенно для больших и сложных наборов данных.
- Склонность к ошибкам: обработка данных может быть подвержена ошибкам, поскольку она включает в себя преобразование и очистку данных, что может привести к потере важной информации или появлению новых ошибок.
- Ограниченное понимание данных: обработка данных может привести к ограниченному пониманию данных, поскольку преобразованные данные могут не отражать основные взаимосвязи и закономерности в данных.
Справочники:
- «Наука о данных с нуля: основы Python» Джоэла Груса.
- “Подготовка данных для интеллектуального анализа данных” Дориана Пайла.
- «Работа с данными на Python» Жаклин Казил и Кэтрин Джармул.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 27
Чтение файлов JSON с помощью Pandas
Чтобы прочитать файлы, мы используем функцию read_json() и передаём ей путь к файлу JSON, который хотим прочитать. После этого она возвращает «DataFrame» (таблицу со строками и столбцами), в которой хранятся данные. Если мы хотим прочитать файл, расположенный на удалённых серверах, то вместо локального пути мы передаём ссылку на его расположение. Кроме того, read_json() функция в Pandas предоставляет различные параметры для настройки процесса чтения
Различные способы чтения JSON с помощью Pandas
Существуют различные способы чтения JSON с помощью pandas или чтения файлов JSON с помощью pandas в виде фрейма данных. Здесь мы рассмотрим некоторые наиболее распространённые способы чтения JSON с помощью pandas или чтения файлов JSON с помощью pandas в виде фрейма данных.
- Используя
pd.read_json()Метод - Используя
JSONмодуль иpd.json_normalize()Метод - Используя методы pd.Dataframe()
Создание данных
Здесь код использует библиотеку Pandas для создания фрейма данных из вложенного словаря с именем data, где ключи «Один» и «Два» соответствуют столбцам. Каждый столбец содержит значения, связанные с числовыми индексами
import pandas as pd
data = {
"One": {
"0": 60,
"1": 60,
"2": 60,
"3": 45,
"4": 45,
"5": 60
},
"Two": {
"0": 110,
"1": 117,
"2": 103,
"3": 109,
"4": 117,
"5": 102
}
}
Читать JSON с помощью Pandas pd.read_json() Метод
В этом примере кода используется `pd.read_json()` для создания фрейма данных из строки JSON, полученной с помощью `json.dumps()`. Параметр ‘orient’ установлен в значение ‘index’ для правильного выравнивания данных. Наконец, он выводит полученный фрейм данных.
import pandas as pd
df_read_json = pd.read_json(json.dumps(data), orient='index')
print("DataFrame using pd.read_json() method:")
print(df_read_json)
Вывод
DataFrame using pd.read_json() method:
0 1 2 3 4 5
One 60 60 60 45 45 60
Two 110 117 103 109 117 102
Используя JSON модуль и pd.json_normalize() Метод
В этом примере кода словарь Python «data» преобразуется в строку JSON, а затем нормализуется в DataFrame с помощью метода `pd.json_normalize()` в Pandas. Наконец, он выводит полученный DataFrame, представляющий вложенную структуру JSON.
import pandas as pd
import json
json_data = json.dumps(data)
df_json_normalize = pd.json_normalize(json.loads(json_data))
print("\nDataFrame using JSON module and pd.json_normalize() method:")
print(df_json_normalize)
Вывод
DataFrame using pd.json_normalize() method:
One.0 One.1 One.2 One.3 One.4 One.5 Two.0 Two.1 Two.2 Two.3 \
0 60 60 60 45 45 60 110 117 103 109
Two.4 Two.5
0 117 102
Pandas считывает файл Json в Dataframe, используя методы ps.Dataframe()
Здесь мы создадим данные JSON, а затем создадим на их основе фрейм данных с помощью методов pd.Dataframe()
import pandas as pd
df = pd.DataFrame(data)
print(df)
Вывод
One Two
0 60 110
1 60 117
2 60 103
3 45 109
4 45 117
5 60 102
- Информация о материале
- Категория: Data Sciense
- Просмотров: 37
В этой статье мы обсудим, как читать текстовые файлы с помощью pandas на Python. Pandas позволяет загружать фреймы данных из внешних файлов и работать с ними. Набор данных может быть представлен в файлах разных типов.
используемый текстовый файл

Читать текстовые файлы с помощью Pandas
Ниже приведены методы, с помощью которых мы можем читать текстовые файлы с помощью Pandas:
- С помощью read_csv()
- С помощью read_table()
- С помощью read_fwf()
Читайте текстовые файлы с помощью Pandas с помощью read_csv()
Мы будем считывать текстовый файл с помощью pandas, используя функцию read_csv(). Вместе с текстовым файлом мы также передаём разделитель в виде одного пробела (‘ ‘), потому что в текстовых файлах разделитель обозначает каждое поле. В функции read_csv() можно передать три параметра.
Пример 1
В этом примере мы используем функцию read_csv() для чтения файла csv.
import pandas as pd
df = pd.read_csv("gfg.txt", sep=" ")
print(df)
Вывод:

Пример 2
В этом примере мы устанавливаем для поля значение заголовка None. Это создатель заголовка по умолчанию в выводе. И возьмёт первую строку текстового файла в качестве входных данных. Созданное имя заголовка будет числом, начинающим с 0.
import pandas as pd
df = pd.read_csv("gfg.txt", sep=" ", header=None)
print(df)
Выход:

Пример 3:
В приведенном выше выводе мы видим, что он создает заголовок, начинающийся с номера 0. Но мы также можем давать заголовкам имена. В этом примере мы увидим, как создать заголовок с именем с помощью pandas.
import pandas as pd
df = pd.read_csv("gfg.txt", sep=" ", header=None, names=["Team1", "Team2"])
print(df)
Чтение текстовых файлов с помощью Pandas с использованием read_table()
Мы можем прочитать данные из текстового файла с помощью read_table() в pandas. Эта функция считывает общий файл с разделителями в объект DataFrame. Эта функция по сути та же, что и функция read_csv(), но с разделителем = '\t' вместо запятой по умолчанию. Мы будем считывать данные с помощью функции read_table, устанавливая разделитель равным одному пробелу (' ').
Пример: В этом примере мы используем функцию read_table() для чтения таблиц.
import pandas as pd
df = pd.read_table("gfg.txt", delimiter=" ")
print(df)
Вывод:

Читать текстовые файлы с помощью Pandas с помощью read_fwf()
Fwf в функции read_fwf() означает фиксированную ширину. Мы можем использовать эту функцию для загрузки данных из файлов. Эта функция также поддерживает текстовые файлы. Мы будем считывать данные из текстовых файлов с помощью функции read_fwf() в pandas. Она также поддерживает итерацию или разбиение файла на части. Поскольку столбцы в текстовом файле были разделены строками фиксированной длины, функция read_fwf() считывает стандартные столбцы.
Пример: В этом примере мы используем read_fwf для чтения данных.
import pandas as pd
df = pd.read_fwf("gfg.txt")
print(df)
Выход:

- Информация о материале
- Категория: Data Sciense
- Просмотров: 34
Не всегда можно получить набор данных в формате CSV. Поэтому Pandas предоставляет нам функции для преобразования наборов данных в других форматах в фрейм данных. Файл Excel имеет формат «.xlsx».
Прежде чем мы начнем, нам нужно установить несколько библиотек.
pip install pandas
pip install xlrdТеперь мы можем погрузиться в код.
Пример 1: Прочитайте файл Excel.
import pandas as pd
df = pd.read_excel("sample.xlsx")
print(df)Пример 2: Чтобы выбрать конкретный столбец, мы можем передать параметр «index_col».
import pandas as pd
df = pd.read_excel("sample.xlsx", index_col = 0)
print(df)Пример 3: Если вам не нравится первоначальное название столбцов, вы можете изменить его на индексы с помощью параметра «заголовок».
import pandas as pd
df = pd.read_excel('sample.xlsx', header = None)
print(df)Пример 4: Если вы хотите изменить тип данных конкретного столбца, вы можете сделать это с помощью параметра «dtype».
import pandas as pd
df = pd.read_excel('sample.xlsx', dtype = {"Products": str, "Price":float})
print(df)Пример 5: Если у вас есть неизвестные значения, вы можете обработать их с помощью параметра «na_values». Он преобразует указанные неизвестные значения в «NaN»
import pandas as pd
df = pd.read_excel('sample.xlsx', na_values =['item1', 'item2'])
print(df)
- Информация о материале
- Категория: Data Sciense
- Просмотров: 34