Анализ данных — это методическое исследование и интерпретация данных, основанные на принятии решений в современной динамичной среде. По мере того, как квалифицированные аналитики начинают понимать данные, становятся обязательными шесть ключевых этапов этого процесса. Каждый этап — от определения проблем до представления информации — играет жизненно важную роль в преобразовании необработанных данных в практические знания.
В этой статье мы рассмотрим шесть основных этапов анализа данных, уделяя особое внимание каждому этапу для получения значимых выводов.
Что такое анализ данных?
Сбор, преобразование и систематизация данных для получения выводов, составления прогнозов на будущее и принятия обоснованных решений на основе анализа данных. Специалист, занимающийся анализом данных, называется аналитик данных.
Существует огромный спрос на аналитические данные, поскольку в настоящее время объём данных стремительно растёт. Анализ данных используется для поиска возможных решений бизнес-задач. Преимущество работы в качестве аналитика данных заключается в том, что они могут работать в любой сфере, которая им нравится: здравоохранение, управление экономикой, технологии, финансы, бизнес. Принятие решений на основе данных является важной частью анализа данных.Это значительно упростило процесс анализа. Анализ данных состоит из шести этапов.
Этапы процесса анализа данных

- Определите проблему или исследовательский вопрос
- Сбор данных
- Очистка данных
- Анализ данных
- Предварительный просмотр данных
- Представление данных
На каждом этапе есть свой процесс и инструменты для составления выводов на основе данных.
1.Определите проблему или исследовательский вопрос
На первом этапе процесса анализа данных возникает проблема/бизнес-задача.Аналитик должен понять проблему и ожидания в качестве альтернативы решения. Заинтересованная сторона — это человек, который вложил свои деньги и ресурсы в проект. Аналитик должен уметь задавать разные вопросы, чтобы найти правильное решение проблем. Аналитик должен найти первопричину проблемы, чтобы полностью ее понять. Аналитик должен убедиться, что его ничто не мешает во время анализа проблемы. Эффективно общайтесь с заинтересованными организациями и другими коллегами, чтобы полностью понять суть проблемы. Вопросы, которые необходимо задать себе на этапе «Спросите»:
- Какие проблемы упоминаются моими заинтересованными сторонами?
- Чего они ожидают от решений?
2. Сбор данных
Второй шаг — это подготовка или сбор данных. Этот шаг включает в себя сбор данных и их сохранение для дальнейшего анализа. Аналитик должен собрать данные в соответствии с поставленной группой из нескольких источников. Данные должны быть собраны из различных источников, внутренних или внешних. Внутренние данные — это данные, доступные в организации, в которой вы работаете, а внешние данные — это данные, доступные в источниках, отличных от вашей организации. Данные, собранные людьми из природных ресурсов, называются собственными данными. Данные, которые происходят и продаются, содержат данные производителей. Данные о том, что они проезжают мимо, содержат информацию о производителях. Распространёнными источниками, из которых поступают данные, являются интервью, опросы, обратная связь, анкеты. Собранные данные могут храниться в таблице или базе данных SQL.
Электронная таблица — это цифровой рабочий лист, состоящий из нескольких строк и столбцов, в то время как база данных содержит таблицу с возможностями для работы с данными. Электронные таблицы используются для хранения нескольких тысяч или первых тысяч данных, в то время как в базе данных хранятся данные, когда необходимо хранить слишком много строк. Лучшими инструментами для хранения данных являются таблицы MS Excel или Google в электронных таблицах, а также множество баз данных, таких как Oracle, Microsoft.
3. Очистка данных
Третий шаг — это очистка и обработка данных. После сбора данных из нескольких источников наступает время очистка данные. Чистые данные — это данные без орфографических ошибок, избыточности и ненужной информации. Чистота данных во многом зависит от их мнения. Могут быть дубликаты данных или данные могут быть в неправильном формате, поэтому ненужные данные удаляются и очищаются. Для очистки данных в SQL и Excel предусмотрены различные функции. Это один из самых важных этапов анализа данных, поскольку чистые и отформатированные данные позволяют находить решения. Наиболее важной частью этапов процесса является проверка того, являются ли ваши данные предвзятыми или нет. Предвзятость — это действие в пользу группы/сообщества при игнорировании остальных. Предвзятость категорически запрещена, поскольку она может указывать на данные общего анализа. Аналитик данных должен убедиться, что при сборе данных наблюдается каждая группа.
4. Данные анализа
Четвертый шаг — Анализ Очищенные данные используются для анализа и выявления тенденций. Они также выполняют вычисления и объединяют данные для получения лучших результатов. Для выполнения вычислений используются такие инструменты, как Excel или SQL. Эти инструменты предоставляют встроенные функции для выполнения вычислений или примеры кода, написанного на SQL для выполнения вычислений. С помощью Excel мы можем создавать сводные таблицы и выполнять вычисления, а SQL создает временные таблицы для выполнения вычислений. Языки программирования — еще один способ решения задач. Они значительно упрощают решение задач, предоставляя пакеты.
5. Визуализация данных
Пятый шаг — визуализация данных. Нет ничего более убедительного, чем визуализация. Преобразованные данные теперь должны быть преобразованы в визуальные (диаграммы, графики). Причина создания визуализации данных заключается в том, что могут быть люди, в основном заинтересованные стороны, не имеющие технического образования. Визуализация определения для простого понимания сложных данных. Tableau и Looker — два популярных инструмента, используемых для наглядной визуализации данных. Tableau — это простой инструмент для перерисовки, который помогает создавать впечатляющие визуализации. Looker — это инструмент обработки данных, который напрямую опирается на базу данных и визуализацию. Аналитики данных в равной степени используют Tableau и Looker для создания визуализаций. В Python есть несколько пакетов, которые обеспечивают прекрасную визуализацию данных. Презентация дана на основе полученных данных. Обмен информацией с членами команды и заинтересованными структурами поможет сделать более обоснованные выводы. Это помогает принимать более обоснованные решения и приводит к лучшим результатам.
6. Представление данных
Представление данных включает в себя преобразование необработанной информации в формат, который легко понять и который имеет значение для различных заинтересованных сторон. Этот процесс включает в себя создание визуальных представлений, таких как диаграммы, графики и таблицы, для эффективной передачи закономерностей, тенденций и идей, полученных в результате анализа данных. Цель состоит в том, чтобы облегчить понимание сложной информации, сделав ее доступной как для технической, так и для нетехнической аудитории. Эффективное представление данных включает в себя продуманный выбор методов визуализации на основе характера данных и конкретного предполагаемого сообщения. Оно выходит за рамки простого отображения и превращается в повествование, в котором докладчик интерпретирует результаты, подчёркивает ключевые моменты и направляет аудиторию по сюжету, который разворачивают данные. Будь то отчёты, презентации или интерактивные панели мониторинга, искусство представления данных включает в себя баланс простоты и глубины, гарантируя, что аудитория сможет легко понять значимость представленной информации и использовать её для принятия обоснованных решений.
Заключение
В заключение отметим, что способность анализа данных преобразовывать сложную информацию в понятные визуальные повествования позволяет организациям принимать обоснованные решения. Эффективно переданные идеи, основанные на данных, играют ключевую роль в решении бизнес-задач и способствуют постоянному совершенствованию в различных областях.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 41

В этой статье мы обсудим, как выполнять анализ данных с помощью Python. Мы обсудим все виды анализа данных, т.е. анализ числовых данных с помощью NumPy, табличных данных с помощью Pandas, визуализацию данных Matplotlib и исследовательский анализ данных.
Анализ данных с помощью Python
Анализ данных - это метод сбора, преобразования и организации данных для прогнозирования будущего и принятия обоснованных решений на основе данных. Это также помогает находить возможные решения бизнес-задач. Для анализа данных существует шесть шагов. Это:
- Спросите или укажите требования к данным
- Подготовка или сбор данных
- Очистка и обработка
- Анализировать
- Поделиться
- Действовать или сообщать

Анализ числовых данных с помощью NumPy
NumPy - это пакет обработки массивов на Python, предоставляющий высокопроизводительный объект многомерного массива и инструменты для работы с этими массивами. Это фундаментальный пакет для научных вычислений с использованием Python.
Массивы в NumPy
Массив NumPy представляет собой таблицу элементов (обычно чисел), все одного и того же типа, проиндексированную набором положительных целых чисел. В Numpy количество измерений массива называется рангом массива. Набор целых чисел, задающих размер массива по каждому измерению, известен как форма массива.
Создание массива NumPy
Массивы NumPy могут быть созданы несколькими способами с различными рангами. Он также может быть создан с использованием различных типов данных, таких как списки, кортежи и т.д. Тип результирующего массива определяется по типу элементов в последовательностях. NumPy предлагает несколько функций для создания массивов с исходным содержимым-заполнителем. Они сводят к минимуму необходимость увеличения массивов, что является дорогостоящей операцией.
Создайте массив с помощью numpy.empty(shape, dtype=float, order=’C’)
import numpy as np
b = np.empty(2, dtype = int)
print("Matrix b : \n", b)
a = np.empty([2, 2], dtype = int)
print("\nMatrix a : \n", a)
c = np.empty([3, 3])
print("\nMatrix c : \n", c)Вывод:
Matrix b : [1065353216 1065353216] Matrix a : [[-1253146667 -1065797382] [ 19889362 322685255]] Matrix c : [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]
Создайте массив, используя numpy.zeros(shape, dtype = None, order = ‘C’)
import numpy as np
b = np.zeros(2, dtype = int)
print("Matrix b : \n", b)
a = np.zeros([2, 2], dtype = int)
print("\nMatrix a : \n", a)
c = np.zeros([3, 3])
print("\nMatrix c : \n", c)Вывод:
Matrix b :
[0 0]
Matrix a :
[[0 0]
[0 0]]
Matrix c :
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
Операции с массивами Numpy
Арифметические операции
- Дополнение:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing addition using arithmetic operator
add_ans = a+b
print(add_ans)
# Performing addition using numpy function
add_ans = np.add(a, b)
print(add_ans)
# The same functions and operations can be used for
# multiple matrices
c = np.array([1, 2, 3, 4])
add_ans = a+b+c
print(add_ans)
add_ans = np.add(a, b, c)
print(add_ans)Вывод:
[ 7 77 23 130]
[ 7 77 23 130]
[ 8 79 26 134]
[ 7 77 23 130]
- Вычитание:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing subtraction using arithmetic operator
sub_ans = a-b
print(sub_ans)
# Performing subtraction using numpy function
sub_ans = np.subtract(a, b)
print(sub_ans)Вывод:
[ 3 67 3 70]
[ 3 67 3 70]
- Умножение:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing multiplication using arithmetic
# operator
mul_ans = a*b
print(mul_ans)
# Performing multiplication using numpy function
mul_ans = np.multiply(a, b)
print(mul_ans)Вывод:
[ 10 360 130 3000]
[ 10 360 130 3000]
- Подразделение:
import numpy as np
# Defining both the matrices
a = np.array([5, 72, 13, 100])
b = np.array([2, 5, 10, 30])
# Performing division using arithmetic operators
div_ans = a/b
print(div_ans)
# Performing division using numpy functions
div_ans = np.divide(a, b)
print(div_ans)Вывод:
[ 2.5 14.4 1.3 3.33333333]
[ 2.5 14.4 1.3 3.33333333]
Индексирование массива NumPy
Индексацию можно выполнить в NumPy, используя массив в качестве индекса. В случае среза возвращается видовая или поверхностная копия массива, но в индексном массиве возвращается копия исходного массива. Массивы Numpy могут быть проиндексированы вместе с другими массивами или любой другой последовательностью, за исключением кортежей. Последний элемент индексируется на -1, предпоследний на -2 и так далее.
Индексирование массива Python NumPy
# Python program to demonstrate
# the use of index arrays.
import numpy as np
# Create a sequence of integers from
# 10 to 1 with a step of -2
a = np.arange(10, 1, -2)
print("\n A sequential array with a negative step: \n",a)
# Indexes are specified inside the np.array method.
newarr = a[np.array([3, 1, 2 ])]
print("\n Elements at these indices are:\n",newarr)Вывод:
A sequential array with a negative step:
[10 8 6 4 2]
Elements at these indices are:
[4 8 6]
Нарезка массива NumPy
Рассмотрим синтаксис x[obj], где x — это массив, а obj — индекс. Объект среза является индексом в случае базового среза. Базовый срез происходит, когда obj равно :
- объект среза, имеющий вид start: stop: step
- целое число
- или набор объектов slice и целых чисел
Все массивы, созданные с помощью базовой нарезки, всегда являются представлением исходного массива.
# Python program for basic slicing.
import numpy as np
# Arrange elements from 0 to 19
a = np.arange(20)
print("\n Array is:\n ",a)
# a[start:stop:step]
print("\n a[-8:17:1] = ",a[-8:17:1])
# The : operator means all elements till the end.
print("\n a[10:] = ",a[10:])Вывод:
Array is:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
a[-8:17:1] = [12 13 14 15 16]
a[10:] = [10 11 12 13 14 15 16 17 18 19]
Многоточие также можно использовать вместе с базовым разделением. Многоточие (...) - это количество : объектов,
необходимых для создания кортежа выборки той же длины, что и размеры массива.
# Python program for indexing using basic slicing with ellipsis
import numpy as np
# A 3 dimensional array.
b = np.array([[[1, 2, 3],[4, 5, 6]],
[[7, 8, 9],[10, 11, 12]]])
print(b[...,1]) #Equivalent to b[: ,: ,1 ]Вывод:
[[ 2 5]
[ 8 11]]
Трансляция массива NumPy
Термин «расширение» относится к тому, как NumPy обрабатывает массивы с разными размерами во время арифметических операций, что приводит к определённым ограничениям. Меньший массив расширяется за счёт большего массива, чтобы они имели совместимые формы.
Предположим, что у нас есть большой набор данных, где каждая запись представляет собой список параметров. В Numpy у нас есть двумерный массив, где каждая строка — это запись, а количество строк — это размер набора данных. Предположим, что мы хотим применить какое-то масштабирование ко всем этим данным, чтобы каждый параметр получил свой собственный коэффициент масштабирования или, скажем, чтобы каждый параметр был умножен на какой-то коэффициент.
Просто чтобы иметь четкое представление, давайте посчитаем калории в продуктах, используя разбивку по макроэлементам. Грубо говоря, калорийность пищи состоит из жиров (9 калорий на грамм), белков (4 калорийных грамма) и углеводов (4 калорийных грамма). Итак, если мы перечислим некоторые продукты (наши данные) и для каждого продукта перечислим его распределение по макронутриентам (параметры), мы можем затем умножить каждое питательное вещество на его калорийность (применить масштабирование), чтобы вычислить калорийность каждого продукта.
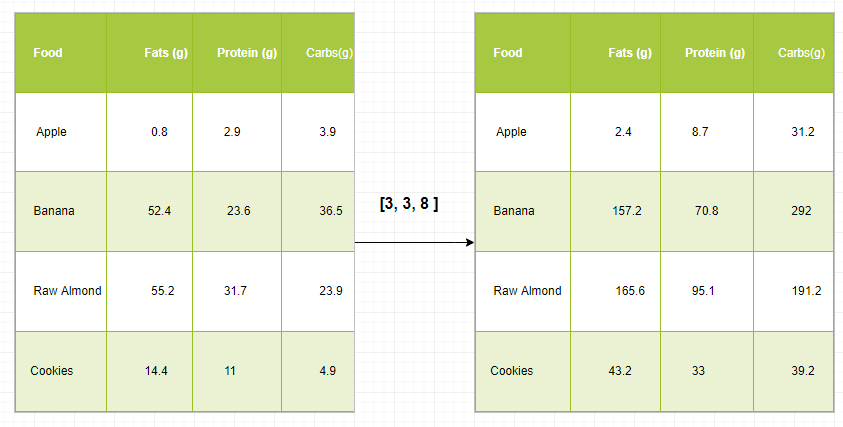
С помощью этого преобразования мы теперь можем вычислять любую полезную информацию. Например, сколько калорий содержится в каком-либо продукте или, зная состав моего ужина, сколько калорий я получил из белка и так далее.
Давайте посмотрим на наивный способ произвести это вычисление с помощью Numpy:
import numpy as np
macros = np.array([
[0.8, 2.9, 3.9],
[52.4, 23.6, 36.5],
[55.2, 31.7, 23.9],
[14.4, 11, 4.9]
])
# Create a new array filled with zeros,
# of the same shape as macros.
result = np.zeros_like(macros)
cal_per_macro = np.array([3, 3, 8])
# Now multiply each row of macros by
# cal_per_macro. In Numpy, `*` is
# element-wise multiplication between two arrays.
for i in range(macros.shape[0]):
result[i, :] = macros[i, :] * cal_per_macro
resultВывод:
array([[ 2.4, 8.7, 31.2],
[157.2, 70.8, 292. ],
[165.6, 95.1, 191.2],
[ 43.2, 33. , 39.2]])
Правила трансляции: Объедините два массива вместе, следуя этим правилам:
- Если массивы не имеют одинакового ранга, то добавляйте перед формой массива более низкого ранга 1s, пока обе формы не будут иметь одинаковую длину.
- Два массива совместимы по одному измерению, если они имеют одинаковый размер по этому измерению или если один из массивов имеет размер 1 по этому измерению.
- Массивы могут транслироваться вместе, если они совместимы со всеми измерениями.
- После трансляции каждый массив ведёт себя так, как если бы его форма была равна максимальному значению из форм двух входных массивов.
- В любом измерении, где один массив имеет размер 1, а другой массив имеет размер больше 1, первый массив ведёт себя так, как если бы он был скопирован в этом измерении.
import numpy as np
v = np.array([12, 24, 36])
w = np.array([45, 55])
# To compute an outer product we first
# reshape v to a column vector of shape 3x1
# then broadcast it against w to yield an output
# of shape 3x2 which is the outer product of v and w
print(np.reshape(v, (3, 1)) * w)
X = np.array([[12, 22, 33], [45, 55, 66]])
# x has shape 2x3 and v has shape (3, )
# so they broadcast to 2x3,
print(X + v)
# Add a vector to each column of a matrix X has
# shape 2x3 and w has shape (2, ) If we transpose X
# then it has shape 3x2 and can be broadcast against w
# to yield a result of shape 3x2.
# Transposing this yields the final result
# of shape 2x3 which is the matrix.
print((X.T + w).T)
# Another solution is to reshape w to be a column
# vector of shape 2X1 we can then broadcast it
# directly against X to produce the same output.
print(X + np.reshape(w, (2, 1)))
# Multiply a matrix by a constant, X has shape 2x3.
# Numpy treats scalars as arrays of shape();
# these can be broadcast together to shape 2x3.
print(X * 2)Вывод:
[[ 540 660]
[1080 1320]
[1620 1980]]
[[ 24 46 69]
[ 57 79 102]]
[[ 57 67 78]
[100 110 121]]
[[ 57 67 78]
[100 110 121]]
[[ 24 44 66]
[ 90 110 132]]
Анализ данных С помощью Pandas
Python Pandas используется для реляционных или помеченных данных и предоставляет различные структуры данных для манипулирования такими данными и временными рядами. Эта библиотека построена поверх библиотеки NumPy. Этот модуль обычно импортируется как:
import pandas as pd
Здесь pd упоминается как псевдоним Pandas. Однако нет необходимости импортировать библиотеку, используя псевдоним, это просто помогает писать меньший объем кода при каждом вызове метода или свойства. Pandas обычно предоставляют две структуры данных для манипулирования данными, это:
- Серии
- Фрейм данных
Серии:
Серия Pandas представляет собой одномерный помеченный массив, способный содержать данные любого типа (integer, string, float, объекты python и т.д.). Метки оси в совокупности называются индексами. Серия Pandas - это не что иное, как столбец на листе Excel. Метки не обязательно должны быть уникальными, но должны иметь хэшируемый тип. Объект поддерживает индексацию как на основе целых чисел, так и на основе меток и предоставляет множество методов для выполнения операций с индексом.

Его можно создать с помощью функции Series(), загрузив набор данных из существующего хранилища, такого как SQL, база данных, CSV-файлы, файлы Excel и т.д., Или из структур данных, таких как списки, словари и т.д.
Серия создания Python Pandas
import pandas as pd
import numpy as np
# Creating empty series
ser = pd.Series()
print(ser)
# simple array
data = np.array(['g', 'e', 'e', 'k', 's'])
ser = pd.Series(data)
print(ser)Вывод:
Series([], dtype: object) 0 g 1 e 2 e 3 k 4 s dtype: object
Фрейм данных:
Pandas DataFrame — это двумерная изменяемая по размеру, потенциально неоднородная табличная структура данных с маркированными осями (строками и столбцами). Фрейм данных — это двумерная структура данных, то есть данные расположены в виде таблицы по строкам и столбцам. Pandas DataFrame состоит из трёх основных компонентов: данных, строк и столбцов.
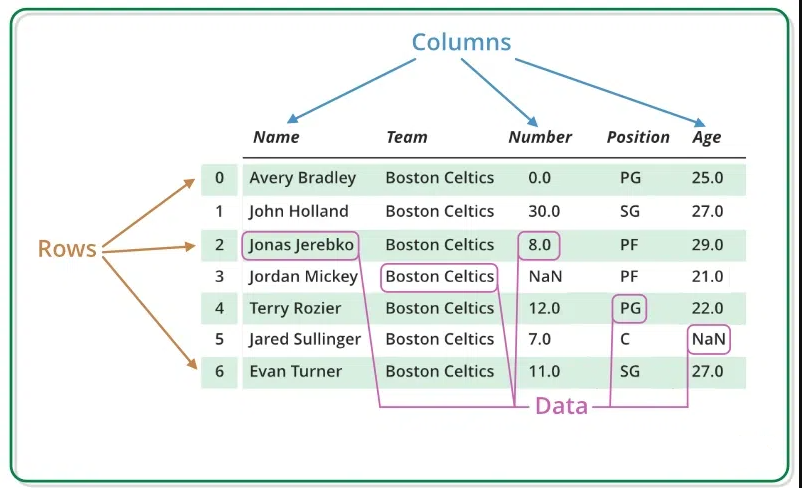
Его можно создать с помощью метода Dataframe() и, как и серию, он может состоять из данных разных типов и структур.
Python Pandas Создает фрейм данных
import pandas as pd
# Calling DataFrame constructor
df = pd.DataFrame()
print(df)
# list of strings
lst = ['G', 'F', 'G', 'i',
'p', 'f', 'G']
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
dfВывод:
Создание фрейма данных из CSV
Мы можем создать фрейм данных из CSV-файлов с помощью функции read_csv().
Python Pandas читают CSV
import pandas as pd
# Reading the CSV file
df = pd.read_csv("Iris.csv")
# Printing top 5 rows
df.head()Вывод:
- Информация о материале
- Категория: Data Sciense
- Просмотров: 36
Анализ данных является важным аспектом современных процессов принятия решений в различных секторах, включая бизнес, здравоохранение, финансы и академические круги. Поскольку организации ежедневно генерируют огромные объемы данных, понимание того, как извлекать значимую информацию из этих данных, становится решающим. В этой статье мы рассмотрим фундаментальные концепции анализа данных, его типы, значение, методы и инструменты, используемые для эффективного анализа. Мы также рассмотрим распространенные запросы, связанные с анализом данных, внеся ясность в его определение и применение в различных областях.
Содержание
- Что Вы подразумеваете под анализом данных?
- Определение анализа данных
- Анализ данных в науке о данных
- Анализ данных в СУБД
- Почему важен анализ данных?
- Процесс анализа данных
- Анализ данных: приемы и методики
Что Вы подразумеваете под анализом данных?
В современном мире, основанном на данных, организации полагаются на анализ данных для выявления закономерностей, тенденций и взаимосвязей в своих данных. Будь то оптимизация операций, повышение удовлетворенности клиентов или прогнозирование будущих тенденций, эффективный анализ данных помогает заинтересованным сторонам принимать обоснованные решения. Термин анализ данных относится к систематическому применению статистических и логических методов для описания, обобщения и оценки данных. Этот процесс может включать преобразование необработанных данных в более понятный формат, выявление значимых закономерностей и формулирование выводов на основе полученных результатов.
Когда мы спрашиваем: «Что вы подразумеваете под анализом данных?» — это, по сути, относится к практике изучения наборов данных для получения выводов о содержащейся в них информации. Этот процесс можно разбить на несколько этапов, в том числе:
- Сбор данных: получение релевантных данных из различных источников, которыми могут быть базы данных, опросы, датчики или веб-скрапинг.
- Очистка данных: выявление и исправление неточностей или несоответствий в данных для обеспечения их качества и надежности.
- Преобразование данных: изменение данных для приведения их в подходящий для анализа формат, которое может включать нормализацию, агрегацию или создание новых переменных.
- Анализ данных: применение статистических методов и алгоритмов для изучения данных, выявления тенденций и получения значимых результатов.
- Интерпретация данных: преобразование результатов в практические рекомендации или выводы, которые служат основой для принятия решений.
Выполняя эти действия, организации могут превратить необработанные данные в ценный актив, который помогает в стратегическом планировании и повышает эффективность работы.
Чтобы лучше понять, давайте рассмотрим анализ данных на примере. Представьте себе розничную компанию, которая хочет повысить эффективность продаж. Компания собирает данные о покупках клиентов, демографических характеристиках и сезонных тенденциях.
Проведя анализ данных, компания может обнаружить, что:
- Клиенты в возрасте от 18 до 25 лет с большей вероятностью будут покупать определённые товары в праздничные сезоны.
- Продажи значительно увеличиваются, когда предлагаются рекламные скидки.
Основываясь на этих данных, компания может адаптировать свои маркетинговые стратегии, чтобы ориентироваться на более молодых клиентов с помощью специальных рекламных акций в пиковые сезоны, что в конечном итоге приведёт к увеличению продаж и удовлетворённости клиентов.
Определение анализа данных
Анализ данных можно определить как:
«Процесс проверки, очистки, преобразования и моделирования данных для получения полезной информации, составления выводов и поддержки принятия решений».
Это определение подчеркивает системный подход, применяемый при анализе данных, подчеркивая важность не только получения аналитической информации, но и обеспечения целостности и качества используемых данных.
Анализ данных в науке о данных
Область науки о данных в значительной степени зависит от анализа данных для получения информации из больших наборов данных. Анализ данных в науке о данных относится к методам и процессам, используемым для манипулирования данными, выявления тенденций и создания прогностических моделей, помогающих в принятии решений.
Специалисты по обработке данных используют различные аналитические методы, такие как:
- Статистический анализ: применение статистических тестов для проверки гипотез или понимания взаимосвязей между переменными.
- Машинное обучение: использование алгоритмов, позволяющих системам извлекать уроки из шаблонов данных и делать прогнозы.
- Визуализация данных: создание графических представлений данных для облегчения понимания и передачи информации.
Эти методы играют жизненно важную роль, позволяя организациям эффективно использовать свои данные, гарантируя, что они остаются конкурентоспособными и реагируют на изменения рынка.
Анализ данных в СУБД
Еще одна область, в которой анализ данных играет важнейшую роль, — это системы управления базами данных (СУБД). Анализ данных в СУБД включает в себя запросы и обработку данных, хранящихся в базах данных, для получения значимой информации. Аналитики используют SQL (язык структурированных запросов) для выполнения таких операций, как:
- Поиск данных: извлечение конкретных данных из больших наборов данных с помощью запросов.
- Агрегирование: обобщение данных для получения информации на более высоком уровне.
- Фильтрация: сужение данных для фокусировки на конкретных критериях.
Понимание того, как выполнять эффективный анализ данных в СУБД,важно для специалистов, которые регулярно работают с базами данных, поскольку это позволяет им получать информацию, которая может повлиять на бизнес-стратегии.
Почему важен анализ данных?
Анализ данных имеет решающее значение для принятия обоснованных решений, выявления закономерностей, тенденций и идей в наборах данных. Он улучшает стратегическое планирование, выявляет возможности и проблемы, повышает эффективность и способствует более глубокому пониманию сложных явлений в различных отраслях и сферах.
- Принятие обоснованных решений: анализ данных служит основой для принятия обоснованных решений, предоставляя информацию о прошлых результатах, текущих тенденциях и возможных будущих результатах.
- Бизнес-аналитика: проанализированные данные помогают организациям получить конкурентное преимущество, выявляя тенденции рынка, предпочтения клиентов и области для улучшения.
- Решение проблем: помогает выявлять и решать проблемы в системе или процессе, обнаруживая закономерности или аномалии, требующие внимания.
- Оценка эффективности: анализ данных позволяет оценить показатели эффективности, что дает организациям возможность измерять успех, выявлять области для улучшения и ставить реалистичные цели.
- Управление рисками: понимание закономерностей в данных помогает прогнозировать риски и управлять ими, позволяя организациям смягчать последствия потенциальных проблем.
- Оптимизация процессов: анализ данных выявляет неэффективные процессы, что позволяет оптимизировать их и сократить расходы.
Процесс анализа данных
А Анализ данных позволяет преобразовывать необработанные доступные данные в значимую информацию для вашего бизнеса и принятия решений. Хотя существует несколько различных способов сбора и интерпретации этих данных, большинство процессов анализа данных выполняют одни и те же шесть общих шагов.
- Определите цели и вопросы: Четко определите цели анализа и конкретные вопросы, на которые вы хотите ответить. Установите четкое понимание того, на какие выводы или решения должны опираться проанализированные данные.
- Сбор данных: Собирайте релевантные данные из различных источников. Обеспечьте целостность, качество и полноту данных. Организуйте данные в формате, подходящем для анализа. Существует два типа данных: качественные и количественные данные.
- Очистка и предварительная обработка данных: устраняют пропущенные значения, обрабатывают выбросы и преобразуют данные в удобный формат. Этапы очистки и предварительной обработки имеют решающее значение для обеспечения точности и достоверности анализа.
- Исследовательский анализ данных (EDA): Проведите исследовательский анализ, чтобы понять характеристики данных. Визуализируйте распределения, выявляйте закономерности и рассчитывайте сводные статистические данные. EDA помогает формулировать гипотезы и совершенствовать подход к анализу.
- Статистический анализ или моделирование: применение соответствующих статистических методов или техник моделирования для ответа на поставленные вопросы. Этот этап включает в себя проверку гипотез, создание прогностических моделей или выполнение любого анализа, необходимого для получения значимых выводов на основе данных.
- Интерпретация и коммуникация: Интерпретируйте результаты в контексте первоначальных целей. Донесите результаты до сведения заинтересованных сторон с помощью отчетов, визуализаций или презентаций. Четко сформулируйте идеи, выводы и рекомендации на основе анализа, чтобы помочь в принятии обоснованных решений.
Анализ данных: приемы и методики
При обсуждении вопроса об анализе данных можно использовать несколько методов в зависимости от характера данных и решаемых вопросов. Эти методы в широком смысле можно разделить на три типа:
Существуют различные методы анализа данных, каждый из которых подходит для конкретных целей и типов данных. Основные методы анализа данных:
1. Описательный анализ
Описательный анализ является основополагающим, поскольку он дает необходимую информацию о прошлых результатах. Понимание того, что произошло, имеет решающее значение для принятия обоснованных решений при анализе данных. Например, анализ данных в науке о данных часто начинается с описательных методов для обобщения и визуализации тенденций данных.
2. Диагностический анализ
Диагностический анализ тесно связан с описательным анализом. В то время как описательный анализ выясняет, что произошло в прошлом, диагностический анализ, с другой стороны, выясняет, почему это произошло, какие меры были приняты в то время или как часто это происходило. Тщательно анализируя данные, компании могут ответить на вопрос: «что вы подразумеваете под анализом данных?» Они могут оценить, какие факторы повлияли на конкретные результаты, и получить более чёткое представление об эффективности своей работы.
3. Прогностический анализ
Благодаря прогнозированию будущих тенденций на основе исторических данных, прогностический анализ позволяет организациям подготовиться к предстоящим возможностям и вызовам.
Этот тип анализа отвечает на вопрос о том, что такое анализ данных, используя тенденции данных для прогнозирования будущего поведения и тенденций. Эта возможность жизненно важна для стратегического планирования и управления рисками в бизнес-операциях.
4. Предписывающий анализ
Директивный анализ - это передовой метод, который использует прогностический анализ идей и предлагает практические рекомендации, указывающие лицам, принимающим решения, наилучший курс действий. Он выходит за рамки простого анализа данных и предлагает оптимальные решения на основе потенциальных сценариев будущего, тем самым удовлетворяя потребность в структурированном подходе к принятию решений.
5. Статистический анализ
Статистический анализ необходим для обобщения данных, помогая в определении ключевых характеристик и понимании взаимосвязей внутри наборов данных. Этот анализ может выявить важные закономерности, которые лежат в основе более широких стратегий и политик, тем самым позволяя аналитикам обеспечить надежный обзор практики анализа данных в организации.
6. Регрессионный анализ
Регрессионный анализ - это статистический метод, широко используемый в анализе данных для моделирования взаимосвязи между зависимой переменной и одной или несколькими независимыми переменными. Этот метод особенно полезен для установления взаимосвязи между переменными, что делает его жизненно важным для прогнозирования и стратегического планирования, поскольку аналитики часто определяют анализ данных примерами, в которых используются методы регрессии для иллюстрации этих концепций.
7. Когортный анализ
Изучая конкретные группы с течением времени, когортный анализ помогает понять поведение клиентов и улучшить стратегии удержания. Такой подход позволяет компаниям адаптировать свои услуги к различным сегментам, тем самым эффективно используя хранение и анализ больших данных для повышения вовлеченности и удовлетворенности клиентов.
8. Анализ временных рядов
Анализ временных рядов имеет решающее значение для любой области, где точки данных собираются с течением времени, что позволяет выявлять тенденции и прогнозировать их. Компании могут использовать этот метод для анализа сезонных тенденций и прогнозирования будущих продаж, отвечая на вопрос о том, что вы понимаете под анализом данных в контексте временных данных.
9. Факторный анализ
Факторный анализ — это статистический метод, который исследует глубинные взаимосвязи между набором наблюдаемых переменных. Он выявляет скрытые факторы, которые влияют на наблюдаемые закономерности, упрощая сложные структуры данных. Этот метод незаменим для уменьшения размерности, выявления скрытых закономерностей и интерпретации больших наборов данных.
10. Анализ текста
Анализ текста включает в себя извлечение ценной информации из неструктурированных текстовых данных. Используя методы обработки естественного языка и машинного обучения, он позволяет извлекать настроения, ключевые темы и закономерности из больших объёмов текста. Анализ отзывов клиентов, настроений в социальных сетях и многого другого демонстрирует практическое применение анализа данных в реальных сценариях.
Инструменты для анализа данных
Существует несколько инструментов для эффективного анализа данных. Эти инструменты могут варьироваться от простых приложений для работы с электронными таблицами до сложного статистического программного обеспечения. Среди популярных инструментов можно выделить:
- SAS : SAS — это язык программирования, разработанный Институтом SAS для расширенной аналитики, многомерного анализа, бизнес-аналитики, управления данными и прогнозной аналитики. SAS был разработан для очень специфических целей, и каждый день в обширную уже существующую коллекцию не добавляются новые мощные инструменты, что делает его менее масштабируемым для определённых задач.
- Microsoft Excel : Это важное приложение для работы с электронными таблицами, которое может быть полезно для учета расходов, построения графиков данных и выполнения простых манипуляций и поиска и / или создания сводных таблиц для предоставления желаемых обобщенных отчетов по большим наборам данных, содержащих важные данные. Он написан на C #, C ++ и .NET Framework, а его стабильная версия была выпущена в 2016 году.
- R : Это один из ведущих языков программирования для выполнения сложных статистических вычислений и графики. Это бесплатный язык с открытым исходным кодом, который можно запускать на различных платформах UNIX, Windows и macOS. Он также имеет интерфейс командной строки, который прост в использовании. Однако его сложно освоить, особенно людям, не имеющим предварительных знаний о программировании.
- Python: это мощный язык программирования высокого уровня, который используется для программирования общего назначения. Python поддерживает как структурированное, так и функциональное программирование. Его обширная коллекция библиотек делает его очень полезным для анализа данных. Знание Tensorflow, Theano, Keras, Matplotlib, Scikit-learn и Keras поможет вам приблизиться к мечте стать инженером по машинному обучению.
- Tableau Public: Tableau Public — это бесплатное программное обеспечение, разработанное публичной компанией «Tableau Software», которое позволяет пользователям подключаться к любой электронной таблице или файлу и создавать интерактивные визуализации данных. Его также можно использовать для создания карт, информационных панелей с обновлением в реальном времени для удобной презентации в Интернете. Результатами можно делиться через социальные сети или напрямую с клиентом, что делает его очень удобным в использовании.
- Knime : Knime, Konstanz Information Miner — это бесплатное программное обеспечение для анализа данных с открытым исходным кодом. Оно также используется в качестве платформы для составления отчётов и интеграции. Оно включает в себя интеграцию различных компонентов для машинного обучения и интеллектуального анализа данных с помощью модульной оболочки для передачи данных. Оно написано на Java и разработано компанией KNIME.com AG. Его можно использовать в различных операционных системах, таких как Linux, OS X и Windows.
- Power BI: сервис бизнес-аналитики, предоставляющий интерактивную визуализацию и возможности бизнес-аналитики с простым интерфейсом.
Заключение
В заключение отметим, что анализ данных— это жизненно важный процесс, который включает в себя изучение, очистку, преобразование и моделирование данных для получения значимой информации, необходимой для принятия решений. Учитывая огромные объёмы ежедневно генерируемых данных, организации должны использовать возможности анализа данных, чтобы оставаться конкурентоспособными и реагировать на рыночные тенденции.
Понимание различных типов анализа данных, доступных инструментов и методов, используемых в этой области, крайне важно для специалистов, стремящихся эффективно использовать данные. По мере того, как мы вступаем в эпоху цифровых технологий, значение анализа данных будет продолжать расти, определяя будущее отраслей и влияя на стратегические решения по всему миру.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 28
В этом разделе учебного пособия по Python мы рассмотрим обработку исключений Python то, как Python справляется с неожиданными ошибками, позволяя вам писать надежный и отказоустойчивый код. Мы рассмотрим обработку файлов, включая чтение из файлов и запись в файлы, прежде чем перейти к обработке исключений с помощью блоков try и except. Вы также узнаете об определяемых пользователем исключениях и встроенных типах исключений Python.
- Обработка файлов Python
- Чтение файлов на Python
- Запись / создание файлов на Python
- Обработка исключений
- Пользовательское исключение
- Встроенное исключение
- Попробуйте и изучите Python
- Информация о материале
- Категория: Data Sciense
- Просмотров: 30
В этом разделе Python OPPs мы изучим основные принципы объектно-ориентированного программирования (ООП) на Python. От инкапсуляции до наследования, полиморфизма, абстрактных классов и итераторов мы рассмотрим основные концепции, которые позволят вам создавать модульный, повторно используемый и масштабируемый код.
- Классы и объекты Python
- Полиморфизм
- Наследование
- Аннотация
- Инкапсуляция
- Итераторы
- Информация о материале
- Категория: Data Sciense
- Просмотров: 32