Web - парсинг - это метод извлечения данных с веб-сайтов. Во время веб-серфинга многие веб-сайты запрещают пользователю сохранять данные для личного использования. В этой статье расскажем о web-соскабливания, применения, методы, инструменты, и проблемы с веб-страниц.
Содержание
- Что такое web - парсинг?
- Использование web - парсинг
- Методы очистки web-страниц
- Инструмент для очистки web-страниц
- Легализация web - парсинг
- Проблемы web - парсинг
- Будущее web - парсинг данных
Что такое Web - парсинг?
Web - парсинг — это автоматизация процесса извлечения данных с веб-сайтов. Один из способов — копирование и вставка данных, что утомительно и занимает много времени, поэтому это делается с помощью программного обеспечения для web - парсинг, известного как web - парсинг. Они автоматически загружают и извлекают данные с веб-сайтов в соответствии с требованиями пользователя. Они могут быть созданы специально для работы с одним сайтом или могут быть настроены для работы с любым сайтом.
Браузеры для парсинга в наши дни популярны для проектов по парсингу данных благодаря своей эффективности. Одним из таких браузеров является Bright Data Scraping Browser. Это автоматизированный браузер, разработанный специально для парсинга данных. Его эффективные возможности разблокировки веб-сайтов, совместимость с Puppeteer и Playwright, масштабируемость и технология искусственного интеллекта делают этот инструмент популярным на рынке. Помимо экономии вашего времени и ресурсов при выполнении задач по парсингу данных, он также отлично подходит для автоматизации любых других действий в браузере. Он может обходить самые строгие блокировки сайтов и системы обнаружения ботов.
Использование Web - парсинг
Web - парсинг находит множество применений как на профессиональном, так и на личном уровне. В зависимости от потребностей на разных уровнях, web - парсинг может использоваться по-разному:
- Мониторинг бренда и анализ конкурентов: web - парсинг используется для получения отзывов клиентов о конкретной услуге или продукте, чтобы понять, что клиент думает об этом. Он также извлекает данные о конкурентах в структурированном, удобном для использования формате.
- Машинное обучение: Машинное обучение — это процесс искусственного интеллекта, при котором машине позволяется учиться и совершенствоваться на основе своего опыта, а не программироваться. Для этого требуется большой объём данных с миллионов сайтов, которые извлекаются с помощью программного обеспечения для web - парсинг.
- Анализ финансовых данных: web - парсинг используется для ведения записей о фондовом рынке в удобном формате и, следовательно, для получения аналитической информации.
- Анализ социальных сетей: используется для извлечения данных из социальных сетей, чтобы оценить тенденции среди клиентов и их реакцию на кампанию.
- Мониторинг SEO: Поисковая оптимизация — это оптимизация видимости и рейтинга веб-сайта в различных поисковых системах, таких как Google, Yahoo, Bing и т. д. Web - парсинг используется для понимания того, как со временем меняется рейтинг контента.
Методы очистки веб-страниц
Существует два способа извлечения данных с веб-сайтов: ручной и автоматизированный.
- Методы извлечения данных вручную: копирование и вставка содержимого сайта вручную относится к этому методу. Несмотря на то, что это утомительно, занимает много времени и повторяется, это эффективный способ сбора данных с сайтов, на которых приняты меры по защите от сбора данных, например, обнаружение ботов.
- Автоматизированные методы извлечения данных: программное обеспечение для web - парсинг используется для автоматического извлечения данных с сайтов в соответствии с требованиями пользователя.
- Парсинг HTML: Парсинг — это процесс преобразования чего-либо в понятную форму для анализа по частям. Иными словами, это преобразование информации в одной форме в другую форму, с которой проще работать. Парсинг HTML — это процесс получения кода и извлечения из него нужной информации в соответствии с требованиями пользователя. В основном выполняется с помощью JavaScript, а целью, как следует из названия, являются HTML-страницы.
- Разбор DOM: Модель объектного документа является официальной рекомендацией Консорциума Всемирной паутины. Она определяет интерфейс, который позволяет пользователю изменять и обновлять стиль, структуру и содержимое XML-документа.
- Программное обеспечение для Web - парсинг: в настоящее время существует множество инструментов для Web - парсинг, которые можно настроить в соответствии с потребностями пользователей для извлечения необходимой информации с миллионов веб-сайтов.
Инструмент для очистки веб-страниц
Инструменты для web - парсинг специально разработаны для извлечения данных из интернета. Также известные как инструменты для сбора данных или извлечения данных, они полезны для всех, кто пытается собрать конкретные данные с веб-сайтов, поскольку предоставляют пользователю структурированные данные, извлечённые с нескольких веб-сайтов. Вот некоторые из самых популярных инструментов для web - парсинг:
- Bright Data
- Import.io
- Webhose.io
- Dexi.io
- Scrapinghub
Легализация web - парсинга
Легализация web - парсинга — деликатная тема. В зависимости от того, как он используется, он может быть как благом, так и проклятием. С одной стороны, web - парсинг с помощью хорошего бота позволяет поисковым системам индексировать веб-контент, а сервисам сравнения цен — экономить деньги и время клиентов. Но web - парсинг может быть перенаправлен на более вредоносные и жестокие цели. Web - парсинг может быть связан с другими формами вредоносной автоматизации, которые называются «плохими ботами», и которые позволяют осуществлять другие вредоносные действия, такие как атаки типа «отказ в обслуживании», конкурентный сбор данных, захват учётных записей, кража данных и т. д. Законность web - парсинга — это серая зона, которая со временем становится всё более размытой. Хотя web - парсинг технически ускоряют просмотр, загрузку, копирование и вставку данных, web - парсинг также является основной причиной увеличения числа случаев нарушения авторских прав, условий использования и других действий, которые наносят серьёзный ущерб бизнесу компании.
Проблемы web - парсинга
Помимо вопроса о законности web - парсинга, существуют и другие проблемы, которые затрудняют web - парсинг.
- Хранилище данных: при масштабном извлечении данных будет генерироваться большой объем информации, которую необходимо хранить. Если инфраструктура хранилища данных не будет построена должным образом, поиск, хранение и экспорт этих данных станут трудоемкой задачей. Следовательно, для масштабного извлечения данных необходима идеальная система хранения данных без каких-либо недостатков и ошибок.
- Изменения в структуре веб-сайта: Каждый веб-сайт периодически обновляет свой пользовательский интерфейс, чтобы сделать его более привлекательным и удобным. Это также требует различных структурных изменений. Поскольку веб-скраперы настраиваются в соответствии с элементами кода веб-сайта на тот момент, они тоже требуют изменений. Таким образом, они также требуют еженедельных изменений, чтобы ориентироваться на нужный веб-сайт для сбора данных, поскольку неполная информация о структуре веб-сайта приведёт к некорректному сбору данных.
- Технологии защиты от парсинга: некоторые веб-сайты используют технологии защиты от парсинга, которые предотвращают любые попытки парсинга. Они применяют алгоритм динамического кодирования, чтобы предотвратить вмешательство ботов, и используют механизм блокировки IP-адресов. Чтобы обойти такие технологии защиты от парсинга, требуется много времени и денег.
- Качество извлеченных данных: записи, которые не соответствуют требуемому качеству информации, повлияют на общую целостность данных. Обеспечение соответствия извлеченных данных требованиям к качеству — сложная задача, поскольку она должна выполняться в режиме реального времени.
Будущее web - парсинга данных
Поскольку существуют некоторые проблемы и возможности для сбора данных, можно с уверенностью сказать, что те, кто занимается сбором данных без злого умысла, рискуют создать моральный риск, когда они нацеливаются на компании и получают их данные. Однако, поскольку мы находимся на пороге трансформации данных, сбор данных в сочетании с большими данными может предоставить компаниям информацию о рынке и помочь им выявить важные тенденции и закономерности, а также найти лучшие возможности и решения. Поэтому будет правильно сказать, что в скором времени сбор данных может стать лучше.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 10
Что такое EDA?
Исследовательский анализ данных (EDA) — это метод, используемый для анализа и обобщения наборов данных. Большинство методов EDA предполагают использование графиков.
Набор данных Titanic –
Это один из самых популярных наборов данных, используемых для понимания основ машинного обучения. Он содержит информацию обо всех пассажирах на борту корабля RMS Titanic, который, к сожалению, потерпел кораблекрушение. Этот набор данных можно использовать для прогнозирования того, выжил данный пассажир или нет.
CSV-файл можно загрузить с Kaggle.
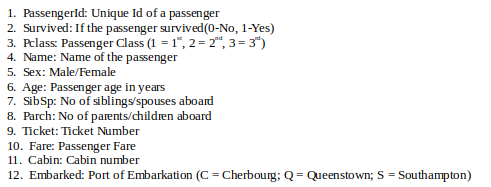
Код: загрузка данных с помощью Pandas
#importing pandas library
import pandas as pd
#loading data
titanic = pd.read_csv('...\input\train.csv')
Seaborn:
Это библиотека Python, используемая для статистической визуализации данных. Seaborn, созданная на основе Matplotlib, обеспечивает более удобный интерфейс и простоту использования. Её можно установить с помощью следующей команды:
pip3 install seaborn
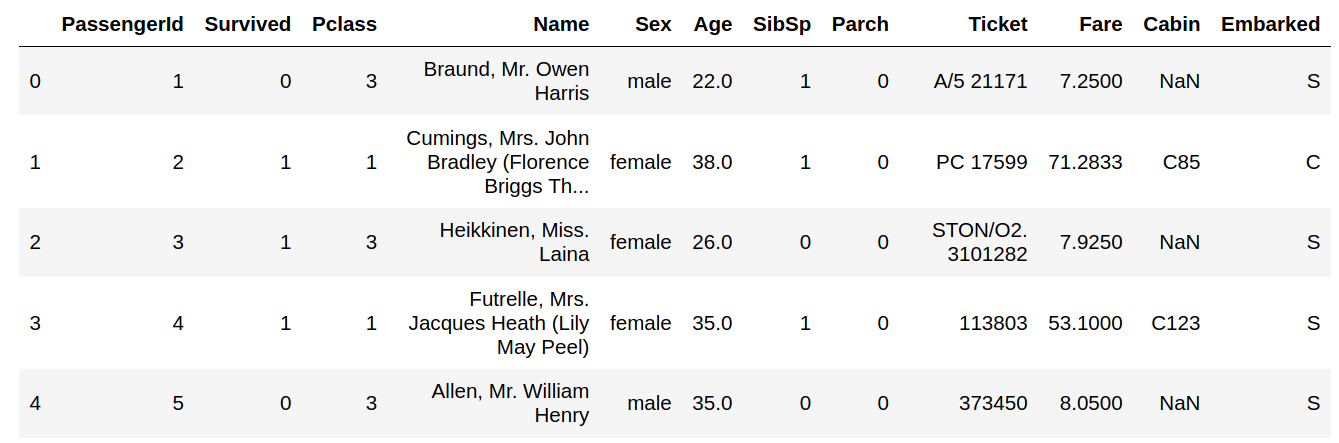
Код: Печатающая головка данных
# View first five rows of the dataset
titanic.head()
Вывод :
Код: проверка нулевых значений
titanic.isnull().sum()
Вывод :
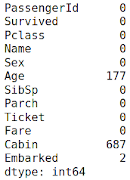
Столбцы с нулевыми значениями: «Возраст», «Каюта», «Отплытие». Их нужно будет заполнить соответствующими значениями позже.
Характеристики: В наборе данных Titanic примерно следующие типы характеристик:
- Категориальные/номинальные: переменные, которые можно разделить на несколько категорий, но без указания порядка или приоритета.
Например, место отправления (C = Шербур; Q = Квинстаун; S = Саутгемптон) - Бинарный тип: подтип категориальных признаков, где переменная имеет только две категории.
Например: пол (мужской/женский) - Порядковые: они похожи на категориальные признаки, но имеют порядок (то есть их можно отсортировать).
Например, Pclass (1, 2, 3) - Непрерывные: они могут принимать любое значение между минимальным и максимальным значениями в столбце.
Например, возраст, стоимость проезда - Количество: они представляют собой количество значений переменной.
Например, SibSp, Parch - Бесполезные: они не влияют на конечный результат модели машинного обучения. В данном случае идентификатор пассажира, имя, номер каюты и билет могут относиться к этой категории.
Код: графический анализ
import seaborn as sns
import matplotlib.pyplot as plt
# Countplot
sns.catplot(x ="Sex", hue ="Survived",
kind ="count", data = titanic)
Вывод :
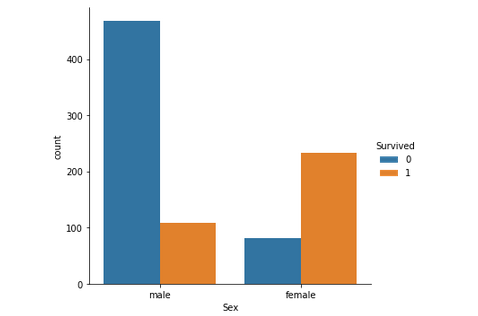
Просто взглянув на график, можно предположить, что выживаемость мужчин составляет около 20%, а женщин — около 75%. Таким образом, пол пассажира играет важную роль в определении того, выживет ли он.
Код: Pclass (порядковый номер) против Survived
# Group the dataset by Pclass and Survived and then unstack them
group = titanic.groupby(['Pclass', 'Survived'])
pclass_survived = group.size().unstack()
# Heatmap - Color encoded 2D representation of data.
sns.heatmap(pclass_survived, annot = True, fmt ="d")
Вывод:
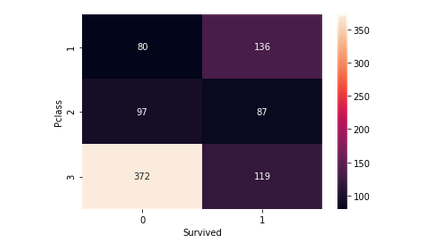
Это помогает определить, была ли выживаемость пассажиров более высокого класса выше, чем у пассажиров более низкого класса, или наоборот. У пассажиров 1-го класса шансы на выживание выше по сравнению с пассажирами 2-го и 3-го классов. Это означает, что Pclass вносит большой вклад в выживаемость пассажиров.
Код: возраст (непрерывная функция) против выжившего
# Violinplot Displays distribution of data
# across all levels of a category.
sns.violinplot(x ="Sex", y ="Age", hue ="Survived",
data = titanic, split = True)
Вывод :
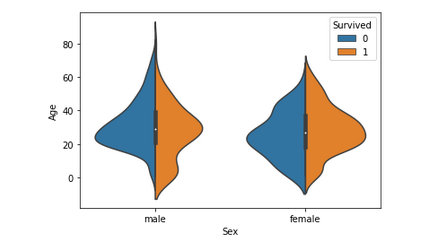
На этом графике представлен возрастной диапазон спасённых мужчин, женщин и детей. Уровень выживаемости составляет –
- Полезно для детей.
- Высоко для женщин в возрасте 20-50 лет.
- С возрастом меньше для мужчин.
Поскольку столбец «Возраст» важен, недостающие значения необходимо заполнить либо с помощью столбца «Имя» (определив возраст по обращению — «мистер», «миссис» и т. д.), либо с помощью регрессора.
После этого шага можно создать ещё один столбец — «Диапазон возраста» (на основе столбца «Возраст») и снова проанализировать данные.
Код: факторный график для Family_Size (функция Count) и размера семьи.
# Adding a column Family_Size
titanic['Family_Size'] = 0
titanic['Family_Size'] = titanic['Parch']+titanic['SibSp']
# Adding a column Alone
titanic['Alone'] = 0
titanic.loc[titanic.Family_Size == 0, 'Alone'] = 1
# Factorplot for Family_Size
sns.factorplot(x ='Family_Size', y ='Survived', data = titanic)
# Factorplot for Alone
sns.factorplot(x ='Alone', y ='Survived', data = titanic)
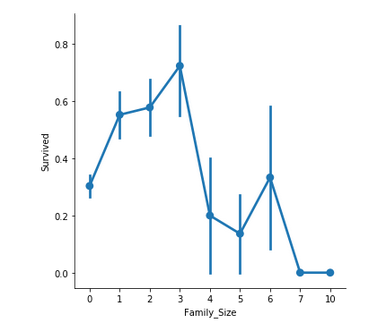
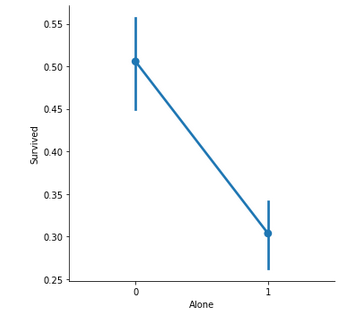
Family_Size обозначает количество человек в семье пассажира. Он рассчитывается путем суммирования столбцов SibSp и Parch соответствующего пассажира. Кроме того, другой столбец только добавляется, чтобы проверить свои шансы на выживание одинокого пассажира на один с семьей.
Важные замечания –
- Если пассажир один, вероятность выживания ниже.
- Если в семье больше 5 человек, шансы на выживание значительно снижаются.
Код : Гистограмма для тарифа (непрерывная функция)
# Divide Fare into 4 bins
titanic['Fare_Range'] = pd.qcut(titanic['Fare'], 4)
# Barplot - Shows approximate values based
# on the height of bars.
sns.barplot(x ='Fare_Range', y ='Survived',
data = titanic)
Вывод :
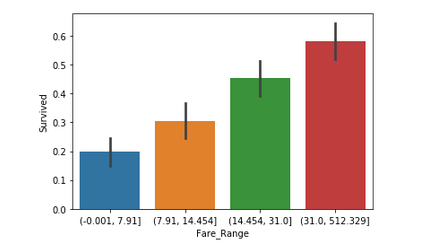
Стоимость проезда обозначает сумму, которую пассажир заплатил за проезд. Поскольку значения в этом столбце непрерывны, их необходимо разделить на отдельные категории (как в случае с функцией Возраст), чтобы получить чёткое представление. Можно сделать вывод, что если пассажир заплатил более высокую стоимость проезда, то вероятность выживания выше.
Код: графики категориального подсчета для запущенной функции
# Countplot
sns.catplot(x ='Embarked', hue ='Survived',
kind ='count', col ='Pclass', data = titanic)
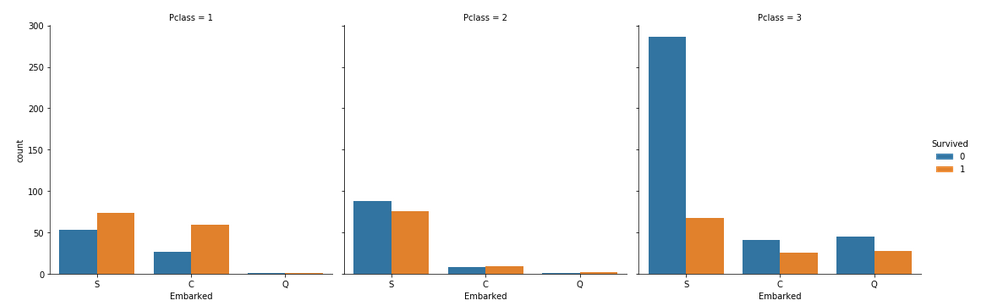
Вот некоторые примечательные наблюдения:
- Большинство пассажиров сели на борт в S. Таким образом, недостающие значения можно заполнить с помощью S.
- Большинство пассажиров 3-го класса поднялись на борт из Q.
- S выглядит удачным вариантом для пассажиров первого и второго классов по сравнению с третьим классом.
Заключение :
- Столбцы, которые можно удалить, следующие:
- PassengerId, Name, Ticket, Cabin: это строки, которые нельзя классифицировать и которые не сильно влияют на результат.
- Age, Fare: вместо этого сохраняются соответствующие столбцы диапазона.
- Титанические объёмы данных можно проанализировать с помощью множества графических методов, а также корреляций между столбцами, как описано в этой статье.
- После завершения EDA полученный набор данных можно использовать для прогнозирования.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 10
В этой статье мы обсудим, как выполнить исследовательский анализ данных на примере набора данных Iris. Прежде чем продолжить чтение этой статьи, мы использовали две терминологии: EDA и набор данных Iris. Давайте вкратце рассмотрим эти наборы данных.
Что такое предварительный анализ данных?
Исследовательский анализ данных (EDA)— это метод анализа данных с использованием некоторых визуальных техник. С помощью этого метода мы можем получить подробную информацию о статистической сводке данных. Мы также сможем работать с дублирующимися значениями, выбросами, а также выявлять тенденции или закономерности, присутствующие в наборе данных.
Теперь давайте кратко рассмотрим набор данных Iris.
Набор данных Iris
Если вы разбираетесь в науке о данных, то, должно быть, знакомы с набором данных Iris. Если нет, то не волнуйтесь, мы обсудим это здесь.
Набор данных Iris считается «Hello World» для науки о данных. Он содержит пять столбцов: длина лепестка, ширина лепестка, длина чашелистика, ширина чашелистика и тип вида. Ирис — это цветущее растение. Исследователи измерили различные характеристики разных цветков ириса и записали их в цифровом виде.
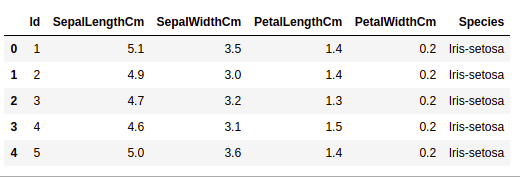
Вы можете скачать файл Iris.csv по ссылке. Теперь мы будем использовать библиотеку Pandas для загрузки этого CSV-файла и преобразуем его в фрейм данных. Метод read_csv() используется для чтения CSV-файлов.
import pandas as pd
# Reading the CSV file
df = pd.read_csv("Iris.csv")
# Printing top 5 rows
df.head()
Вывод:
Получение информации о наборе данных
Мы будем использовать параметр shape, чтобы получить форму набора данных.
Пример:
df.shape
Вывод:
(150, 6)
Мы видим, что фрейм данных содержит 6 столбцов и 150 строк.
Теперь давайте рассмотрим столбцы и их типы данных. Для этого мы воспользуемся методом info().
Пример:
df.info()
Вывод:
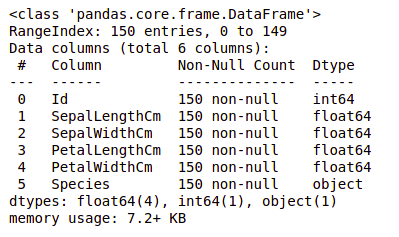
Мы видим, что только в одном столбце есть категориальные данные, а все остальные столбцы имеют числовой тип с ненулевыми значениями.
Давайте получим краткую статистическую сводку по набору данных с помощью метода describe(). Функция describe() применяет к набору данных базовые статистические вычисления, такие как вычисление крайних значений, количества точек данных, стандартного отклонения и т. д. Любое пропущенное значение или значение NaN автоматически пропускается. Функция describe() даёт хорошее представление о распределении данных.
Пример:
df.describe()
Вывод:
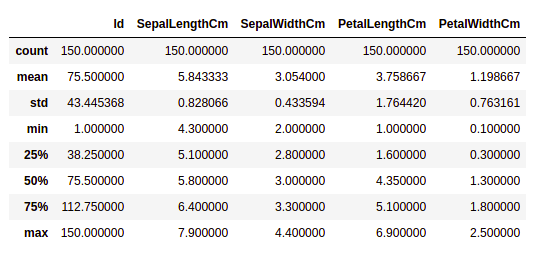
Мы можем увидеть количество значений в каждом столбце, а также их среднее значение, стандартное отклонение, минимальное и максимальное значения.
Проверка пропущенных значений
Мы проверим, есть ли в наших данных пропущенные значения. Пропущенные значения могут возникать, когда для одного или нескольких элементов или для целого блока не указана информация. Мы будем использовать метод isnull().
Пример:
df.isnull().sum()
Вывод:
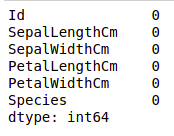
Мы видим, что ни в одном столбце нет пропущенного значения.
Проверка дубликатов
Давайте посмотрим, есть ли в нашем наборе данных дубликаты. Метод Pandas drop_duplicates() помогает удалить дубликаты из фрейма данных.
Пример:
data = df.drop_duplicates(subset ="Species",)
data
Вывод:
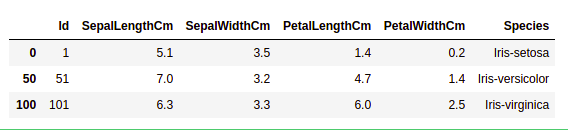
Мы видим, что существует только три уникальных вида. Давайте посмотрим, сбалансирован ли набор данных, то есть все ли виды содержат одинаковое количество строк. Мы будем использовать функцию Series.value_counts(). Эта функция возвращает серию, содержащую количество уникальных значений.
Пример:
df.value_counts("Species")
Вывод:
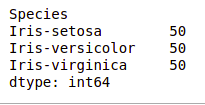
Мы видим, что все виды содержат одинаковое количество строк, поэтому нам не нужно удалять какие-либо записи.
Визуализация данных
Визуализация целевого столбца
Нашим целевым столбцом будет столбец «Вид», потому что в итоге нам понадобится результат только по видам. Давайте посмотрим на диаграмму распределения по видам.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='Species', data=df, )
plt.show()
Вывод:
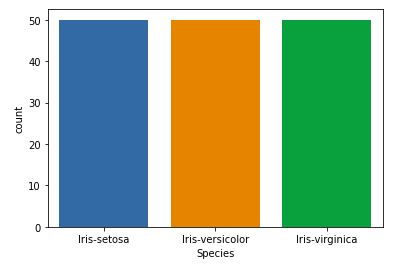
Связь между переменными
Мы рассмотрим соотношение между длиной и шириной чашелистика, а также между длиной и шириной лепестка.
Пример 1: Сравнение длины и ширины чашелистика
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(x='SepalLengthCm', y='SepalWidthCm',
hue='Species', data=df, )
# Placing Legend outside the Figure
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
Вывод:
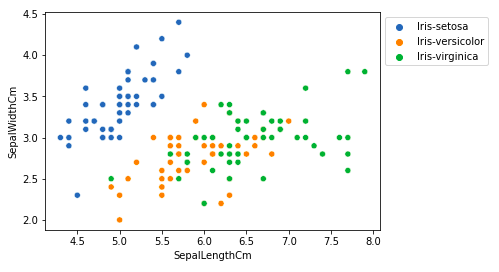
Из приведенного выше графика мы можем сделать вывод, что –
- У вида Setosa длина чашелистиков меньше, но ширина чашелистиков больше.
- Versicolor Species занимает промежуточное положение между двумя другими видами по длине и ширине чашелистика
- У вида Virginica длина чашелистиков больше, но ширина чашелистиков меньше.
Пример 2: Сравнение длины и ширины лепестков
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(x='PetalLengthCm', y='PetalWidthCm',
hue='Species', data=df, )
# Placing Legend outside the Figure
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
Выход:
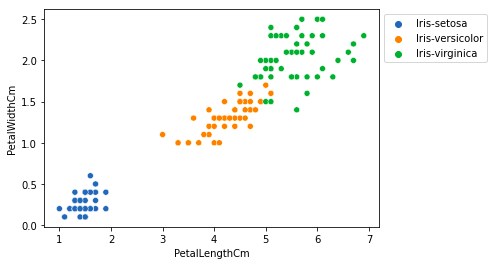
Из приведенного выше графика мы можем сделать вывод, что –
- Вид Setosa имеет меньшую длину и ширину лепестков.
- Вид Versicolor занимает промежуточное положение между двумя другими видами по длине и ширине лепестков.
- Вид Virginica имеет самые большие длину и ширину лепестков.
Давайте построим график всех взаимосвязей столбцов с помощью парного графика. Его можно использовать для многомерного анализа.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df.drop(['Id'], axis = 1),
hue='Species', height=2)
Вывод:
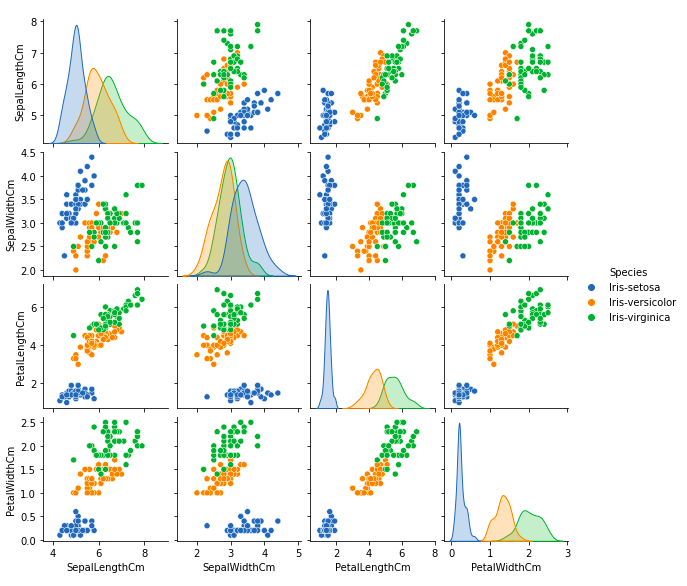
На этом графике мы можем увидеть множество взаимосвязей, например, что у вида Setosa наименьшая ширина и длина лепестков.У него также самая маленькая длина чашечки, но более широкая чашечка.Такую информацию можно собрать в любом другом виде.
Гистограммы
Гистограммы позволяют просматривать данные при различных состояниях.Их можно использовать как для одномерного, так и для двумерного анализа.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(10,10))
axes[0,0].set_title("Sepal Length")
axes[0,0].hist(df['SepalLengthCm'], bins=7)
axes[0,1].set_title("Sepal Width")
axes[0,1].hist(df['SepalWidthCm'], bins=5);
axes[1,0].set_title("Petal Length")
axes[1,0].hist(df['PetalLengthCm'], bins=6);
axes[1,1].set_title("Petal Width")
axes[1,1].hist(df['PetalWidthCm'], bins=6);
Вывод:
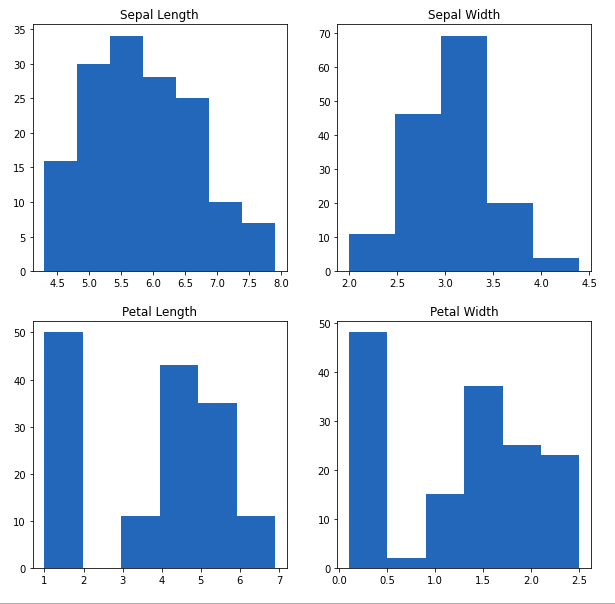
Из приведенного выше графика мы можем видеть, что –
- Максимальная длина чашелистиков составляет от 30 до 35 мм, то есть от 5,5 до 6.
- Максимальная ширина чашелистиков составляет около 70 мм, то есть от 3,0 до 3,5.
- Максимальная длина лепестков составляет около 50, то есть от 1 до 2.
- Максимальная ширина лепестков составляет от 40 до 50, то есть от 0,0 до 0,5.
Гистограммы с диаграммой Distplot
Гистограмма обычно используется для одномерного набора наблюдений и визуализирует его с помощью гистограммы, то есть есть только одно наблюдение, поэтому мы выбираем один конкретный столбец набора данных.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "SepalLengthCm").add_legend()
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "SepalWidthCm").add_legend()
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "PetalLengthCm").add_legend()
plot = sns.FacetGrid(df, hue="Species")
plot.map(sns.distplot, "PetalWidthCm").add_legend()
plt.show()
Вывод:
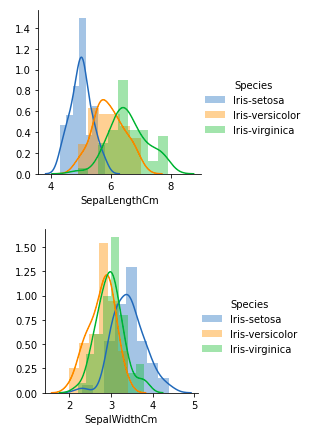
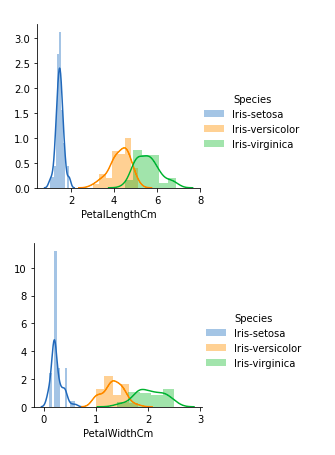
Из приведенных выше графиков мы можем видеть, что –
- В случае с третьей чашелистикой наблюдается сильное перекрытие.
- В случае с отклонением чашелистики также наблюдается сильное перекрытие.
- В случае четвертого лепестков открытие очень незначительное.
- В случае с отклонением лепестков также наблюдается очень незначительное перекрытие.
Таким образом, мы можем использовать длину и сдвиг лепестков в качестве критериев классификации.
Обработка аналогий
Панды dataframe.корр() используется для поиска попарной корреляции всех столбцов в рамках данных.Любые значения NA автоматически проверяются.Для столбцов нечислового типа в рамке данных это игнорируется.
Пример:
data.select_dtypes(include=['number']).corr(method='pearson')
# This code is modified by Susobhan Akhuli
Вывод:
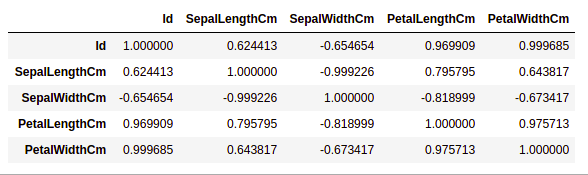
Тёплые карты
Тепловая карта — это метод визуализации данных, который используется для анализа набора данных в виде цветов в двух измерениях.По сути, она показывает корреляцию между всеми числовыми переменными в наборе данных.Проще говоря, мы можем построить график определённой более высокой зависимости с помощью тепловых карт.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(df.select_dtypes(include=['number']).corr(method='pearson').drop(
['Id'], axis=1).drop(['Id'], axis=0),
annot = True);
plt.show()
# This code is modified by Susobhan Akhuli
Выход:
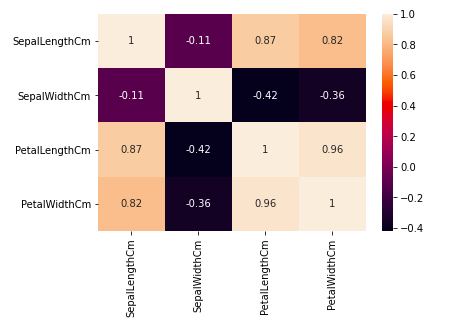
Из приведенного выше графика мы видим, что –
- Ширина и длина лепестка имеют высокую корреляцию.
- Длина лепестка и ширина чашелистика имеют хорошую корреляцию.
- Ширина лепестка и длина чашелистика имеют хорошую корреляцию.
Диаграммы ящиков
Мы можем использовать диаграммы размаха, чтобы увидеть, как категориальное значение соотносится с другими числовыми значениями.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
def graph(y):
sns.boxplot(x="Species", y=y, data=df)
plt.figure(figsize=(10,10))
# Adding the subplot at the specified
# grid position
plt.subplot(221)
graph('SepalLengthCm')
plt.subplot(222)
graph('SepalWidthCm')
plt.subplot(223)
graph('PetalLengthCm')
plt.subplot(224)
graph('PetalWidthCm')
plt.show()
Вывод:
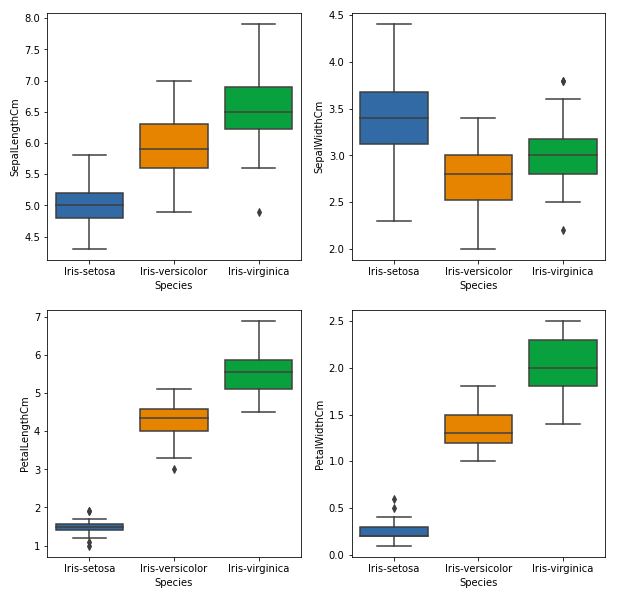
Из приведенного выше графика мы можем видеть, что –
- Вид Сетоза имеет наименьшие признаки и менее распространен, с некоторыми выбросами.
- Вид Versicolor имеет средние характеристики.
- Вид Virginica обладает самыми высокими характеристиками
Обработка выбросов
Выброс — это элемент данных/объект, который значительно отличается от остальных (так называемых нормальных) объектов. Они могут быть вызваны ошибками измерения или выполнения. Анализ для выявления выбросов называется поиском выбросов. Существует множество способов выявления выбросов, а процесс их удаления аналогичен удалению элемента данных из фрейма данных pandas.
Давайте рассмотрим набор данных «Ирис» и построим диаграмму размаха для столбца SepalWidthCm.
Пример:
# importing packages
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
df = pd.read_csv('Iris.csv')
sns.boxplot(x='SepalWidthCm', data=df)
Вывод:
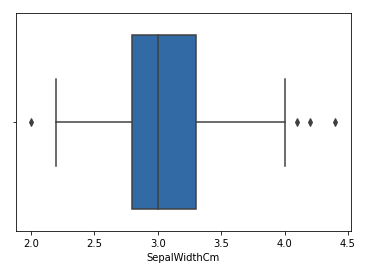
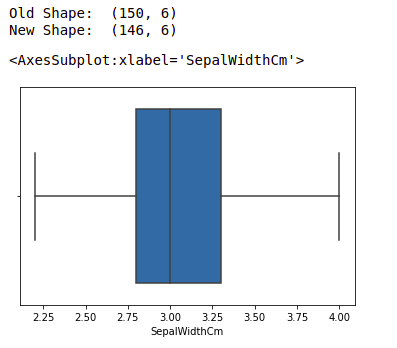
На приведённом выше графике значения выше 4 и ниже 2 являются выбросами.
Удаление выбросов
Чтобы удалить выбросы, нужно выполнить те же действия, что и при удалении записи из набора данных, используя её точное положение в наборе данных, поскольку во всех вышеперечисленных методах обнаружения выбросов конечным результатом является список всех элементов данных, которые соответствуют определению выбросов в соответствии с используемым методом.
Пример: мы обнаружим выбросы с помощью IQR, а затем удалим их. Мы также построим диаграмму размаха, чтобы проверить, удалены ли выбросы.
# Importing
import numpy as np
# Load the dataset
df = pd.read_csv('Iris.csv')
# IQR
Q1 = np.percentile(df['SepalWidthCm'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df['SepalWidthCm'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
print("Old Shape: ", df.shape)
# Upper bound
upper = np.where(df['SepalWidthCm'] >= (Q3+1.5*IQR))
# Lower bound
lower = np.where(df['SepalWidthCm'] <= (Q1-1.5*IQR))
# Removing the Outliers
df.drop(upper[0], inplace = True)
df.drop(lower[0], inplace = True)
print("New Shape: ", df.shape)
sns.boxplot(x='SepalWidthCm', data=df)
# This code is modified by Susobhan Akhuli
Вывод:
- Информация о материале
- Категория: Data Sciense
- Просмотров: 10
В предыдущей статье мы рассмотрели некоторые базовые методы анализа данных, а теперь давайте рассмотрим визуальные методы.
Давайте рассмотрим основные методы
# Loading Libraries
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import trim_mean
# Loading Data
data = pd.read_csv("state.csv")
# Check the type of data
print ("Type : ", type(data), "\n\n")
# Printing Top 10 Records
print ("Head -- \n", data.head(10))
# Printing last 10 Records
print ("\n\n Tail -- \n", data.tail(10))
# Adding a new column with derived data
data['PopulationInMillions'] = data['Population']/1000000
# Changed data
print (data.head(5))
# Rename column heading as it
# has '.' in it which will create
# problems when dealing functions
data.rename(columns ={'Murder.Rate': 'MurderRate'},
inplace = True)
# Lets check the column headings
list(data)
Вывод :
Type : class 'pandas.core.frame.DataFrame'
Head --
State Population Murder.Rate Abbreviation
0 Alabama 4779736 5.7 AL
1 Alaska 710231 5.6 AK
2 Arizona 6392017 4.7 AZ
3 Arkansas 2915918 5.6 AR
4 California 37253956 4.4 CA
5 Colorado 5029196 2.8 CO
6 Connecticut 3574097 2.4 CT
7 Delaware 897934 5.8 DE
8 Florida 18801310 5.8 FL
9 Georgia 9687653 5.7 GA
Tail --
State Population Murder.Rate Abbreviation
40 South Dakota 814180 2.3 SD
41 Tennessee 6346105 5.7 TN
42 Texas 25145561 4.4 TX
43 Utah 2763885 2.3 UT
44 Vermont 625741 1.6 VT
45 Virginia 8001024 4.1 VA
46 Washington 6724540 2.5 WA
47 West Virginia 1852994 4.0 WV
48 Wisconsin 5686986 2.9 WI
49 Wyoming 563626 2.7 WY
State Population Murder.Rate Abbreviation PopulationInMillions
0 Alabama 4779736 5.7 AL 4.779736
1 Alaska 710231 5.6 AK 0.710231
2 Arizona 6392017 4.7 AZ 6.392017
3 Arkansas 2915918 5.6 AR 2.915918
4 California 37253956 4.4 CA 37.253956
['State', 'Population', 'MurderRate', 'Abbreviation']
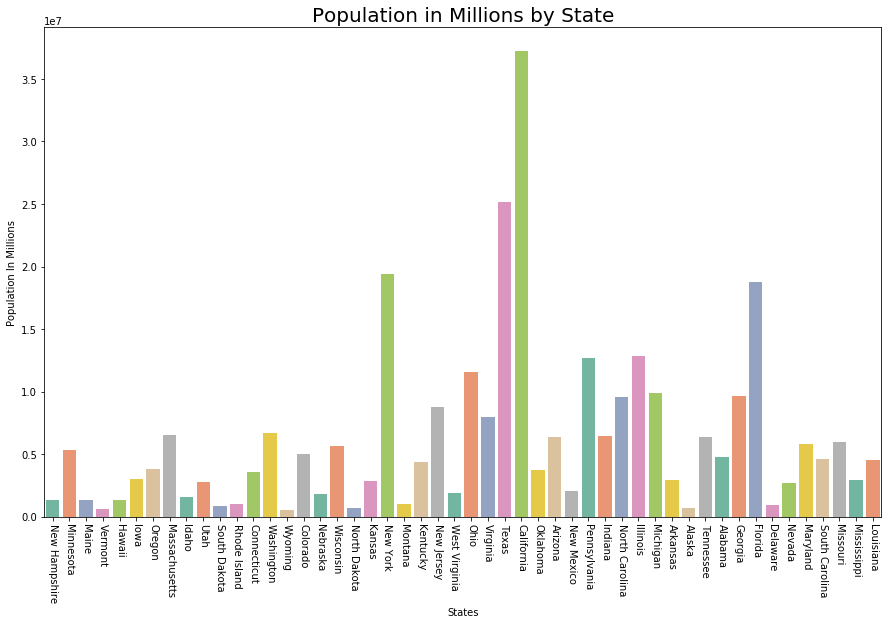
Визуализация численности населения на миллион
# Plot Population In Millions
fig, ax1 = plt.subplots()
fig.set_size_inches(15, 9)
ax1 = sns.barplot(x ="State", y ="Population",
data = data.sort_values('MurderRate'),
palette ="Set2")
ax1.set(xlabel ='States', ylabel ='Population In Millions')
ax1.set_title('Population in Millions by State', size = 20)
plt.xticks(rotation =-90)
Вывод:
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49]),
a list of 50 Text xticklabel objects)
Визуализация количества убийств на человека
# Plot Murder Rate per 1, 00, 000
fig, ax2 = plt.subplots()
fig.set_size_inches(15, 9)
ax2 = sns.barplot(
x ="State", y ="MurderRate",
data = data.sort_values('MurderRate', ascending = 1),
palette ="husl")
ax2.set(xlabel ='States', ylabel ='Murder Rate per 100000')
ax2.set_title('Murder Rate by State', size = 20)
plt.xticks(rotation =-90)
Вывод :
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49]),
a list of 50 Text xticklabel objects)
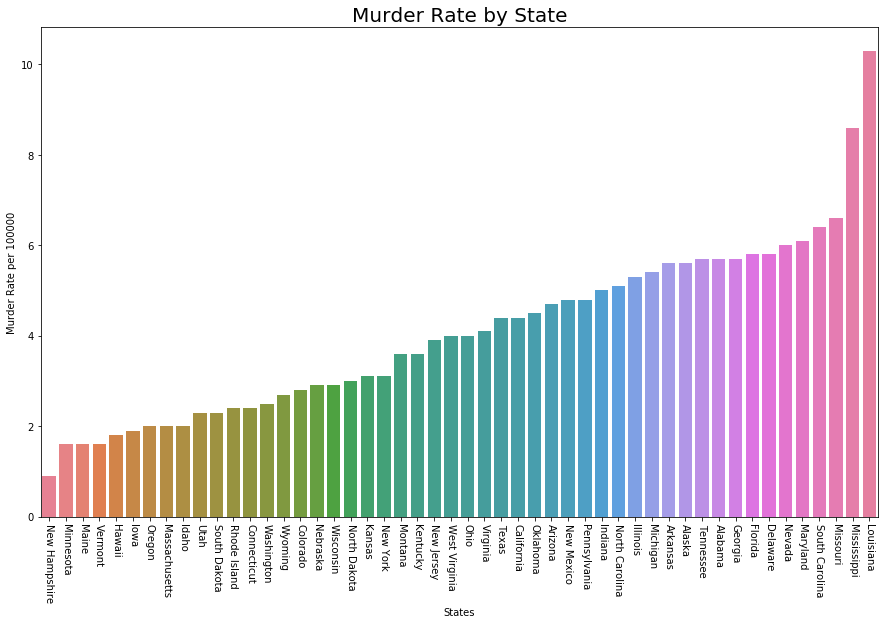
Хотя Луизиана занимает 17-е место по численности населения (около 4,53 млн человек), в ней самый высокий уровень убийств — 10,3 на 1 млн человек.
Код № 1 : стандартное отклонение
Population_std = data.Population.std()
print ("Population std : ", Population_std)
MurderRate_std = data.MurderRate.std()
print ("\nMurderRate std : ", MurderRate_std)
Вывод :
Population std : 6848235.347401142 MurderRate std : 1.915736124302923
Код № 2 : Дисперсия
Population_var = data.Population.var()
print ("Population var : ", Population_var)
MurderRate_var = data.MurderRate.var()
print ("\nMurderRate var : ", MurderRate_var)
Вывод :
Population var : 46898327373394.445 MurderRate var : 3.670044897959184
Код №3 : Межквартильный диапазон
# Inter Quartile Range of Population
population_IQR = data.Population.describe()['75 %'] -
data.Population.describe()['25 %']
print ("Population IQR : ", population_IRQ)
# Inter Quartile Range of Murder Rate
MurderRate_IQR = data.MurderRate.describe()['75 %'] -
data.MurderRate.describe()['25 %']
print ("\nMurderRate IQR : ", MurderRate_IQR)
Вывод :
Population IQR : 4847308.0 MurderRate IQR : 3.124999999999999
Код №4 : Среднее абсолютное отклонение (MAD)
Population_mad = data.Population.mad()
print ("Population mad : ", Population_mad)
MurderRate_mad = data.MurderRate.mad()
print ("\nMurderRate mad : ", MurderRate_mad)
Вывод :
Population mad : 4450933.356000001 MurderRate mad : 1.5526400000000005
- Информация о материале
- Категория: Data Sciense
- Просмотров: 9
Исследовательский анализ данных — это метод анализа данных с помощью визуальных методов и всех статистических результатов. Мы узнаем, как применять эти методы, прежде чем использовать какие-либо модели машинного обучения.
Загрузка библиотек:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import trim_mean
Загрузка данных:
data = pd.read_csv("state.csv")
# Check the type of data
print ("Type : ", type(data), "\n\n")
# Printing Top 10 Records
print ("Head -- \n", data.head(10))
# Printing last 10 Records
print ("\n\n Tail -- \n", data.tail(10))
Вывод :
Type : class 'pandas.core.frame.DataFrame'
Head --
State Population Murder.Rate Abbreviation
0 Alabama 4779736 5.7 AL
1 Alaska 710231 5.6 AK
2 Arizona 6392017 4.7 AZ
3 Arkansas 2915918 5.6 AR
4 California 37253956 4.4 CA
5 Colorado 5029196 2.8 CO
6 Connecticut 3574097 2.4 CT
7 Delaware 897934 5.8 DE
8 Florida 18801310 5.8 FL
9 Georgia 9687653 5.7 GA
Tail --
State Population Murder.Rate Abbreviation
40 South Dakota 814180 2.3 SD
41 Tennessee 6346105 5.7 TN
42 Texas 25145561 4.4 TX
43 Utah 2763885 2.3 UT
44 Vermont 625741 1.6 VT
45 Virginia 8001024 4.1 VA
46 Washington 6724540 2.5 WA
47 West Virginia 1852994 4.0 WV
48 Wisconsin 5686986 2.9 WI
49 Wyoming 563626 2.7 WY
Код № 1 : Добавление столбца во фрейм данных
# Adding a new column with derived data
data['PopulationInMillions'] = data['Population']/1000000
# Changed data
print (data.head(5))
Вывод :
State Population Murder.Rate Abbreviation PopulationInMillions 0 Alabama 4779736 5.7 AL 4.779736 1 Alaska 710231 5.6 AK 0.710231 2 Arizona 6392017 4.7 AZ 6.392017 3 Arkansas 2915918 5.6 AR 2.915918 4 California 37253956 4.4 CA 37.253956
Код №2 : Описание данных
data.describe()
Вывод :
Код #3 : Информация о данных
data.info()
Вывод :
RangeIndex: 50 entries, 0 to 49 Data columns (total 4 columns): State 50 non-null object Population 50 non-null int64 Murder.Rate 50 non-null float64 Abbreviation 50 non-null object dtypes: float64(1), int64(1), object(2) memory usage: 1.6+ KB
Код №4 : переименование заголовка столбца
# Rename column heading as it
# has '.' in it which will create
# problems when dealing functions
data.rename(columns ={'Murder.Rate': 'MurderRate'}, inplace = True)
# Lets check the column headings
list(data)
Вывод :
['State', 'Population', 'MurderRate', 'Abbreviation']
Код №5 : Вычисление среднего
Population_mean = data.Population.mean()
print ("Population Mean : ", Population_mean)
MurderRate_mean = data.MurderRate.mean()
print ("\nMurderRate Mean : ", MurderRate_mean)
Вывод:
Population Mean : 6162876.3 MurderRate Mean : 4.066
Код № 6 : Урезанное среднее значение
# Mean after discarding top and
# bottom 10 % values eliminating outliers
population_TM = trim_mean(data.Population, 0.1)
print ("Population trimmed mean: ", population_TM)
murder_TM = trim_mean(data.MurderRate, 0.1)
print ("\nMurderRate trimmed mean: ", murder_TM)
Вывод :
Population trimmed mean: 4783697.125 MurderRate trimmed mean: 3.9450000000000003
Код #7 : средневзвешенное значение
# here murder rate is weighed as per
# the state population
murderRate_WM = np.average(data.MurderRate, weights = data.Population)
print ("Weighted MurderRate Mean: ", murderRate_WM)
Вывод :
Weighted MurderRate Mean: 4.445833981123393
Код #8 : Медиана
Population_median = data.Population.median()
print ("Population median : ", Population_median)
MurderRate_median = data.MurderRate.median()
print ("\nMurderRate median : ", MurderRate_median)
Вывод :
Population median : 4436369.5 MurderRate median : 4.0
- Информация о материале
- Категория: Data Sciense
- Просмотров: 7