В этой статье мы рассмотрим, как можно собрать отзывы клиентов Amazon с помощью Beautiful Soup в Python.
Требуется модуль
- bs4 Beautiful Soup (bs4) — это библиотека Python для извлечения данных из HTML и XML файлов. Этот модуль не входит в стандартную комплектацию Python. Чтобы установить его, введите в терминале следующую команду.
pip install bs4
- requests Модуль requests позволяет очень легко отправлять HTTP-запросы версии 1.1. Этот модуль также не входит в стандартную комплектацию Python. Чтобы установить его, введите в терминале следующую команду.
pip install requests
Чтобы начать парсинг веб-страниц, нам сначала нужно выполнить некоторые настройки. Импортируйте все необходимые модули. Получите данные файлов cookie для отправки запроса на Amazon, без этого вы не сможете выполнять парсинг. Создайте заголовок, содержащий файлы cookie вашего запроса, без файлов cookie вы не сможете парсить данные Amazon, так как всегда будет появляться ошибка. Этот веб-сайт предоставит вам специальный пользовательский агент.
Передайте URL-адрес в функцию getdata() (определённую пользователем функцию), которая отправит запрос на URL-адрес и вернёт ответ. Мы используем метод get для получения информации с заданного сервера по заданному URL-адресу.
Синтаксис:
requests.get(url, args)
Синтаксис:
soup = BeautifulSoup(r.content, ‘html5lib’)
Параметры:
- r.content : Это необработанный HTML-контент.
- html.parser: указание HTML-парсера, который мы хотим использовать.
Теперь отфильтруйте нужные данные с помощью soup.Find_all.
Программа:
# import module
import requests
from bs4 import BeautifulSoup
HEADERS = ({'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/90.0.4430.212 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
# user define function
# Scrape the data
def getdata(url):
r = requests.get(url, headers=HEADERS)
return r.text
def html_code(url):
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# display html code
return (soup)
url = "https://www.amazon.in/Columbia-Mens-wind-\
resistant-Glove/dp/B0772WVHPS/?_encoding=UTF8&pd_rd\
_w=d9RS9&pf_rd_p=3d2ae0df-d986-4d1d-8c95-aa25d2ade606&pf\
_rd_r=7MP3ZDYBBV88PYJ7KEMJ&pd_rd_r=550bec4d-5268-41d5-\
87cb-8af40554a01e&pd_rd_wg=oy8v8&ref_=pd_gw_cr_cartx&th=1"
soup = html_code(url)
print(soup)
Результат:

Примечание: Это всего лишь HTML-код или необработанные данные.
Теперь, когда основная настройка завершена, давайте посмотрим, как можно выполнить парсинг для конкретного запроса.
Очистите имя клиента
Теперь найдите список клиентов с тегом span, где class_ = a-profile-name. Вы можете открыть веб-страницу в браузере и проверить соответствующий элемент, нажав правой кнопкой мыши, как показано на рисунке.
Вы должны передать имя тега и атрибут с соответствующим значением в функцию find_all().

Код:
def cus_data(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
cus_list = []
for item in soup.find_all("span", class_="a-profile-name"):
data_str = data_str + item.get_text()
cus_list.append(data_str)
data_str = ""
return cus_list
cus_res = cus_data(soup)
print(cus_res)
Результат:
[‘Amaze’, ‘Robert’, ‘D. Kong’, ‘Alexey’, ‘Charl’, ‘RBostillo’]
Отзыв пользователя Scrape:
Теперь найдите отзыв клиента, используя те же методы, что и выше. Найдите уникальное имя класса с определённым тегом, здесь мы используем тег div.
Код:
def cus_rev(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("div", class_="a-expander-content \
reviewText review-text-content a-expander-partial-collapse-content"):
data_str = data_str + item.get_text()
result = data_str.split("\n")
return (result)
rev_data = cus_rev(soup)
rev_result = []
for i in rev_data:
if i is "":
pass
else:
rev_result.append(i)
rev_result
Результат:

Информация о производстве очистки
Здесь мы будем собирать информацию о товаре, такую как название, номер ASIN, вес и размеры. Для этого мы будем использовать тег span с уникальным именем класса.
Код:
def product_info(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
pro_info = []
for item in soup.find_all("ul", class_="a-unordered-list a-nostyle\
a-vertical a-spacing-none detail-bullet-list"):
data_str = data_str + item.get_text()
pro_info.append(data_str.split("\n"))
data_str = ""
return pro_info
pro_result = product_info(soup)
# Filter the required data
for item in pro_result:
for j in item:
if j is "":
pass
else:
print(j)
Результат:

Изображение с обзором скрапинга:
Здесь мы извлечём ссылку на изображение из отзыва о товаре с помощью тех же методов, что и выше. Имя тега и атрибут тега передаются в findAll(), как и выше.
Код:
def rev_img(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
cus_list = []
images = []
for img in soup.findAll('img', class_="cr-lightbox-image-thumbnail"):
images.append(img.get('src'))
return images
img_result = rev_img(soup)
img_result
Результат:

Сохранение сведений в CSV-файл:
Здесь мы сохраним данные в CSV-файл. Мы преобразуем данные в фрейм данных, а затем экспортируем их в CSV-файл. Давайте посмотрим, как экспортировать фрейм данных Pandas в CSV-файл. Мы будем использовать функцию to_csv() для сохранения фрейма данных в виде CSV-файла.
Синтаксис : to_csv(параметры)
Параметры :
- path_or_buf : Путь к файлу или объект, если не указан, результат возвращается в виде строки.
Код:
import pandas as pd
# initialise data of lists.
data = {'Name': cus_res,
'review': rev_result}
# Create DataFrame
df = pd.DataFrame(data)
# Save the output.
df.to_csv('amazon_review.csv')
Результат:

- Информация о материале
- Категория: Data Sciense
- Просмотров: 9
Web - парсинг — это метод извлечения данных, используемый исключительно для сбора данных с веб-сайтов. Он широко применяется для интеллектуального анализа данных или сбора ценной информации с крупных веб-сайтов. Веб-парсинг также полезен для личного использования. В Python есть замечательная библиотека под названием BeautifulSoup , которая позволяет выполнять веб-парсинг. Мы будем использовать её для сбора информации о товарах и сохранения данных в файл CSV.
В этой статье необходимы следующие предварительные условия.
url.txt: текстовый файл с несколькими URL-адресами страниц товаров Amazon для парсинга
Идентификатор элемента: нам нужны идентификаторы объектов, которые мы хотим извлечь из Интернета. Скоро мы это обсудим…
Вот как выглядит наш текстовый файл.

Необходимый модуль и установка:
BeautifulSoup: наш основной модуль содержит метод для доступа к веб-странице по протоколу HTTP.
pip install bs4
lxml: вспомогательная библиотека для обработки веб-страниц на языке Python.
pip install lxml
requests: делают процесс отправки HTTP-запросов безупречным. вывод функции
pip install requests
Подход:
- Сначала мы собираемся импортировать необходимые нам библиотеки.
- Затем мы возьмем URL, хранящийся в нашем текстовом файле.
- Мы передадим URL-адрес нашему объекту-супу, который затем извлечёт нужную информацию из указанного URL-адреса
на основе предоставленного нами идентификатора элемента и сохранит её в нашем CSV-файле.
Давайте посмотрим на код и увидим, что происходит на каждом важном этапе.
Шаг 1: Инициализация нашей программы.
Мы импортируем beautifulsoup и запросы, создаем/открываем CSV-файл для сохранения собранных данных. Мы объявили заголовок и добавили пользовательский агент. Это гарантирует, что целевой сайт, с которого мы будем собирать данные, не будет считать трафик нашей программы спамом и не заблокирует его.
from bs4 import BeautifulSoup
import requests
File = open("out.csv", "a")
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
webpage = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(webpage.content, "lxml")
Шаг 2: Получение идентификаторов элементов.
Мы определяем элементы, просматривая отображаемые веб-страницы, чего нельзя сказать о нашем скрипте. Чтобы определить целевой элемент, мы получим его идентификатор и передадим его скрипту.
Получить идентификатор элемента довольно просто. Предположим, мне нужен идентификатор элемента с названием продукта. Всё, что мне нужно сделать, — это
- Перейдите по URL-адресу и просмотрите текст
- В консоли мы берем текст рядом с id =

Мы передаём его в функцию soup.find и преобразуем вывод функции в строку. Мы удаляем запятые из строки, чтобы они не мешали формату записи CSV.
try:
title = soup.find("span",
attrs={"id": 'productTitle'})
title_value = title.string
title_string = title_value
.strip().replace(',', '')
except AttributeError:
title_string = "NA"
print("product Title = ", title_string)
Шаг 3: Сохранение текущей информации в текстовый файл
Мы используем наш объект файла и записываем только что полученную строку, завершая её запятой «,», чтобы разделить столбцы при интерпретации в формате CSV.
File.write(f"{title_string},")
Выполните описанные выше 2 шага для всех атрибутов, которые вы хотите получить из Интернета,
например, цена товара, наличие и т. д.
Шаг 4: Закрытие файла.
File.write(f"{available},\n")
# closing the file
File.close()
При вводе последней части информации обратите внимание, что мы добавляем «\n» для перехода на новую строку. Если этого не сделать, вся необходимая информация будет записана в одну очень длинную строку. Мы закрываем файл с помощью File.close(). Это необходимо, иначе при следующем открытии файла может возникнуть ошибка.
Шаг 5: Вызов функции, которую мы только что создали.
if __name__ == '__main__':
# opening our url file to access URLs
file = open("url.txt", "r")
# iterating over the urls
for links in file.readlines():
main(links)
Мы открываем файл url.txt в режиме чтения и перебираем каждую его строку, пока не дойдём до последней. Вызываем основную функцию для каждой строки.
Вот как выглядит весь наш код:
# importing libraries
from bs4 import BeautifulSoup
import requests
def main(URL):
# opening our output file in append mode
File = open("out.csv", "a")
# specifying user agent, You can use other user agents
# available on the internet
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
# Making the HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Creating the Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# retrieving product title
try:
# Outer Tag Object
title = soup.find("span",
attrs={"id": 'productTitle'})
# Inner NavigableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip().replace(',', '')
except AttributeError:
title_string = "NA"
print("product Title = ", title_string)
# saving the title in the file
File.write(f"{title_string},")
# retrieving price
try:
price = soup.find(
"span", attrs={'id': 'priceblock_ourprice'})
.string.strip().replace(',', '')
# we are omitting unnecessary spaces
# and commas form our string
except AttributeError:
price = "NA"
print("Products price = ", price)
# saving
File.write(f"{price},")
# retrieving product rating
try:
rating = soup.find("i", attrs={
'class': 'a-icon a-icon-star a-star-4-5'})
.string.strip().replace(',', '')
except AttributeError:
try:
rating = soup.find(
"span", attrs={'class': 'a-icon-alt'})
.string.strip().replace(',', '')
except:
rating = "NA"
print("Overall rating = ", rating)
File.write(f"{rating},")
try:
review_count = soup.find(
"span", attrs={'id': 'acrCustomerReviewText'})
.string.strip().replace(',', '')
except AttributeError:
review_count = "NA"
print("Total reviews = ", review_count)
File.write(f"{review_count},")
# print availablility status
try:
available = soup.find("div", attrs={'id': 'availability'})
available = available.find("span")
.string.strip().replace(',', '')
except AttributeError:
available = "NA"
print("Availability = ", available)
# saving the availability and closing the line
File.write(f"{available},\n")
# closing the file
File.close()
if __name__ == '__main__':
# opening our url file to access URLs
file = open("url.txt", "r")
# iterating over the urls
for links in file.readlines():
main(links)
Вывод:
Название продукта = 3D-принтер Dremel DigiLab 3D40 Flex с дополнительными принадлежностями, 30 планами уроков, курс профессионального развития, гибкая монтажная пластина, автоматическое 9-точечное выравнивание, совместимость с ПК и MAC OS, Chromebook, iPad
Цена продукта = 1699,00 долларов США
Общая оценка = 4,1 из 5 звезд
Общее количество отзывов = 40 оценок
Наличие = В наличии.
Название продукта = 3D-принтер Comgrow Creality Ender 3 Pro со съемной пластиной для сборки и сертифицированным UL блоком питания 220x220x250 мм
Цена продукта = NA
Общая оценка = 4,6 из 5 звезд
Всего отзывов = 2509 оценок
Наличие = NA
Название продукта = Конструктор идей для 3D-принтера Dremel Digilab 3D20 для начинающих любителей и мастериц
Цена продукта = $ 679,00
Общая оценка = 4,5 из 5 звезд
Всего отзывов = 584 оценки
Наличие = В наличии .
Название продукта = 3D-принтер Dremel DigiLab 3D45, отмеченный наградами, с нитью накаливания, совместимый с ПК и MAC OS, Chromebook, iPad, сетевой, со встроенной HD-камерой, нагревательной платформой, нейлоновой, ECO, ABS, PETG, PLA, возможностью печати
Цена продукта = 1710,81 $
Общая оценка = 4,5 из 5 звезд
Общее количество отзывов = 351 оценка
Наличие = В наличии.
Вот как выглядит наш файл out.csv.

- Информация о материале
- Категория: Data Sciense
- Просмотров: 9
В этой статье вы познакомитесь с различными концепциями веб-парсинга и научитесь извлекать данные с различных типов веб-сайтов. Цель состоит в том, чтобы извлечь данные с главной страницы Википедии и проанализировать их с помощью различных методов веб-парсинга. Вы познакомитесь с различными методами веб-парсинга, модулями Python для веб-парсинга, а также с процессами извлечения и обработки данных. Веб-парсинг — это автоматический процесс извлечения информации из Интернета. В этой статье вы подробно узнаете о веб-парсинге, его сравнении с веб-сканированием и о том, почему вам стоит выбрать веб-парсинг.
Введение в веб-парсинг и Python
По сути, это метод или процесс, при котором большие объёмы данных с огромного количества веб-сайтов пропускаются через программное обеспечение для веб-парсинга, написанное на языке программирования, и в результате извлекаются структурированные данные, которые можно сохранить локально на наших устройствах, предпочтительно в таблицах Excel, JSON или электронных таблицах. Теперь нам не нужно вручную копировать и вставлять данные с веб-сайтов, поскольку парсер может выполнить эту задачу за пару секунд.
Это помогает программистам писать понятный, логичный код для небольших и масштабных проектов. Python в основном известен как лучший язык для веб-скрапинга. Он больше похож на универсальный инструмент и может легко справляться с большинством процессов, связанных с веб-сканированием. Scrapy и Beautiful Soup — одни из наиболее широко используемых фреймворков на основе Python, которые упрощают веб-скрапинг с помощью этого языка.
Краткий список библиотек Python, используемых для веб-парсинга
Давайте посмотрим библиотеки веб-парсинга на Python!
- Requests (HTTP для людей) Библиотека для веб-парсинга — используется для создания различных типов HTTP-запросов, таких как GET, POST и т. д. Это самая простая, но в то же время самая важная из всех библиотек.
- Библиотека lxml для веб-парсинга — библиотека lxml обеспечивает сверхбыстрый и высокопроизводительный синтаксический анализ HTML и XML контента с веб-сайтов. Если вы планируете собирать большие наборы данных, вам стоит выбрать именно её.
- Библиотека Beautiful Soup для веб-парсинга — она работает путём создания дерева синтаксического разбора для анализа содержимого. Это идеальная стартовая библиотека для новичков, с которой очень легко работать.
- Библиотека Selenium для веб-парсинга — изначально созданная для автоматизированного тестирования веб-приложений, эта библиотека решает проблему, с которой сталкиваются все вышеперечисленные библиотеки, а именно — извлечение контента с динамически заполняемых веб-сайтов. Это делает её более медленной и непригодной для проектов промышленного уровня.
- Scrapy для веб-парсинга — лучшая из всех библиотек, целый фреймворк для веб-парсинга, который используется асинхронно. Это делает его невероятно быстрым и повышает эффективность.
Практическая реализация – Извлечение из Википедии

Шаг 1: Как использовать python для веб-парсинга?
- Нам нужна среда разработки python IDE, и мы должны быть знакомы с ее использованием.
- Virtualenv — это инструмент для создания изолированных сред Python. С помощью virtualenv мы можем создать папку, содержащую все необходимые исполняемые файлы для использования пакетов, которые требуются нашему проекту Python. Здесь мы можем добавлять и изменять модули Python, не затрагивая глобальную установку.
- Нам нужно установить различные модули и библиотеки Python с помощью команды pip для наших целей. Но мы всегда должны помнить о том, является ли сайт, который мы парсим, легальным.
Требования:
- Requests: Это эффективная HTTP-библиотека, используемая для доступа к веб-страницам.
- Urlib3: используется для извлечения данных из URL-адресов.
- Selenium: это набор инструментов для автоматизированного тестирования веб-приложений с открытым исходным кодом для различных браузеров и платформ.
Установка:
pip install virtualenv
python -m pip install selenium
python -m pip install requests
python -m pip install urllib3

Пример изображения при установке
Шаг 2: Введение в библиотеку запросов
- Здесь мы изучим различные модули python для извлечения данных из Интернета.
- Библиотека Python Requests используется для загрузки веб-страницы, которую мы пытаемся очистить от данных.
Требования:
- Python IDE
- Модули Python
- Библиотека запросов
# import required modules
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# display status code
print(page.status_code)
# display scraped data
print(page.content)
Выход:
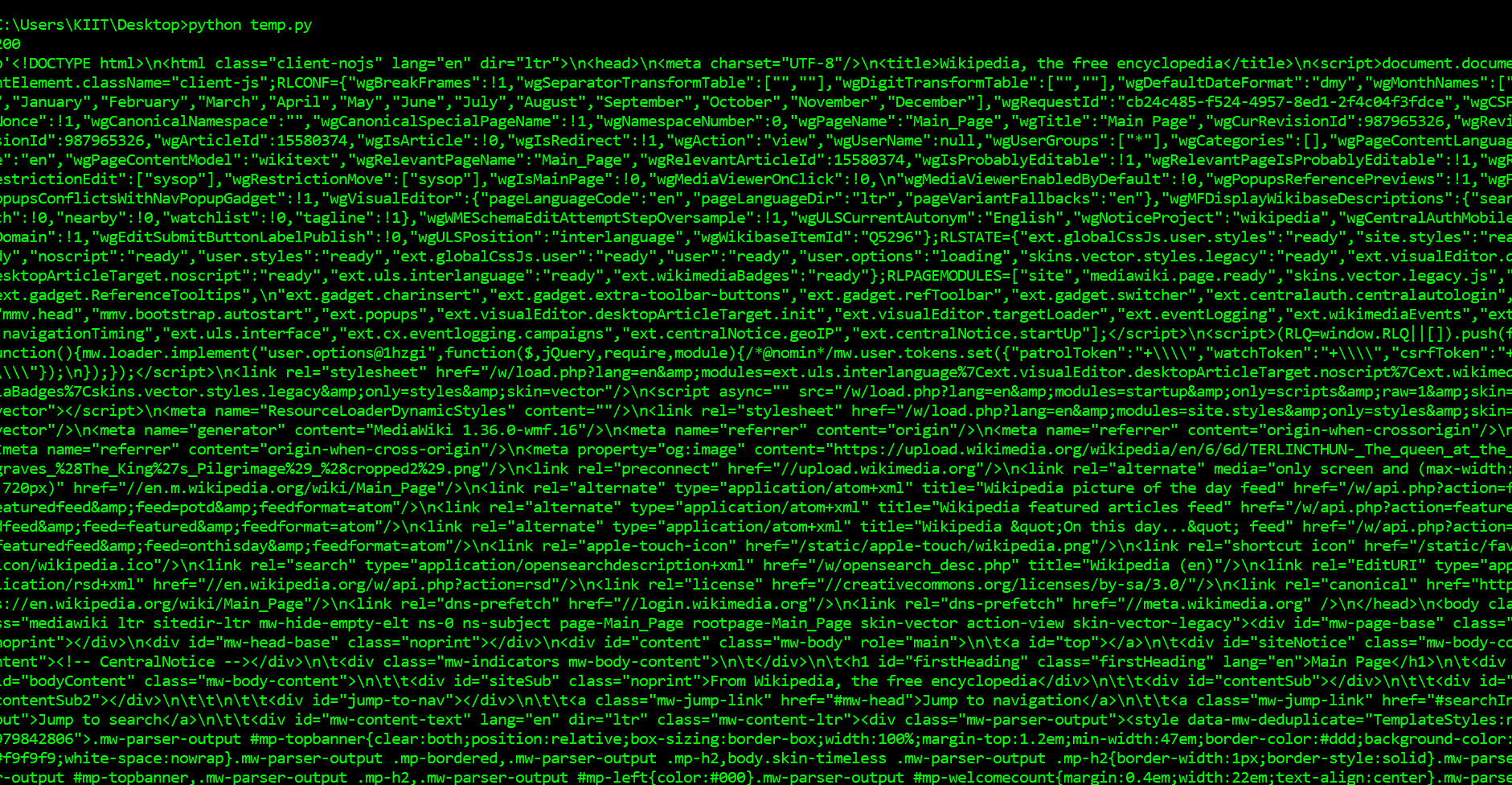
Первое, что мы должны делать, чтобы очистить веб-страницы, чтобы загрузить страницу. Мы можем загружать страницы, используя библиотеку запросов в Python. На просьбы библиотека сделает запрос GET на веб-сервер, который будет загружать содержимое HTML данной веб-страницы для нас. Существует несколько типов запросов, которые мы можем сделать, используя запросы, которые вам только одно. Адрес нашего образца сайте https://en.wikipedia.org/wiki/Main_Page. Задача в том, чтобы скачать его с помощью requests.get() метод. После выполнения нашей просьбы, мы получаем объект Response. Этот объект имеет status_code свойство, которое указывает, если страница была загружена успешно. И свойство content, которое дает HTML-содержимое веб-страницы в качестве выходных данных.
Шаг 3: Введение в Beautiful Soup для синтаксического анализа страниц
У нас есть множество модулей Python для извлечения данных. Для наших целей мы будем использовать BeautifulSoup.
- BeautifulSoup — это библиотека Python для извлечения данных из HTML и XML файлов.
- Для создания объекта-супа ему нужен ввод (документ или URL-адрес), поскольку он не может самостоятельно загрузить веб-страницу.
- У нас есть и другие модули, такие как регулярные выражения, lxml, для тех же целей.
- Затем мы обрабатываем данные в формате CSV, JSON или MySQL.
Требования:
- PythonIDE
- Модули Python
- Beautiful Soup library
pip install bs4
Пошаговое руководство по коду:
# import required modules
from bs4 import BeautifulSoup
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# scrape webpage
soup = BeautifulSoup(page.content, 'html.parser')
# display scraped data
print(soup.prettify())
Вывод:
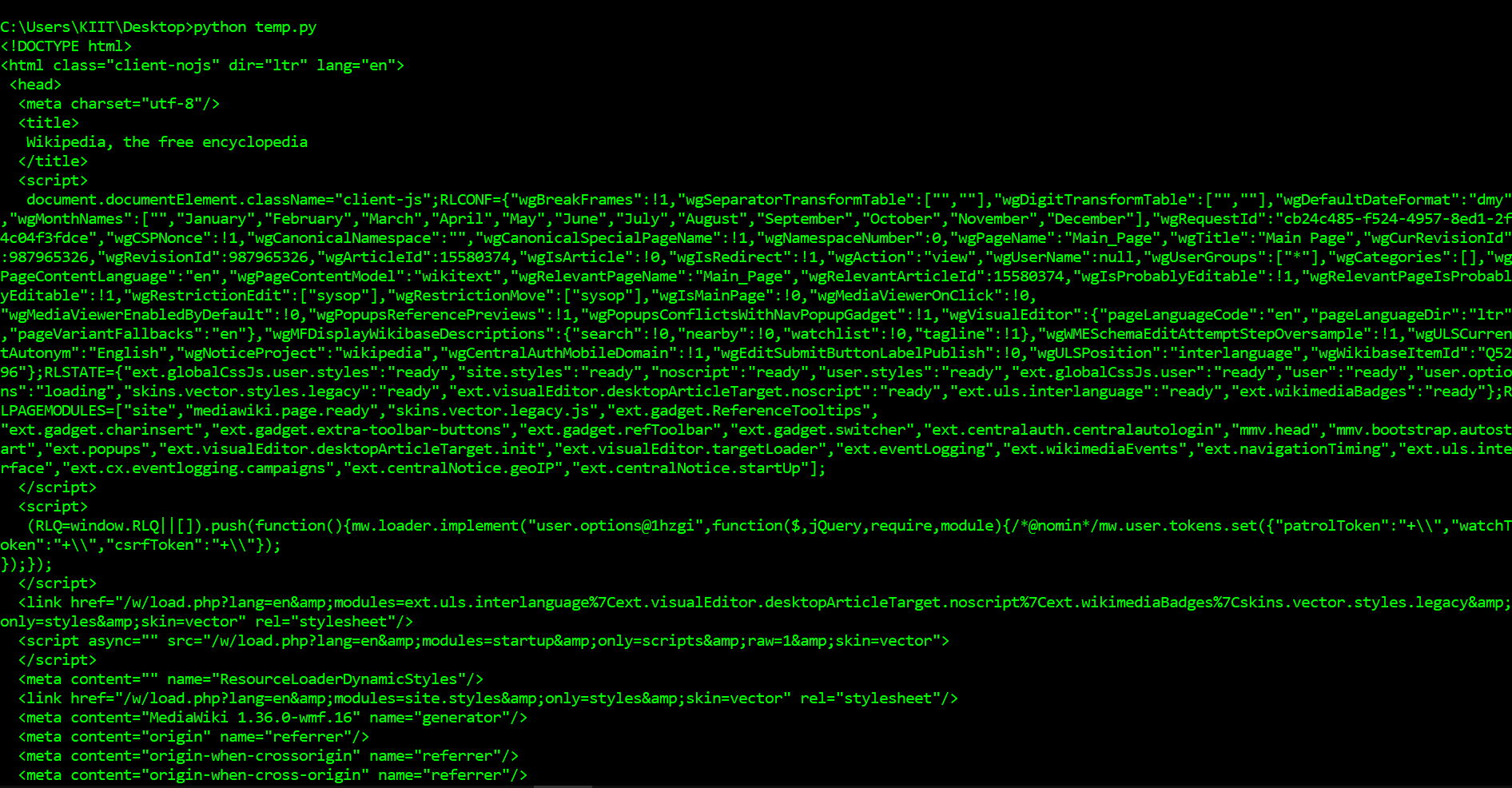
Как вы можете видеть выше, теперь мы загрузили HTML-документ. Мы можем использовать библиотеку BeautifulSoup для анализа этого документа и извлечения текста. Сначала нам нужно импортировать библиотеку и создать экземпляр класса BeautifulSoup для анализа нашего документа. Теперь мы можем вывести HTML-содержимое страницы в удобном формате с помощью метода prettify объекта BeautifulSoup. Поскольку все теги вложены друг в друга, мы можем перемещаться по структуре по одному уровню за раз. Сначала мы можем выбрать все элементы на верхнем уровне страницы с помощью свойства children в объекте soup. Обратите внимание, что свойство children возвращает генератор списка, поэтому нам нужно вызвать функцию list.
Шаг 4: Углубляемся в Beautiful Soup дальше
Три функции, которые делают Beautiful Soup таким мощным:
- Beautiful Soup предоставляет несколько простых методов Python для навигации, поиска и изменения дерева синтаксического разбора: набор инструментов для анализа документа и извлечения нужной информации. Для написания приложения не требуется много кода
- Beautiful Soup автоматически преобразует входящие документы в Unicode, а исходящие — в UTF-8. Вам не нужно беспокоиться о кодировках, если только в документе не указана кодировка и Beautiful Soup не может её определить. В этом случае вам просто нужно указать исходную кодировку.
- Beautiful Soup работает поверх популярных парсеров Python, таких как lxml и html5lib, позволяя вам опробовать различные стратегии парсинга или пожертвовать скоростью ради гибкости. Затем нам нужно просто обработать наши данные в подходящем формате, например CSV, JSON или MySQL.
Требования:
- PythonIDE
- Python Modules
- Beautiful Soup library
Пошаговое руководство по коду:
# import required modules
from bs4 import BeautifulSoup
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# scrape webpage
soup = BeautifulSoup(page.content, 'html.parser')
list(soup.children)
# find all occurrence of p in HTML
# includes HTML tags
print(soup.find_all('p'))
print('\n\n')
# return only text
# does not include HTML tags
print(soup.find_all('p')[0].get_text())
Вывод:

То, что мы сделали выше, было полезно для того, чтобы понять, как перемещаться по странице, но для выполнения довольно простой задачи потребовалось много команд. Если мы хотим извлечь один тег, мы можем использовать метод find_all(), который найдёт все экземпляры тега на странице. Обратите внимание, что find_all() возвращает список, поэтому для извлечения текста нам придётся перебирать его или использовать индексацию списка. Если вы хотите найти только первый экземпляр тега, вы можете использовать метод find, который вернёт один объект BeautifulSoup.
Шаг 5: Изучение структуры страницы с помощью инструментов разработки Chrome и извлечение информации
Первое, что нам нужно сделать, — это проверить страницу с помощью инструментов разработчика Chrome. Если вы используете другой браузер, в Firefox и Safari есть аналоги. Однако рекомендуется использовать Chrome.
Вы можете запустить инструменты разработчика в Chrome, нажав «Вид» -> «Разработчик» -> «Инструменты разработчика». В нижней части браузера появится панель, похожая на ту, что вы видите ниже. Убедитесь, что панель «Элементы» выделена. На панели «Элементы» отображаются все HTML-теги на странице, и вы можете перемещаться по ним. Это очень удобная функция! Щёлкнув правой кнопкой мыши по странице в том месте, где написано Расширенный прогноз, а затем нажав Проверить, мы откроем тег, содержащий текст Расширенный прогноз, на панели элементов.

Анализ с помощью Chrome Dev tools
Пошаговое руководство по коду:
# import required modules
from bs4 import BeautifulSoup
import requests
# get URL
page = requests.get("https://en.wikipedia.org/wiki/Main_Page")
# scrape webpage
soup = BeautifulSoup(page.content, 'html.parser')
# create object
object = soup.find(id="mp-left")
# find tags
items = object.find_all(class_="mp-h2")
result = items[0]
# display tags
print(result.prettify())
Вывод:

Здесь нам нужно выбрать элемент, у которого есть идентификатор и который содержит дочерние элементы с тем же классом. Например, элемент с идентификатором mp-left является родительским элементом, а его вложенные дочерние элементы имеют класс mp-h2. Поэтому мы выведем информацию о первом вложенном дочернем элементе и оформим её с помощью функции prettify().
Заключение и более глубокое изучение веб-парсинга
Мы изучили различные концепции веб-парсинга и собрали данные с главной страницы Википедии с помощью различных методов веб-парсинга. Статья помогла нам получить более глубокое представление о веб-парсинге, его сравнении с веб-сканированием и о том, почему стоит выбрать веб-парсинг.
Несмотря на то, что веб-парсинг открывает множество возможностей для этичных целей, неэтичные специалисты могут непреднамеренно собирать данные, что создаёт моральную угрозу для многих компаний и организаций, которые могут легко получить эти данные и использовать их в своих корыстных целях. Сбор данных в сочетании с большими данными может предоставить компании информацию о рынке и помочь выявить критические тенденции и закономерности, а также определить наилучшие возможности и решения. Поэтому вполне вероятно, что в скором времени сбор данных станет более эффективным.

- Информация о материале
- Категория: Data Sciense
- Просмотров: 9
В современном цифровом мире данные являются ключом к раскрытию ценной информации, и большая часть этих данных доступна в Интернете. Но как эффективно собирать большие объемы данных с веб-сайтов? Вот тут-то и пригодится Веб-очистка Python. Веб-очистка, процесс извлечения данных с веб-сайтов, превратился в мощный метод сбора информации на огромных просторах Интернета.
В этом руководстве мы рассмотрим различные библиотеки и модули Python, которые обычно используются для web - парсинг, и выясним, почему Python 3 является предпочтительным выбором для этой задачи. Кроме того, вы узнаете, как использовать такие мощные инструменты, как BeautifulSoup, Scrapy и Selenium для сбора данных с любого веб-сайта.
Необходимые пакеты и инструменты для очистки веб-страниц Python
Последняя версия Python предлагает широкий набор инструментов и библиотек, специально разработанных для веб-скрапинга, что делает получение данных из Интернета более простым и эффективным, чем когда-либо.
Содержание
- Requests Module
- BeautifulSoup Library
- Selenium
- Lxml
- Urllib Module
- PyautoGUI
- Schedule
- Зачем нужен Python3 для веб-очистки?
Модуль запросов
Библиотека запросов используется для отправки HTTP-запросов по определённому URL-адресу и возвращает ответ. Библиотека запросов Python предоставляет встроенные функции для управления как запросом, так и ответом.
pip install requests
Пример: Создание запроса
Модуль Python requests имеет несколько встроенных методов для отправки HTTP-запросов по указанному URI с помощью запросов GET, POST, PUT, PATCH или HEAD. HTTP-запрос предназначен для получения данных по указанному URI или отправки данных на сервер. Он работает как протокол «запрос-ответ» между клиентом и сервером. Здесь мы будем использовать запрос GET. Метод GET используется для получения информации с указанного сервера по указанному URI. Метод GET отправляет закодированную информацию о пользователе, добавленную к запросу страницы.
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# print content of request
print(r.content)
Вывод

Библиотека BeautifulSoup
Beautiful Soup предоставляет несколько простых методов для навигации, поиска и изменения дерева синтаксического разбора: набор инструментов для изучения документа и удаления того, что вам нужно. Для документирования приложения не требуется много кода.
Beautiful Soup автоматически преобразует входящие записи в Unicode, а исходящие формы - в UTF-8. Вам не нужно думать о кодировках, если только документ не определяет кодировку, а Beautiful Soup не может ее перехватить. Затем вам просто нужно выбрать исходную кодировку. Beautiful Soup находится поверх известных анализаторов Python, таких как LXML и HTML, позволяя вам попробовать различные стратегии синтаксического анализа или обменять скорость на гибкость.
pip install beautifulsoup4
Пример
- Импорт библиотек: Код импортирует библиотеку requests для выполнения HTTP-запросов и класс BeautifulSoup из библиотеки bs4 для анализа HTML.
- Отправка запроса GET: Он отправляет запрос GET на адрес ‘https://www.geeksforgeeks.org/python-programming-language/’ и сохраняет ответ в переменной r.
- Проверка кода состояния: выводит код состояния ответа, обычно 200 для успешного выполнения.
- Разбор HTML-кода: HTML-содержимое ответа анализируется с помощью BeautifulSoup и сохраняется в переменной soup.
- Печать форматированного HTML: Выводит форматированную версию проанализированного HTML-контента для удобства чтения и анализа.
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
Вывод

Поиск элементов по классам
Теперь мы хотели бы извлечь некоторые полезные данные из HTML-контента. Объект soup содержит все данные во вложенной структуре, которые можно извлечь программно. Веб-сайт, который мы хотим очистить, содержит много текста, поэтому давайте очистим весь этот контент. Сначала давайте рассмотрим веб-страницу, которую хотим очистить.

На изображении выше мы видим, что всё содержимое страницы находится под элементом div с классом entry-content. Мы будем использовать класс find. Этот класс найдёт заданный тег с заданным атрибутом. В нашем случае он найдёт все элементы div с классом entry-content.
Мы видим, что содержимое страницы находится под тегом <p>. Теперь нам нужно найти все теги p, присутствующие в этом классе. Мы можем использовать find_all класс BeautifulSoup.
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
content = s.find_all('p')
print(content)
Вывод:

Selenium
Selenium — это популярный модуль Python, используемый для автоматизации веб-браузеров. Он позволяет разработчикам управлять веб-браузерами программно, выполняя такие задачи, как web - парсинг, автоматизированное тестирование и взаимодействие с веб-приложениями. Selenium поддерживает различные веб-браузеры, включая Chrome, Firefox, Safari и Edge, что делает его универсальным инструментом для автоматизации браузеров.
Пример 1: Для Firefox
В этом конкретном примере мы перенаправляем браузер на страницу поиска Google с параметром запроса “geeksforgeeks”. Браузер загрузит эту страницу, и затем мы можем приступить к программному взаимодействию с ней с помощью Selenium. Это взаимодействие может включать такие задачи, как извлечение результатов поиска, нажатие на ссылки или удаление определенного содержимого со страницы.
# import webdriver
from selenium import webdriver
# create webdriver object
driver = webdriver.Firefox()
# get google.co.in
driver.get("https://google.co.in / search?q = geeksforgeeks")
Вывод

Пример 2: Для Chrome
- Мы импортируем модуль webdriver из библиотеки Selenium.
- Мы указываем путь к исполняемому файлу веб-драйвера. Вам нужно скачать соответствующий драйвер для вашего браузера и указать путь к нему. В этом примере мы используем драйвер Chrome.
- Мы создаём новый экземпляр веб-браузера с помощью webdriver.Chrome() и передаём путь к исполняемому файлу драйвера Chrome в качестве аргумента.
- Мы переходим на веб-страницу, вызывая метод get() объекта браузера и передавая URL-адрес веб-страницы.
- Мы извлекаем информацию с веб-страницы с помощью различных методов, предоставляемых Selenium. В этом примере мы получаем заголовок страницы с помощью атрибута title объекта браузера.
- Наконец, мы закрываем браузер, используя метод quit().
# importing necessary packages
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# for holding the resultant list
element_list = []
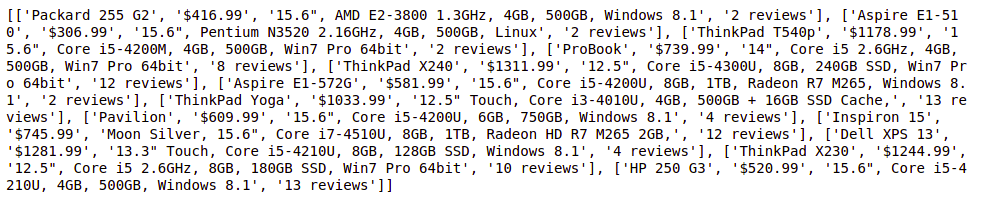
for page in range(1, 3, 1):
page_url = "https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=" + str(page)
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(page_url)
title = driver.find_elements(By.CLASS_NAME, "title")
price = driver.find_elements(By.CLASS_NAME, "price")
description = driver.find_elements(By.CLASS_NAME, "description")
rating = driver.find_elements(By.CLASS_NAME, "ratings")
for i in range(len(title)):
element_list.append([title[i].text, price[i].text, description[i].text, rating[i].text])
print(element_list)
#closing the driver
driver.close()
Вывод
Lxml
Модуль lxml в Python — это мощная библиотека для обработки XML и HTML документов. Она обеспечивает высокопроизводительный синтаксический анализ XML и HTML, а также простой и понятный API. lxml широко используется в web - парсинге на Python благодаря своей скорости, гибкости и простоте использования.
pip install lxml
Пример
Вот простой пример, демонстрирующий, как использовать модуль lxml для веб-парсинга на Python:
- Мы импортируем модуль html из lxml вместе с модулем запросов для отправки HTTP-запросов.
- Мы определяем URL веб-сайта, который хотим очистить.
- Мы отправляем HTTP-запрос GET на веб-сайт с помощью функции requests.get() и получаем HTML-содержимое страницы.
- Мы анализируем содержимое HTML с помощью функции html.fromstring() из lxml, которая возвращает дерево элементов HTML.
- Мы используем выражения XPath для извлечения определённых элементов из дерева HTML. В данном случае мы извлекаем текстовое содержимое всех элементов <a> (якорных ссылок) на странице.
- Мы перебираем извлеченные заголовки ссылок и распечатываем их.
from lxml import html
import requests
# Define the URL of the website to scrape
url = 'https://example.com'
# Send an HTTP request to the website and retrieve the HTML content
response = requests.get(url)
# Parse the HTML content using lxml
tree = html.fromstring(response.content)
# Extract specific elements from the HTML tree using XPath
# For example, let's extract the titles of all the links on the page
link_titles = tree.xpath('//a/text()')
# Print the extracted link titles
for title in link_titles:
print(title)
Вывод
More information...
Модуль Urllib
Модуль urllib в Python — это встроенная библиотека, предоставляющая функции для работы с URL-адресами. Он позволяет взаимодействовать с веб-страницами, получая URL-адреса (унифицированные указатели ресурсов), открывая и читая данные с них, а также выполняя другие задачи, связанные с URL-адресами, такие как кодирование и синтаксический анализ. Urllib — это пакет, объединяющий несколько модулей для работы с URL-адресами, таких как:
- urllib.request на открытие и чтение.
- urllib.parse для синтаксического анализа URL-адресов
- urllib.error из-за возникших исключений
- urllib.robotparser для синтаксического анализа robot.txt файлов
Если в вашей среде нет модуля urllib, выполните приведенный ниже код для его установки.
pip install urllib3
Пример
Вот простой пример, демонстрирующий, как использовать модуль urllib для получения содержимого веб-страницы:
- Мы определяем URL веб-страницы, которую хотим получить.
- Мы используем функцию urllib.request.urlopen() для открытия URL-адреса и получения объекта ответа.
- Мы считываем содержимое объекта response с помощью метода read().
- Поскольку содержимое возвращается в виде байтов, мы декодируем его в строку с помощью метода decode() с кодировкой «utf-8».
- Наконец, мы печатаем HTML-содержимое веб-страницы.
import urllib.request
# URL of the web page to fetch
url = 'https://www.example.com'
try:
# Open the URL and read its content
response = urllib.request.urlopen(url)
# Read the content of the response
data = response.read()
# Decode the data (if it's in bytes) to a string
html_content = data.decode('utf-8')
# Print the HTML content of the web page
print(html_content)
except Exception as e:
print("Error fetching URL:", e)
Вывод

PyautoGUI
Модуль pyautogui в Python — это кроссплатформенная библиотека для автоматизации графического интерфейса, которая позволяет разработчикам управлять мышью и клавиатурой для автоматизации задач. Хотя она не предназначена специально для веб-парсинга, её можно использовать в сочетании с другими библиотеками для веб-парсинга, такими как Selenium, для взаимодействия с веб-страницами, которые требуют ввода данных пользователем или имитируют действия человека.
pip3 install pyautogui
Пример
В этом примере pyautogui используется для прокрутки и создания скриншота страницы результатов поиска, полученной путём ввода запроса в поле поиска и нажатия кнопки поиска с помощью Selenium.
import pyautogui
# moves to (519,1060) in 1 sec
pyautogui.moveTo(519, 1060, duration = 1)
# simulates a click at the present
# mouse position
pyautogui.click()
# moves to (1717,352) in 1 sec
pyautogui.moveTo(1717, 352, duration = 1)
# simulates a click at the present
# mouse position
pyautogui.click()
Вывод

Расписание
Модуль schedule в Python — это простая библиотека, которая позволяет планировать выполнение функций Python через заданные промежутки времени. Она особенно полезна при парсинге веб-страниц на Python, когда вам нужно регулярно собирать данные с веб-сайта через заданные промежутки времени, например, ежечасно, ежедневно или еженедельно.
Пример
- Мы импортируем необходимые модули: schedule, time, requests и BeautifulSoup из пакета bs4.
- Мы определяем функцию scrape_data(), которая выполняет задачу веб-парсинга. Внутри этой функции мы отправляем GET-запрос на веб-сайт (замените «https://example.com» на URL-адрес веб-сайта, который вы хотите очистить), анализируем содержимое HTML с помощью BeautifulSoup, извлекаем нужные данные и выводим их на печать.
- Мы запланировали выполнение функции scrape_data() каждый час с помощью schedule.every().hour.do(scrape_data).
- Мы входим в основной цикл, который непрерывно проверяет наличие отложенных запланированных задач с помощью schedule.run_pending() и делает паузу на 1 секунду между итерациями, чтобы цикл не потреблял слишком много ресурсов процессора.
import schedule
import time
def func():
print("Geeksforgeeks")
schedule.every(1).minutes.do(func)
while True:
schedule.run_pending()
time.sleep(1)
Вывод

Зачем нужен Python3 для веб-очистки?
Популярность Python для веб-очистки обусловлена несколькими факторами:
Простота использования : понятный и читаемый синтаксис Python упрощает понимание и написание кода даже для новичков. Такая простота ускоряет процесс разработки и сокращает время обучения для задач web - парсинга.
Богатая экосистема: Python может похвастаться обширной экосистемой библиотек и фреймворков, предназначенных для веб-парсинга. Такие библиотеки, как BeautifulSoup, Scrapy и Requests, упрощают процесс разбора HTML, делая извлечение данных простым.
Универсальность: Python — это универсальный язык, который можно использовать для широкого спектра задач, помимо веб-парсинга. Его гибкость позволяет разработчикам легко интегрировать веб-парсинг в более крупные проекты, такие как анализ данных, машинное обучение или веб-разработка.
Поддержка сообщества: у Python есть большое и активное сообщество разработчиков, которые вносят свой вклад в его библиотеки и оказывают поддержку на форумах, в учебных пособиях и документации. Такое обилие ресурсов гарантирует, что разработчики имеют доступ к помощи и рекомендациям при решении задач, связанных с веб-парсингом.
Заключение
В этом руководстве вы познакомились с основами использования Python для веб-парсинга. С помощью инструментов, которые мы обсудили, вы можете быстро и легко начать собирать данные из интернета. Независимо от того, нужны ли вам эти данные для проекта, исследования или просто для развлечения, Python позволяет это сделать. Не забывайте, что всегда нужно ответственно подходить к сбору данных и соблюдать правила, установленные веб-сайтами.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 11
Предположим, вам нужна какая-то информация с веб-сайта. Допустим, абзац о Дональде Трампе! Что вы делаете? Ну, вы можете скопировать и вставить информацию из Википедии в свой файл. Но что, если вы хотите как можно быстрее получить большой объём информации с веб-сайта? Например, большой объём данных с веб-сайта для обучения алгоритма машинного обучения? В такой ситуации копирование и вставка не помогут! И тогда вам понадобится web - парсинг. В отличие от долгого и утомительного процесса получения данных вручную, web - парсинг использует интеллектуальные методы автоматизации для получения тысяч или даже миллионов наборов данных за меньшее время.
Содержание
- Что такое web - парсинг?
- Как работает web - парсинг?
- Типы web - парсинг
- Почему Python является популярным языком программирования для web - парсинга?
- Для чего используется web - парсинг?

Если вы зашли в тупик, пытаясь собрать общедоступные данные с веб-сайтов, у нас есть решение для вас. Smartproxy — это инструмент, который позволяет справиться со всеми препятствиями с помощью одного инструмента. Их формула для парсинга любого веб-сайта: более 40 миллионов прокси-серверов для жилых помещений и центров обработки данных + мощный веб-парсер = API для веб-скрапинга. Этот инструмент гарантирует, что вы получите необходимые данные в виде необработанного HTML-кода со 100-процентной вероятностью успеха.
С помощью API для web - парсинга вы можете собирать данные в режиме реального времени из любого города по всему миру. Вы можете положиться на этот инструмент даже при парсинге web-сайтов, созданных с помощью JavaScript, и не столкнётесь ни с какими препятствиями. Кроме того, Smartproxy предлагает четыре других парсера, которые удовлетворят все ваши потребности: парсинг электронной коммерции, поисковой выдачи, социальных сетей и парсер без кода, который позволяет собирать данные даже тем, кто не умеет программировать.
Но прежде чем использовать Smartproxy или любой другой инструмент, вы должны знать, что такое web - парсинг и как он осуществляется. Давайте разберёмся, что такое web - парсинг и как его использовать для получения данных с других сайтов.
Что такое web - парсинг?
Web - парсинг — это автоматический метод получения больших объёмов данных с web-сайтов. Большая часть этих данных представляет собой неструктурированные данные в формате HTML, которые затем преобразуются в структурированные данные в электронной таблице или базе данных, чтобы их можно было использовать в различных приложениях. Существует множество различных способов web - парсинга для получения данных с веб-сайтов. К ним относятся использование онлайн-сервисов, конкретных API или даже создание собственного кода для web - парсинга с нуля. Многие крупные веб-сайты, такие как Google, Twitter, Facebook, StackOverflow и т. д., имеют API, которые позволяют получать доступ к их данным в структурированном формате. Это лучший вариант, но есть и другие сайты, которые не позволяют пользователям получать доступ к большим объёмам данных в структурированной форме или просто не так технологически продвинуты. В такой ситуации лучше всего использовать web - парсинг для сбора данных с веб-сайта.
Для web - парсинга требуются две составляющие, а именно краулер и скрейпер. Краулер — это алгоритм искусственного интеллекта, который просматривает веб-страницы в поисках необходимых данных, переходя по ссылкам в интернете. Скрейпер, с другой стороны, — это специальный инструмент, созданный для извлечения данных с веб-сайта. Дизайн скрейпера может сильно различаться в зависимости от сложности и масштаба проекта, чтобы он мог быстро и точно извлекать данные.
Как работают веб-скрайперы?
Веб-скраперы могут извлекать все данные с определенных сайтов или конкретные данные, которые нужны пользователю. В идеале лучше всего указать нужные данные, чтобы веб-скрапер быстро извлекал только их. Например, вы можете захотеть извлечь данные о доступных соковыжималках со страницы Amazon, но вам могут понадобиться только данные о моделях различных соковыжималок, а не отзывы покупателей.
Итак, когда веб-скраперу нужно очистить сайт, сначала указываются URL-адреса. Затем он загружает весь HTML-код этих сайтов, а более продвинутый скрапер может даже извлечь все элементы CSS и Javascript. Затем скрапер получает необходимые данные из этого HTML-кода и выводит их в формате, указанном пользователем. Чаще всего это таблица Excel или CSV-файл, но данные могут быть сохранены и в других форматах, например в файле JSON.
Типы веб-скрайперов
Веб-скраперы можно разделить на множество категорий по разным критериям, в том числе на самодельные или готовые веб-скраперы, расширения для браузеров или программные веб-скраперы, а также облачные или локальные веб-скраперы.
Вы можете использовать самодельные веб-скраперы, но для этого требуются продвинутые знания в области программирования. А если вы хотите, чтобы ваш веб-скрапер обладал дополнительными функциями, то вам понадобятся еще более глубокие знания. С другой стороны, готовые веб-скраперы — это ранее созданные скраперы, которые вы можете легко скачать и запустить. У них также есть более продвинутые функции, которые вы можете настроить.
Веб-скраперы для браузеров— это расширения, которые можно добавить в ваш браузер. Они просты в использовании, так как интегрированы с вашим браузером, но в то же время из-за этого они ограничены. Любые расширенные функции, выходящие за рамки возможностей вашего браузера, невозможно использовать с веб-скраперами для браузеров. Но программные веб-скраперы не имеют таких ограничений, так как их можно скачать и установить на ваш компьютер. Они сложнее, чем веб-скраперы для браузеров, но у них также есть расширенные функции, которые не ограничены возможностями вашего браузера.
Облачные веб-скраперы работают в облаке, то есть на удалённом сервере, который в основном предоставляет компания, у которой вы покупаете скрапер. Это позволяет вашему компьютеру сосредоточиться на других задачах, так как для сбора данных с веб-сайтов не требуются ресурсы компьютера. Локальные веб-скраперы, с другой стороны, работают на вашем компьютере, используя локальные ресурсы. Поэтому, если веб-скраперам требуется больше ресурсов процессора или оперативной памяти, ваш компьютер будет работать медленнее и не сможет выполнять другие задачи.
Почему Python является популярным языком программирования для веб-скрапинга?
Python, похоже, в наши дни в моде! Это самый популярный язык для веб-скрапинга, так как он легко справляется с большинством процессов. В нём также есть множество библиотек, созданных специально для веб-скрапинга. Scrapy — это очень популярный фреймворк для веб-скрапинга с открытым исходным кодом, написанный на Python. Он идеально подходит для веб-скрапинга, а также для извлечения данных с помощью API. Beautiful soup — ещё одна библиотека Python, которая отлично подходит для веб-скрапинга. Он создаёт дерево синтаксического анализа, которое можно использовать для извлечения данных из HTML-кода на веб-сайте. В Beautiful Soup также есть несколько функций для навигации, поиска и изменения этих деревьев синтаксического анализа.
Для чего используется веб-скрапинг?
Веб-скрапинг имеет множество применений в различных отраслях. Давайте рассмотрим некоторые из них!
1. Мониторинг цен
Веб-скрапинг может использоваться компаниями для сбора данных о своих продуктах и продуктах конкурентов, а также для того, чтобы понять, как это влияет на их стратегии ценообразования. Компании могут использовать эти данные для установления оптимальных цен на свои продукты, чтобы получать максимальный доход.
2. Маркетинговые исследования
Веб-скрапинг может использоваться компаниями для исследования рынка. Качественные данные, полученные в больших объёмах с помощью веб-скрапинга, могут быть очень полезны для компаний при анализе потребительских тенденций и понимании того, в каком направлении им следует двигаться в будущем.
3. Мониторинг новостей
Веб-скрапинг новостных сайтов может предоставить компании подробные отчёты о текущих новостях. Это особенно важно для компаний, которые часто попадают в новости или зависят от ежедневных новостей в своей повседневной деятельности. В конце концов, новостные репортажи могут спасти или погубить компанию за один день!
4. Анализ настроений
Если компании хотят понять общее отношение потребителей к их продуктам, то анализ настроений просто необходим. Компании могут использовать веб-скрапинг для сбора данных из социальных сетей, таких как Facebook и Twitter, о том, каково общее отношение к их продуктам. Это поможет им создавать продукты, которые будут востребованы, и опережать конкурентов.
5. Маркетинг по электронной почте
Компании также могут использовать веб-скрапинг для маркетинга по электронной почте. Они могут собирать адреса электронной почты с различных сайтов с помощью веб-скрапинга, а затем отправлять массовые рекламные и маркетинговые электронные письма всем владельцам этих адресов.
- Информация о материале
- Категория: Data Sciense
- Просмотров: 10